为了更快的定位您的问题,请提供以下信息,谢谢
【详述】早上6.34收到告警,主节点的fe服务异常挂起,但其他节点的fe正常且本机的be节点正常。想知道什么原因造成的,求助
【背景】发现告警后第一时间联系值班人员,命令行重新启动了原来的fe服务,现在是从节点了。
【业务影响】处理的早,并没有影响业务。
【是否存算分离】
【StarRocks版本】例如:3.4.2
【集群规模】例如:3fe(1 follower+2follower)+3be(fe与be混部)
【机器信息】三台虚拟机都是8C/16G的
【联系方式】为了在解决问题过程中能及时联系到您获取一些日志信息,请补充下您的联系方式,例如:WX:XJP19801879168
【附件】fe.gc.log.20250520-065030 (525.9 KB) fe.gc.log.20250520-064926 (21.3 KB) fe.out (248.6 KB) fe.warn.log (80.1 KB)
- fe.log/beINFO/相应截图
- 慢查询:
- Profile信息,获取Profile,通过Profile分析查询瓶颈
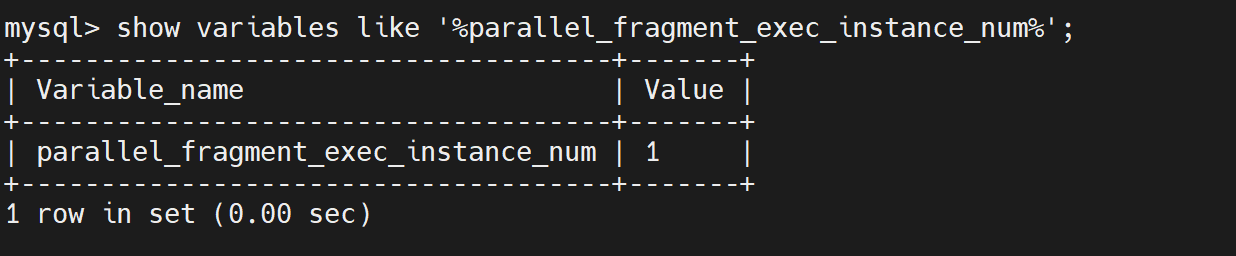
- 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
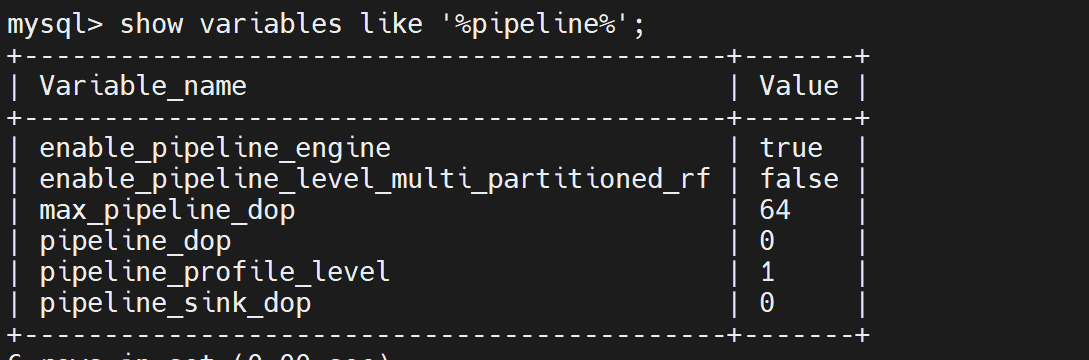
- pipeline是否开启:show variables like ‘%pipeline%’;
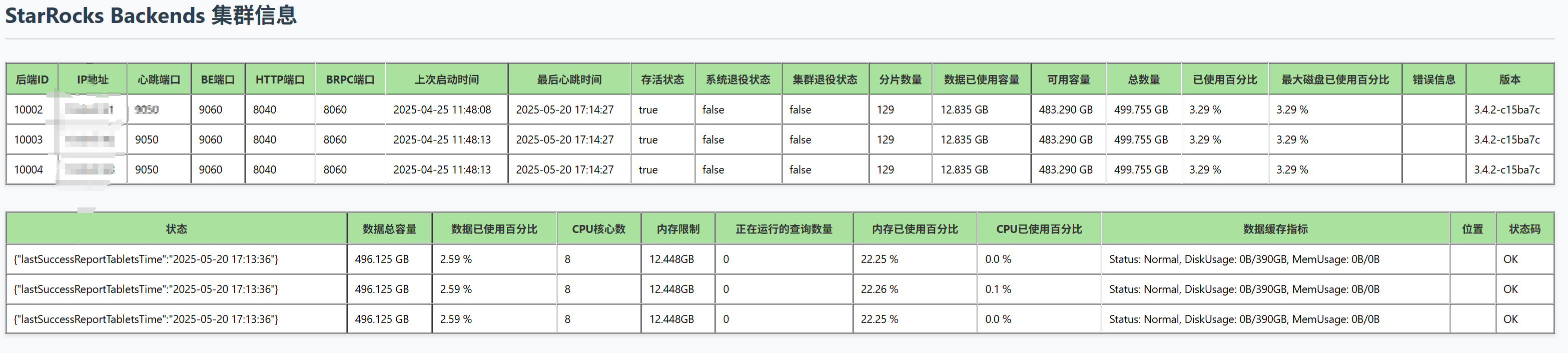
- be节点cpu和内存使用率截图
- 查询报错:
- query_dump,怎么获取query_dump文件
- be crash
- be.out
- coredump,如何获取coredump
- 外表查询报错
- be.out和fe.warn.log