为了更快的定位您的问题,请提供以下信息,谢谢
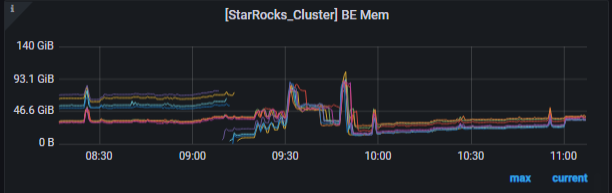
【详述】be内存泄漏,有的be节点在晚空闲期间(几乎没有查询和导入)依然占用60G内存未释放,正常be节点只有cache 内存占用
最后重启释放内存
重启前
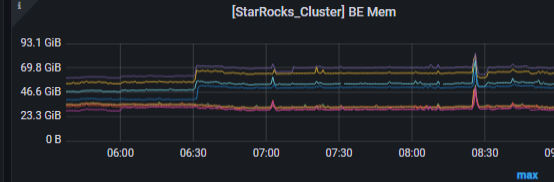
重启后,09:12分左右重启有内存泄漏的节点
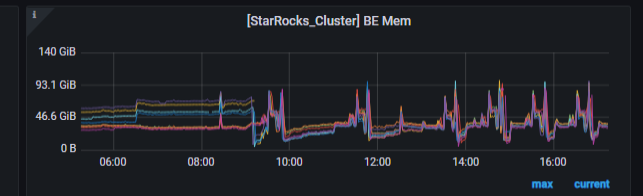
通过
curl -XGET -s http://ip:httpport/metrics | grep “^starrocks_be_.*_mem_bytes|^starrocks_be_tcmalloc_bytes_in_use”
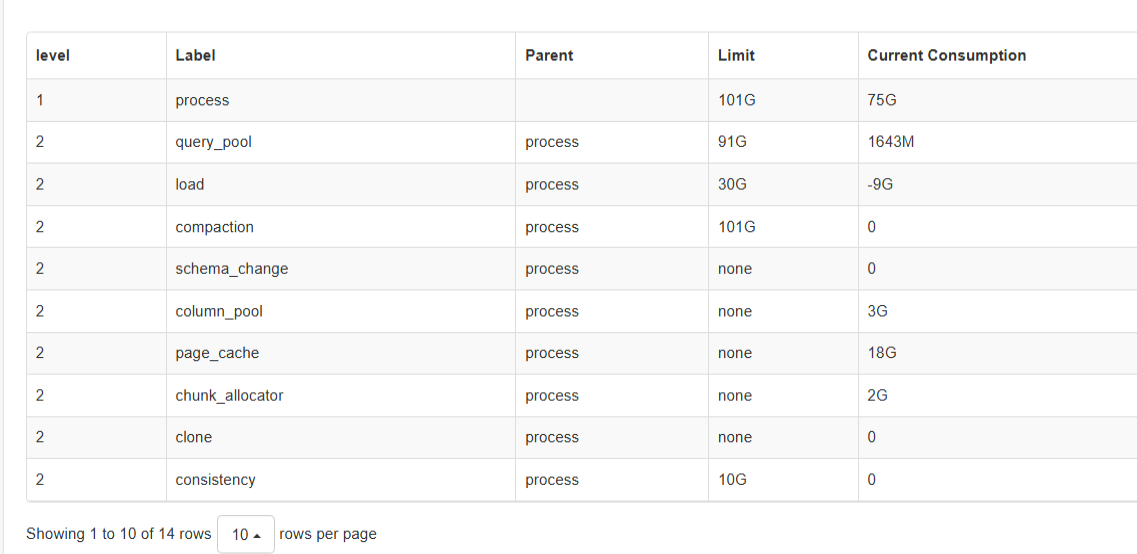
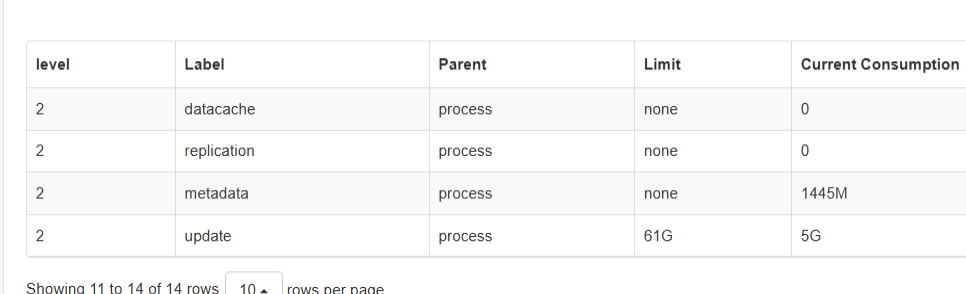
排查出占用内存多的节点 load_mem_bytes异常高
http://ip:httpport/mem_tracker?type=load&upper_level=5
发现 load_mem_bytes异常高的节点 load 3级 lable很多一万多个,正常的节点二千多个


【背景】做过哪些操作?
【业务影响】查询be内存木桶效应
【是否存算分离】 否
【StarRocks版本】例如:3.1.14
【集群规模】例如:6fe(5 follower+1observer)+8be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【联系方式】为了在解决问题过程中能及时联系到您获取一些日志信息,请补充下您的联系方式,例如:社区群4-小李或者邮箱,谢谢
【附件】
starrocks
- be.warning
be.WARNING.txt (122.0 KB) - fe.log/beINFO/相应截图
- 慢查询:
- Profile信息,获取Profile,通过Profile分析查询瓶颈
- 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
- pipeline是否开启:show variables like ‘%pipeline%’;
- be节点cpu和内存使用率截图
- 查询报错:
- query_dump,怎么获取query_dump文件
- be crash
- be.out
- coredump,如何获取coredump
- 外表查询报错
- be.out和fe.warn.log