
说明
Linux环境下进程发生异常而挂掉,通常很难查找原因,但是一般Linux内核给我们提供的核心文件,记录了进程在崩溃时候的信息。可以参考以下方式获取coredump
热加载方式生成coredump
1.通过grep命令查找到对应的BE进程
ps aux| grep 'lib/starrocks_be'

2.执行prlimit -p 热加载的方式进行core文件的开启
sudo prlimit -p $bePID --core=unlimited:unlimited
3.查看对应的BE进程确认core文件大小限制是否为unlimited
cat /proc/$bePID/limits
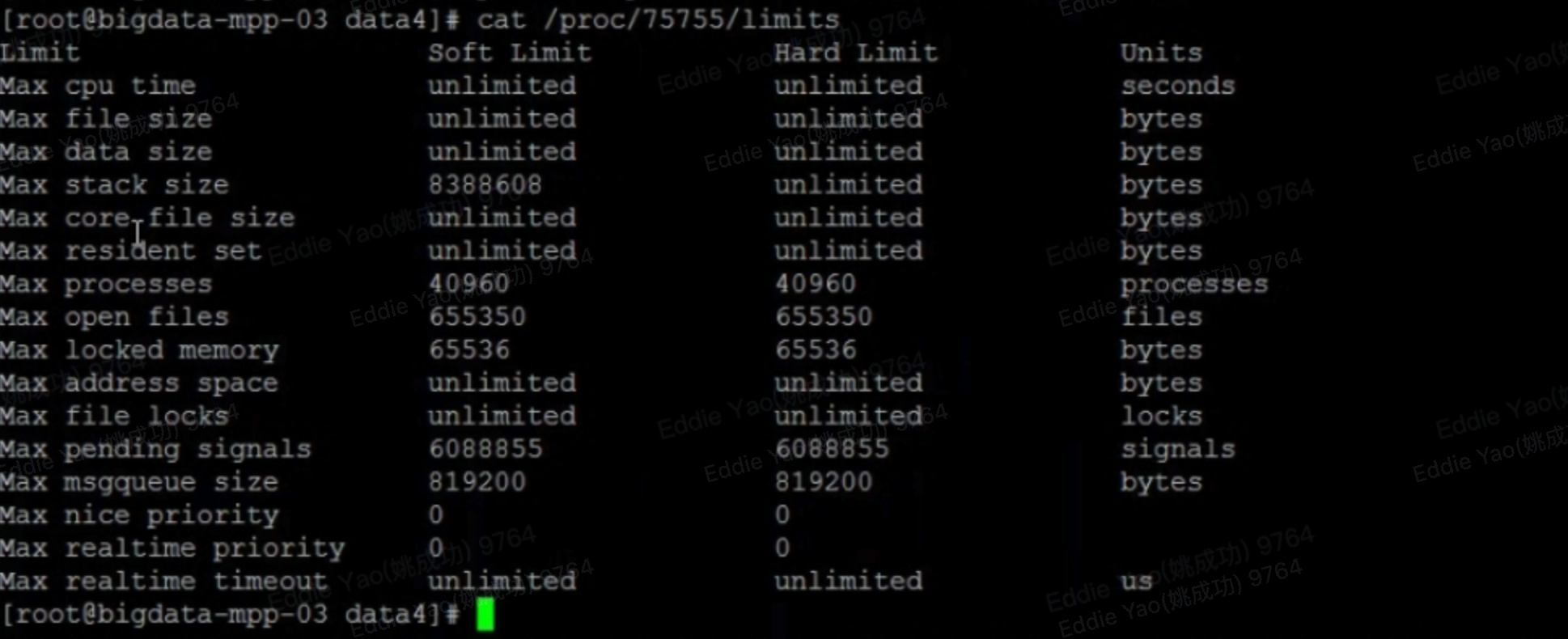
不为0的话进程崩溃会在be部署根目录下生成一个core文件。
指定生成文件的路径和名字;执行# vim /etc/sysctl.conf,进入编辑模式,加入下面两行
kernel.core_pattern=/tmp/core_%e_%p
kernel.core_uses_pid=0
sysctl -p /etc/sysctl.conf,是修改马上生效。
4.core_pattern的命名规则:
%c 转储文件的大小上限
%e 所dump的文件名
%g 所dump的进程的实际组ID
%h 主机名 %p 所dump的进程PID
%s 导致本次coredump的信号
%t 转储时刻(由1970年1月1日起计的秒数)
%u 所dump进程的实际用户ID