为了更快的定位您的问题,请提供以下信息,谢谢
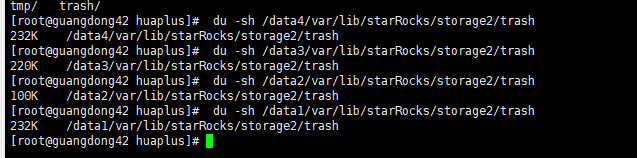
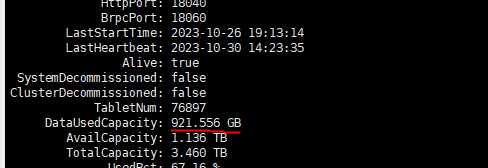
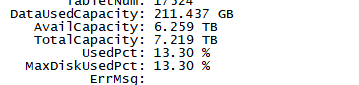
【详述】starrocks be多目录存储 用 du -sh 数据目录 查看的数据大小比 show backends看到的DataUsedCapacity数据统计信息大两倍不止,集群每个节点真实数据量再910-950G左右,du -sh查看基本都在2.1-2.2T。另一个数据量少的集群也是be多目录存储,du -sh看有56G左右用show backends 只有不到20G 。在其他be单目录存储的集群中统计指标show bakends看到的和实际占用存储相差不大,show backends看到的信息属于正常延迟的,集群每天的数据量相差不大,四月份开始入库的,很早就有这个问题了,感觉多目录存储不像是统计延迟
【背景】routine load 拉取kafka数据
【业务影响】
【StarRocks版本】集群经历过2.5.6–>2.5.10–>3.1.12–>3.1.2,都有这个问题
【集群规模】例如:5fe(4 follower+1observer)+7be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【联系方式】为了在解决问题过程中能及时联系到您获取一些日志信息,请补充下您的联系方式,例如:社区群4-小李或者邮箱,谢谢
【附件】
- fe.log/beINFO/相应截图
be多目录集群一截图
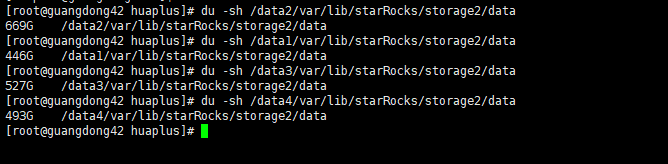
be多目录集群二截图
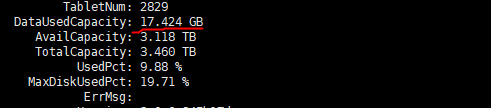
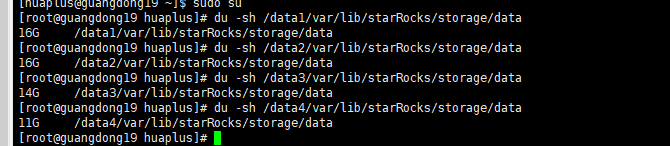
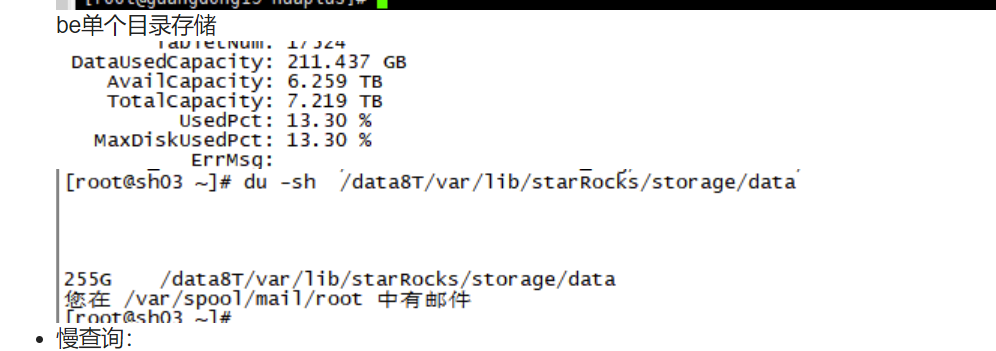
be单个目录存储

- 慢查询:
- Profile信息,获取Profile,通过Profile分析查询瓶颈
- 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
- pipeline是否开启:show variables like ‘%pipeline%’;
- be节点cpu和内存使用率截图
- 查询报错:
- query_dump,怎么获取query_dump文件
- be crash
- be.out
- coredump,如何获取coredump
- 外表查询报错
- be.out和fe.warn.log