
一、监控告警方案
StarRocks社区推荐的开源监控方案是Prometheus+Grafana。StarRocks提供了兼容Prometheus的信息采集接口,Prometheus可以通过连接BE/FE的HTTP端口来获取集群监控指标的metric信息,存储在自身的时序数据库中。Grafana则可以将Prometheus作为数据源来进行图形化展现。搭配StarRocks提供的Dashboard模板,开发者能够便捷的实现StarRocks集群监控指标的统计展示和阈值告警。
StarRocks社区仅提供基于Prometheus和Grafana实现的一种StarRocks可视化监控方案,原则上不维护和开发这些组件,更多详细的关于Prometheus和Grafana的介绍和使用,请参考对应的官方文档。
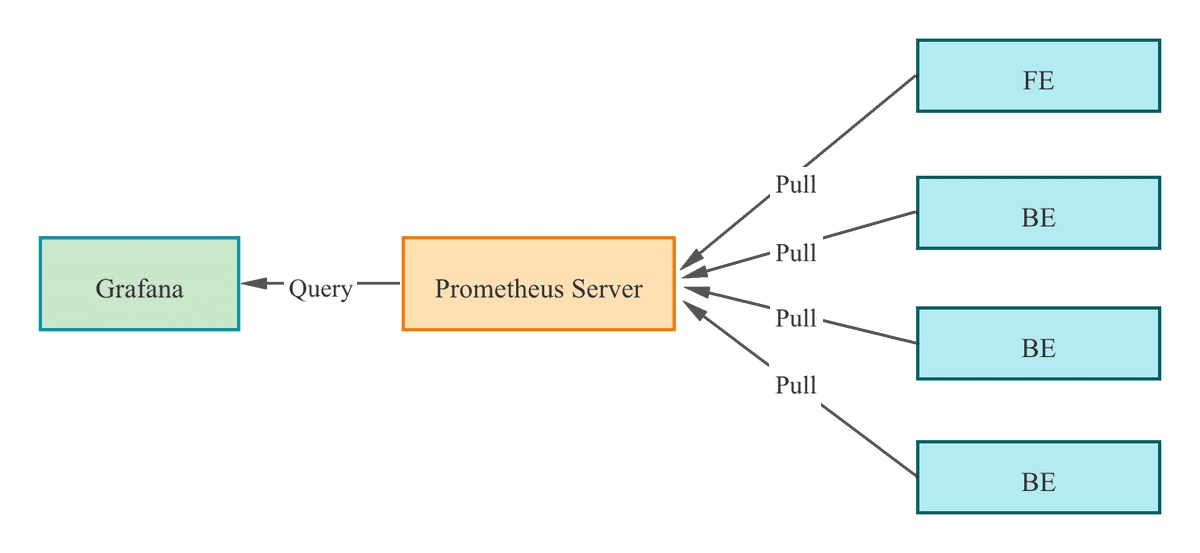
下文的内容按照“监控安装–>核心监控项–>配置邮件告警”三个部分展开。
二、监控组件安装
Prometheus和Grafana的端口默认不与StarRocks冲突,但生产集群仍建议将监控组件单独部署,以此减少服务资源占用冲突,同时规避混部下该服务器异常宕机时外部无法及时感知的风险。
此外,Prometheus+Grafana是无法监控自身服务的存活状态的,生产环境中我们通常还会搭配supervisor做保活处理,这里暂不展开。
本次假设我们在中控节点(192.168.110.23)使用root用户部署监控组件,对下面的StarRocks集群进行监控(StarRocks集群使用默认端口)。在我们参考该指南为自己的集群配置监控时,通常只需替换IP:
| Host | IP | 用户 | 部署服务 |
|---|---|---|---|
| node01 | 192.168.110.101 | root | 1FE+1BE |
| node02 | 192.168.110.102 | root | 1FE+1BE |
| node03 | 192.168.110.103 | root | 1FE+1BE |
说明:Prometheus+Grafana当前只能监控StarRocks的FE和BE,不能监控Broker。
2.1 Prometheus部署
2.1.1 Prometheus下载
Prometheus的下载网址为:
StarRocks只需要使用Prometheus的Server安装包,以LTS版本2.45.0为例,直接点击下载:
或者复制链接使用wget下载:
[root@manager opt]# wget https://github.com/prometheus/prometheus/releases/download/v2.45.0/prometheus-2.45.0.linux-amd64.tar.gz
不论采用哪种下载方式,在下载完成后,我们将安装包上传或拷贝至manager节点的/opt目录下。
2.1.2 Prometheus配置
1)切换至/opt目录:
[root@manager ~]# cd /opt
2)解压安装包:
[root@manager opt]# tar xvf prometheus-2.45.0.linux-amd64.tar.gz
3)为方便后续程序升级,将解压后的目录重命名为prometheus:
[root@manager opt]# mv prometheus-2.45.0.linux-amd64 prometheus
4)创建数据存放目录:
[root@manager opt]# mkdir prometheus/data
5)prometheus官方只提供了二进制文件tar包,为了方便管理,我们可以创建prometheus系统服务启动文件:
[root@manager opt]# vim /etc/systemd/system/prometheus.service
输入:
[Unit]
Description=Prometheus service
After=network.target
[Service]
User=root
Type=simple
ExecReload=/bin/sh -c "/bin/kill -1 `/usr/bin/pgrep prometheus`"
ExecStop=/bin/sh -c "/bin/kill -9 `/usr/bin/pgrep prometheus`"
ExecStart=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml --storage.tsdb.path=/opt/prometheus/data --storage.tsdb.retention.time=30d --storage.tsdb.retention.size=30GB
[Install]
WantedBy=multi-user.target
保存退出。
说明:当使用其他目录部署时,注意ExecStart命令中的目录需要同步修改一致。此外,在启动参数中我们还配置了Prometheus中数据存储的过期条件为“30天”或“大于30GB”,可以按需修改。
6)修改prometheus配置文件prometheus/prometheus.yml,这个文件中的配置内容对格式要求比较严格,修改时需要特别注意空格和缩进。或者我们可以将原始配置文件重命名,然后粘贴下发需用的内容。
修改原配置文件文件名:
[root@manager opt]# mv prometheus/prometheus.yml prometheus/prometheus_bak.yml
使用StarRocks集群信息创建配置文件prometheus.yml:
[root@manager opt]# vim prometheus/prometheus.yml
输入:
global:
scrape_interval: 15s #全局的采集间隔,默认是1m,这里设置为15s
evaluation_interval: 15s #全局的规则触发间隔,默认是1m,这里设置15s
scrape_configs:
- job_name: 'StarRocks_Cluster01' #每一个集群称之为一个job,可以自定义名字作为StarRocks集群名
metrics_path: '/metrics' #指定获取监控项目的Restful API
static_configs:
- targets: ['192.168.110.101:8030','192.168.110.102:8030','192.168.110.103:8030']
labels:
group: fe #这里配置了FE的group,该group中包含了3个FE节点,需填写各个FE对应的IP和http端口。若部署集群时修改过该端口,这里注意进行调整
- targets: ['192.168.110.101:8040','192.168.110.102:8040','192.168.110.103:8040']
labels:
group: be #这里配置了BE的group,该group中包含了3个BE节点,需填写各个BE对应的IP和http端口。若部署集群时修改过该端口,这里注意进行调整。
在配置文件创建完成后,可使用promtool检查配置文件语法是否合规,例如:
[root@manager opt]# ./prometheus/promtool check config prometheus/prometheus.yml
当看到提示检查通过后,再执行后续操作:
SUCCESS: prometheus/prometheus.yml is valid prometheus config file syntax
7)启动服务:
[root@manager opt]# systemctl daemon-reload
[root@manager opt]# systemctl start prometheus.service
8)查看服务状态:
[root@manager opt]# systemctl status prometheus.service
观察Active: active (running)即为启动成功。
prometheus默认使用的端口为9090,也可以使用netstat命令查看9090端口的状态:
[root@manager opt]# netstat -nltp | grep 9090
9)设置开机启动:
[root@manager opt]# systemctl enable prometheus.service
其他相关命令:
停止服务:systemctl stop prometheus.service
重启服务:systemctl restart prometheus.service
热加载配置:systemctl reload prometheus.service
禁用开机启动:systemctl disable prometheus.service
2.1.3 访问Prometheus
Prometheus可以通过Web页面进行简单的访问。通过浏览器访问其默认的9090端口,即可访问Prometheus的页面。例如,我们使用谷歌浏览器访问192.168.110.23:9090。
在页面中点击导航栏中,Status-->Targets,可以看到配置文件prometheus.yml中所有分组Job的监控主机节点。正常情况下,所有节点都应为UP,表示服务通信正常:
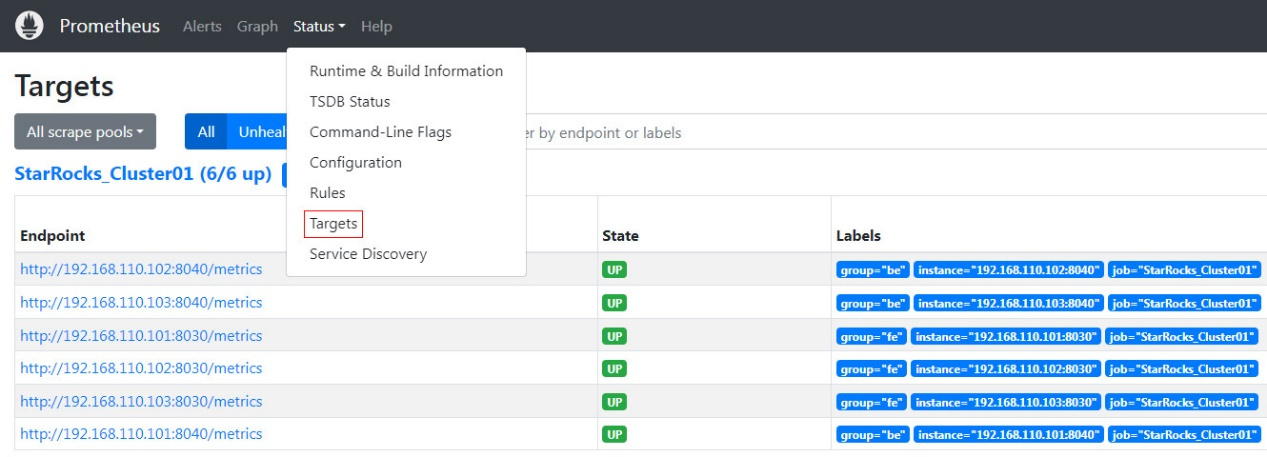
至此,Prometheus就配置完成了,更详细的资料可以参阅Prometheus官方文档:
2.2 Grafana部署
2.2.1 Grafana下载
Grafana下载网址为:
找到适用于CentOS的安装包,官方提供的有rpm包地址,我们直接使用wget语句下载:
[root@manager opt]# wget https://dl.grafana.com/enterprise/release/grafana-enterprise-10.0.3-1.x86_64.rpm
2.2.2 Grafana安装
1)使用yum命令安装,方便自动安装依赖:
[root@manager opt]# yum -y install grafana-enterprise-10.0.3-1.x86_64.rpm
2)启动grafana:
[root@manager opt]# systemctl start grafana-server.service
3)查看状态:
[root@manager opt]# systemctl status grafana-server.service
同样,Active: active (running)表示服务已成功启动。
Grafana默认使用的端口为3000,使用netstat命令验证端口监听状态:
[root@manager opt]# netstat -nltp | grep 3000
4)设置开机自启:
[root@manager opt]# systemctl enable grafana-server.service
5)扩展命令:
关闭服务:systemctl stop grafana-server.service
重启服务:systemctl restart grafana-server.service
禁用开机自启:systemctl disable grafana-server.service
关于Grafana的使用,详见官方文档:
2.2.3 访问Grafana
使用浏览器访问192.168.110.23:3000,即可看到grafana页面,默认用户名密码都是admin,初次登录会提示修改默认的登录密码,若暂时不希望修改密码,可以点击Skip跳过。跳过后即可进入到Grafana主界面:
2.2.4 数据源配置
配置路径为:Administration右侧的展开符号-->Data sources-->Add data source-->Prometheus
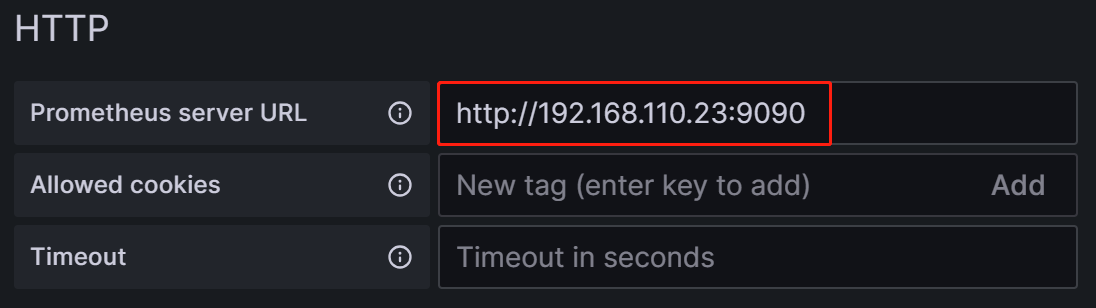
使用我们Prometheus的信息进行配置,需要修改的配置有:
1)Name:数据源的名称,自定义,例如starrocks_monitor:

2)URL:Prometheus的web地址,如我们的http://192.168.110.23:9090
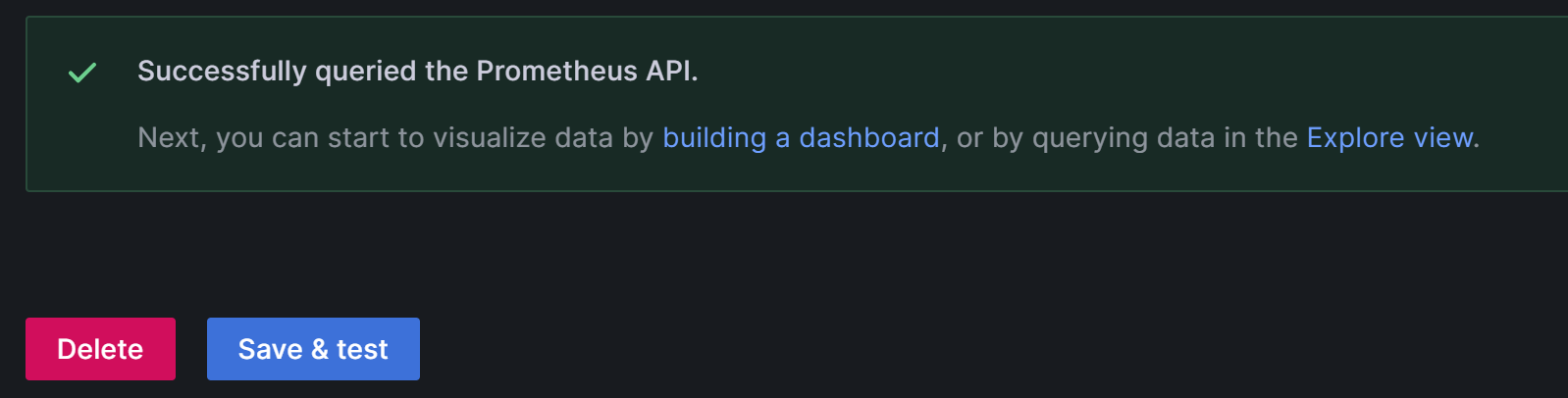
3)完成后单击页面最下放的Save & test,如果显示Successfully queried the Prometheus API,即表示数据源可用:
2.2.5 配置DashBoard
1)下载模板:
StarRocks 2.5版本监控模版的下载地址为:
https://starrocks-thirdparty.oss-cn-zhangjiakou.aliyuncs.com/StarRocks-Overview-2.5.json
浏览器打开下载地址,右键,另存为,在桌面保存即可。这里注意,我们需要将json文件下载到“浏览器所在的机器上”,因为json模板是需要通过浏览器上传的,所以这里不要下载到Linux服务器上,而是需要下载到咱们打开Web所用的机器上。
2)配置模板:
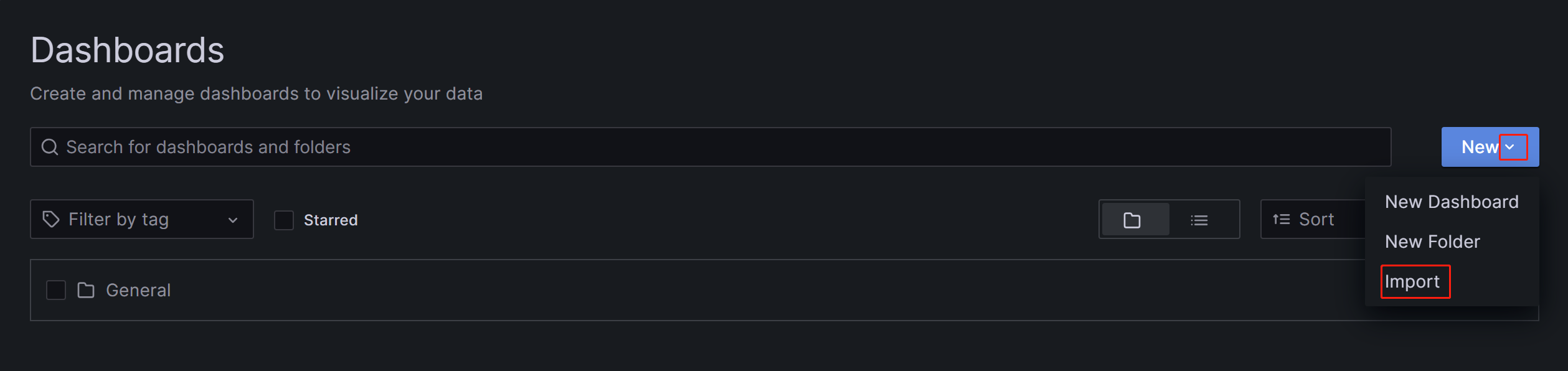
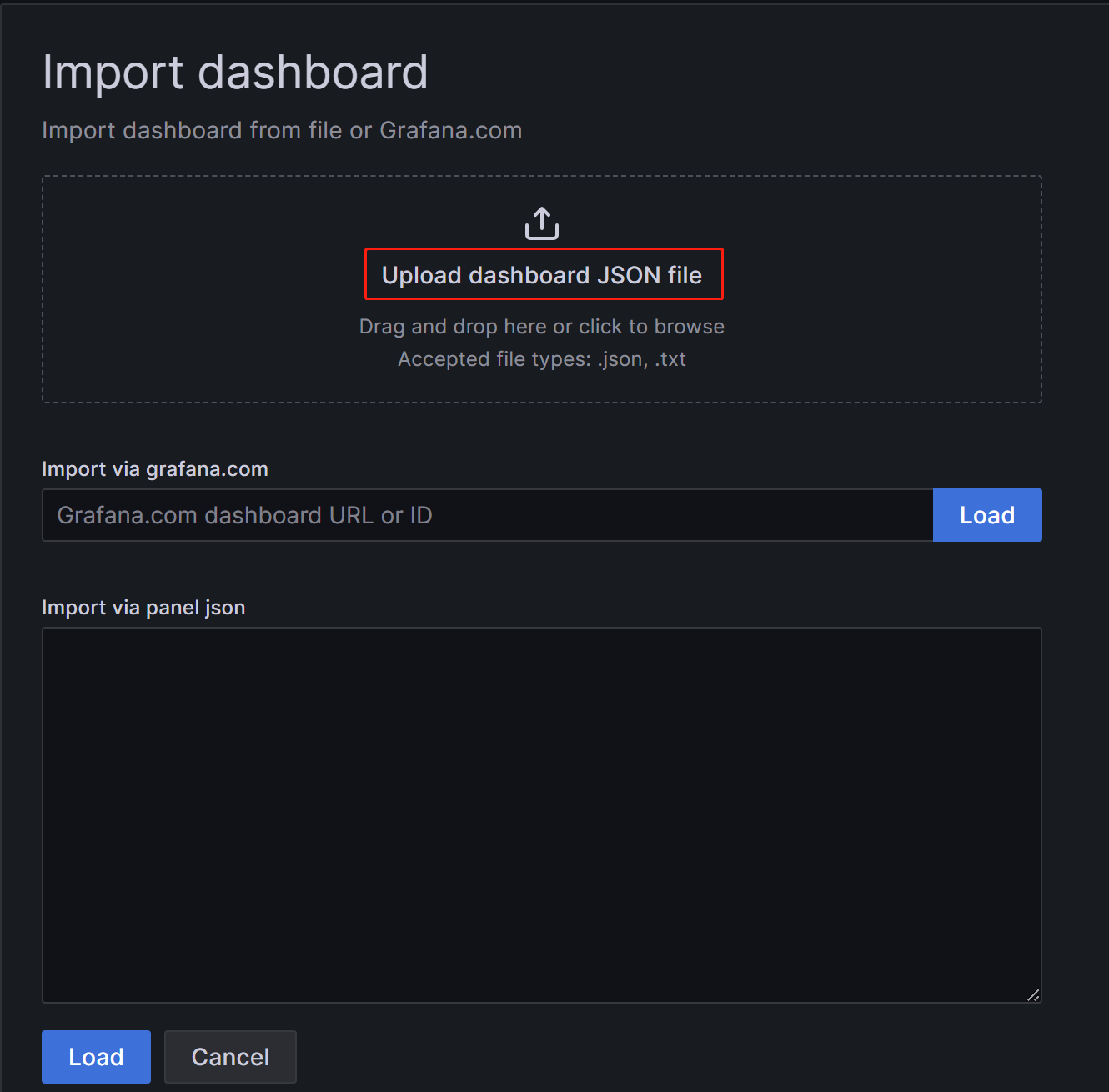
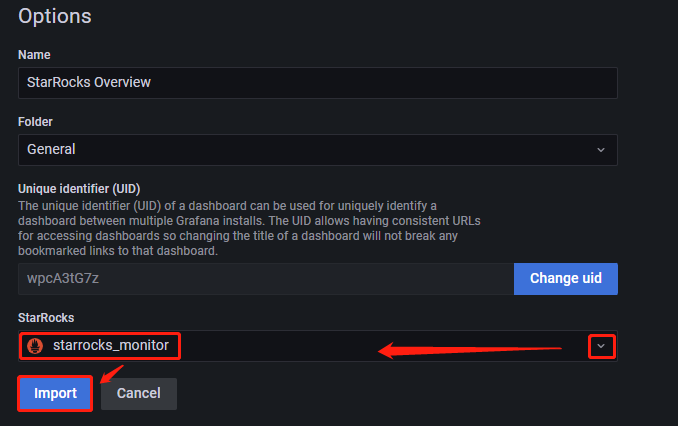
点击目录-->Dashboards-->New右侧的展开符号-->Import-->Upload dashboard JSON file,将下载的json文件导入。导入后,可以命名Dashboard,默认是StarRocks Overview。同时,需要选择数据源,这里选择之前创建的starrocks_monitor。点击Import,即完成导入。之后,可以看到StarRocks的Dashboard展示:
2.2.6 后续访问
关闭浏览器后,如果需要再次进入监控Dashboard,还是在浏览器中访问192.168.110.23:3000,输入用户名密码后,在菜单中点击Dashboards,在General目录选择StarRocks Overview即可:
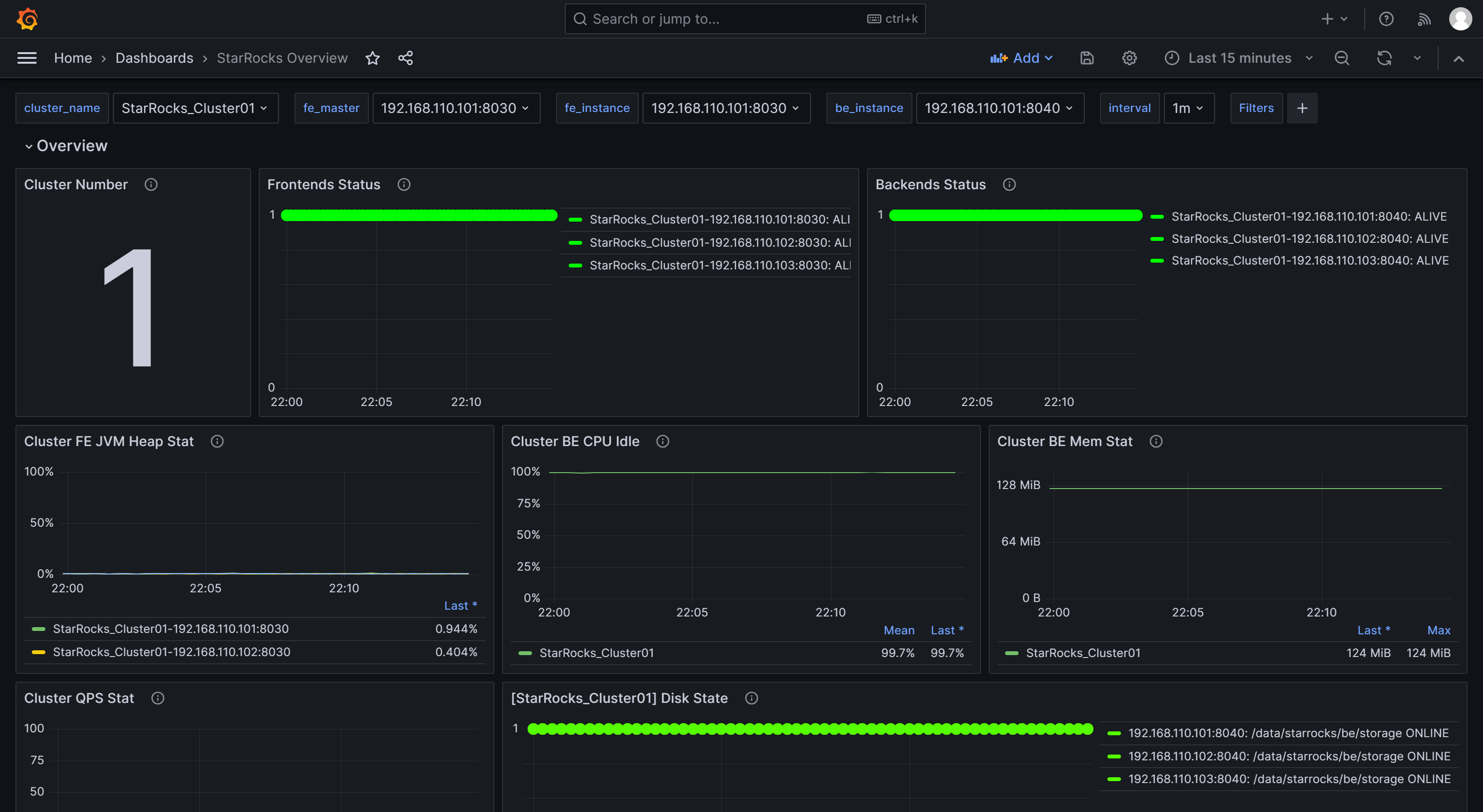
进入监控页面后,可以在页面右上方手动刷新或配置自动刷新Dashboard的时间间隔来观测StarRocks的集群状态:
三、核心监控项
为了满足开发、运维、DBA等同学的多重需求,本次社区整理的监控模版包含了尽可能多的监控指标,每项指标的Description中也添加了尽量清晰的中文说明。但是,指标项过多也导致了社区一些小伙伴不清楚要重点关注的指标是哪些,因此本次一并整理出实际业务中较常用的一些监控告警规则,仅供参考。
3.1 FE/BE状态监控
| 监控项 | 说明 | 告警规则 | 告警说明 | 备注 |
|---|---|---|---|---|
| Frontends Status | FE节点状态,挂掉的FE会显示为0。如果所有FE都是存活状态,则所有点对应的值应都为1。 | (up{group=“fe”})<1 | 所有FE节点状态需均为alive,任一FE节点状态为DEAD都应触发告警。 | FE或BE宕机都属于异常行为,需要及时排查宕机原因。 |
| Backends Status | BE节点状态,挂掉的BE会展示为0。如果所有的BE状态正常,则所有点对应的值应都为1。 | (up{group=“be”})<1 | 所有BE节点状态需均为alive,任一BE节点状态为DEAD都应触发告警。 |
3.2 查询失败监控
| 监控项 | 说明 | 告警规则 | 告警说明 | 备注 |
|---|---|---|---|---|
| Query Error | 每分钟失败的查询率,包括timeout。其值即为一分钟内失败的查询语句条数除以60s。 | rate(starrocks_fe_query_err{job="$cluster_name"}[1m])>0.05 | 结合业务实际的QPS来配置,初步可将告警失败率阈值设置在5%左右,后续再调整。 | 失败的查询一天不应该有太多次,阈值5%即每分钟最多允许失败3条SQL。若出现报警,可排查资源占用情况或合理配置超时时间。 |
3.3 外部感知失败监控
| 监控项 | 说明 | 告警规则 | 告警说明 | 备注 |
|---|---|---|---|---|
| Schema Change | Schema Change失败的速率。 | irate(starrocks_be_engine_requests_total{job="$cluster_name", type=“create_rollup”, status=“failed”}[1m])>0 | 是较低频的操作,配置为有失败就报警。 | 一般不应该失败,触发报警后通常可调大变更表操作可用的内存上限,默认为2G。 |
3.4 内部操作失败监控
| 监控项 | 说明 | 告警规则 | 告警说明 | 备注 |
|---|---|---|---|---|
| BE Compaction Score | 所有BE最大的compaction score,表示当前compaction压力。 | starrocks_fe_tablet_max_compaction_score{job="$cluster_name", instance="$fe_master"}>800 | 通常离线场景,该值小于100,但当有大量导入任务存在时,compaction score会有明显增高,通常大于800的时候需要干预。 | 正常Score大于1000时就会报错Too many versions,此时可以调低导入并发和导入频率。 |
| Clone | BE的clone任务失败的速率。 | irate(starrocks_be_engine_requests_total{job="$cluster_name", type=“clone”, status=“failed”}[1m])>0 | 一般认为不会失败,有失败就报警。 | BE克隆失败告警,通常可检查BE状态、磁盘状态、网络状态。 |
3.5 服务可用性监控
| 监控项 | 说明 | 告警规则 | 告警说明 | 备注 |
|---|---|---|---|---|
| Meta Log Count | fe bdb元数据log条数 | starrocks_fe_meta_log_count{job="$cluster_name"}>100000 | 监控>10w就告警 | FE Leader默认超过50000条会触发checkpoint进行落盘。该值若远超5W,通常代表checkpoint失败,可排查fe.conf中的Xmx堆内存配置是否合理。 |
3.6 机器过载监控项
| 监控项 | 说明 | 告警规则 | 告警说明 | 备注 |
|---|---|---|---|---|
| BE CPU Idle | BE CPU空闲率。 | (sum(rate(starrocks_be_cpu{mode=“idle”, job="$cluster_name"}[$interval])) by (job, instance)) / (sum(rate(starrocks_be_cpu{job="$cluster_name"}[$interval])) by (job, instance)) * 100 < 10 | <10%,持续30s就告警 | 该项主要用于监测CPU资源瓶颈。CPU的波动性比较大,统计间隔太小会导致误报。该项需结合业务实际情况调整,若确实存在多个大任务的跑批或较多的查询,可继续调低该阈值。 |
| BE Mem | 各个BE节点的内存使用情况。 | starrocks_be_process_mem_bytes{job="$cluster_name"}>0.9 | 没有单独百分比的metric,可根据BE服务器物理内存大小,阈值取BE可用内存的90% | 该值与Process Mem取值相同,BE默认内存上限为be.conf中的mem_limit=90%,即BE所在服务器内存的90%,在混部其他服务时注意调整,避免OOM。而告警阈值则需要设为在这个上限基础上再乘以90%,来确认BE内存资源是否已达到瓶颈。 |
| Disks Avail Capacity | 各BE节点本地磁盘容量可用比例(百分比)。 | avg(starrocks_be_disks_avail_capacity/starrocks_be_disks_total_capacity{job=’$cluster_name’}) by (instance)<0.2 | 剩余可用空间不能<20% | 磁盘通常可以根据数据日增量预留个一年/半年的容量。 |
| FE JVM Heap Stat | StarRocks集群各个FE的JVM堆内存使用百分比。 | sum(jvm_heap_size_bytes{group=“fe”, type=“used”} * 100) by (instance, job) / sum(jvm_heap_size_bytes{group=“fe”, type=“max”}) by (instance, job)>80 | 值>=80%告警 | 堆内存报警后建议调大fe.conf中的Xmx堆内存,否则容易影响查询效率或出现FE OOM。 |
四、配置邮件告警
4.1 配置SMTP服务
Grafana支持配置钉钉、邮件、Webhook等多种告警方案,本次我们以通用性较好的邮件告警举例。
邮件告警首先需要在Grafana中配置SMTP信息来用于“邮件发送”。我们常用的邮箱都支持开启SMTP服务,开启服务以及获取授权码的操作不复杂,网上也有详细的教程,这里不再展开。
以网易163邮箱为例,在部署Grafana的节点上,修改Grafana配置文件:
[root@manager ~]# vim /usr/share/grafana/conf/defaults.ini
使用我们的SMTP信息,修改对应的配置,例如:
###################### SMTP / Emailing #####################
[smtp]
enabled = true
# 网易邮箱host配置:smtp.163.com:25
# QQ邮箱host配置:smtp.qq.com:587
host = smtp.163.com:25
user = wumenglongd@163.com
# If the password contains # or;you have to wrap it with triple quotes.Ex """#password;"""
password = ABCDEFGHIJKLMNOP ## 指开启邮箱SMTP后获取到的授权密码
cert_file =
key_file =
skip_verify = true ## Verify SSL for SMTP server
from_address = wumenglongd@163.com ## Address used when sending out emails
from_name = Grafana
ehlo_identity =
startTLS_policy =
[emails]
welcome_email_on_sign_up = false
templates_pattern = emails/*.html, emails/*.txt
content_types = text/html
配置完成后,重启Grafana服务:
[root@manager ~]# systemctl daemon-reload
[root@manager ~]# systemctl restart grafana-server.service
4.2 创建告警渠道
Grafana中通过配置告警渠道来让我们选择告警触发时通知联系人的方式。点击菜单->Alerting右侧的展开符号->Contact Points->Add contact point,在Contact points页面点击Add contact point按钮创建新的告警渠道:
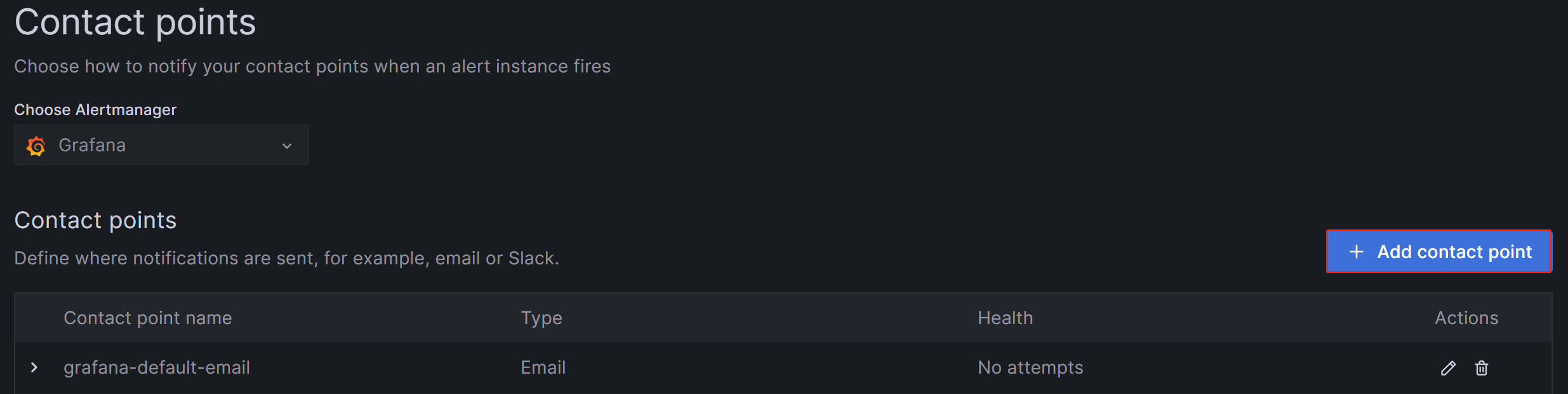
在Name栏中自定义告警渠道的名称,例如我们填入“StarRocks开发组”。在Integration下拉框中,我们选择通知方式为“Email”:
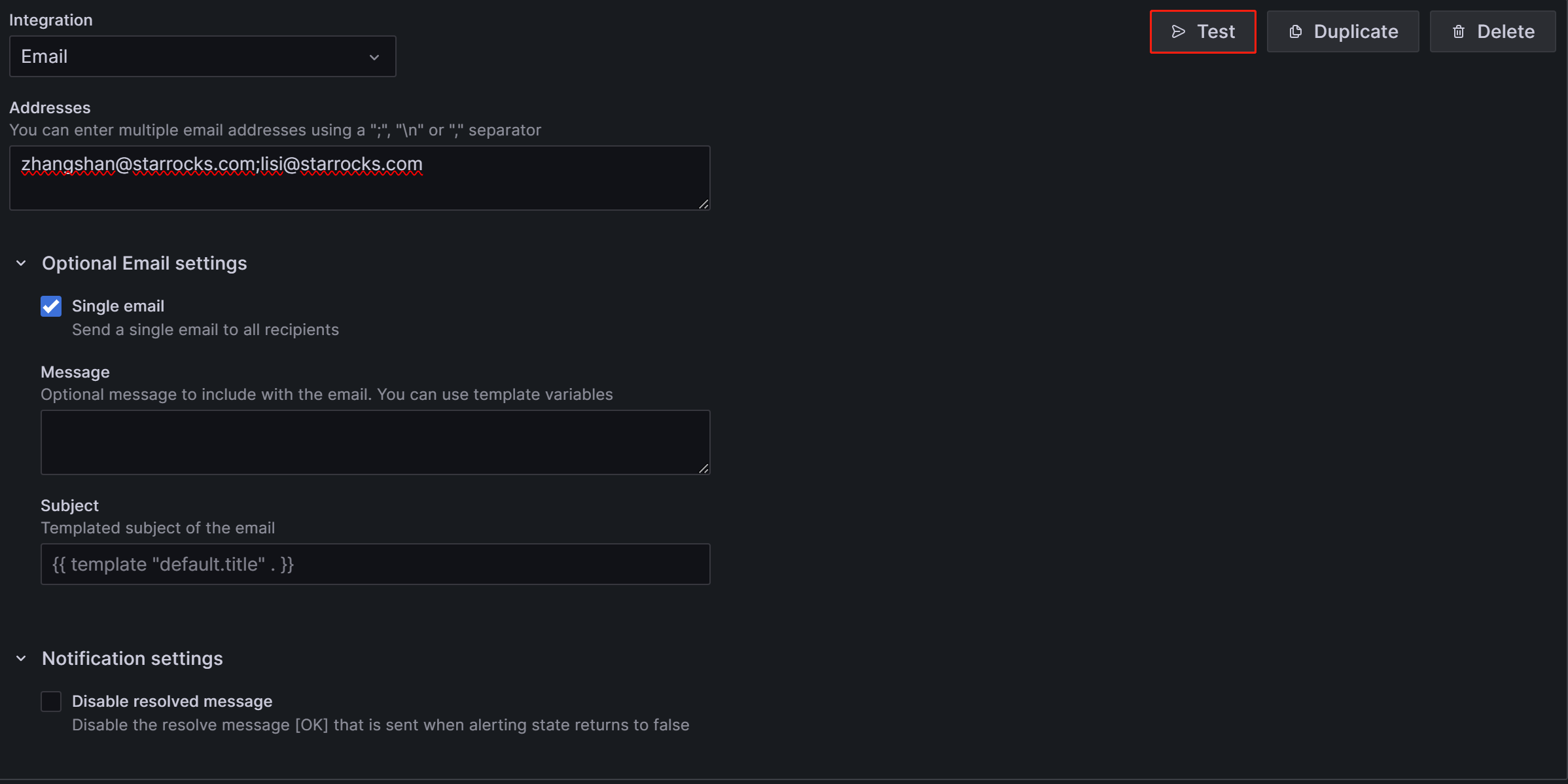
在Addresses中输入目标告警人的邮箱地址,这里的邮箱与我们在上文配置的SMTP信息中的邮箱厂商没有绑定关系,我们可以使用任意邮箱来接收告警邮件,但邮件的发件人都为SMTP中from_address处配置的邮箱。
当邮件收件人为多个时,各个收件人之间可以用英文分号,英文逗号或者回车换行分割。
页面中剩余的配置前期都可先使用默认值,需要稍微注意的是“Single email”和“Disable resolved message”这两个选项:
1)“Single email”选项:在勾选后,当目标收件人是多个时,告警邮件会通过一封邮件发出,而不是多封。通常建议勾选。
2)“Disable resolved message”选项:在默认情况下,当告警涉及的项恢复时,例如FE宕掉触发了告警,我们已手动启动FE恢复服务后,Grafana会再发送一次告警提示服务恢复,若不需要这个恢复提示,可以勾选该选项禁用。通常不建议禁用。
配置完成后,可以点击图片右上方的“Test”按钮,再点击弹出框中的“Sent test notification”按钮,若上文的SMTP服务和Addresses配置都正确,目标邮箱中就可以收到标题为“TestAlert Grafana”的提示邮件:
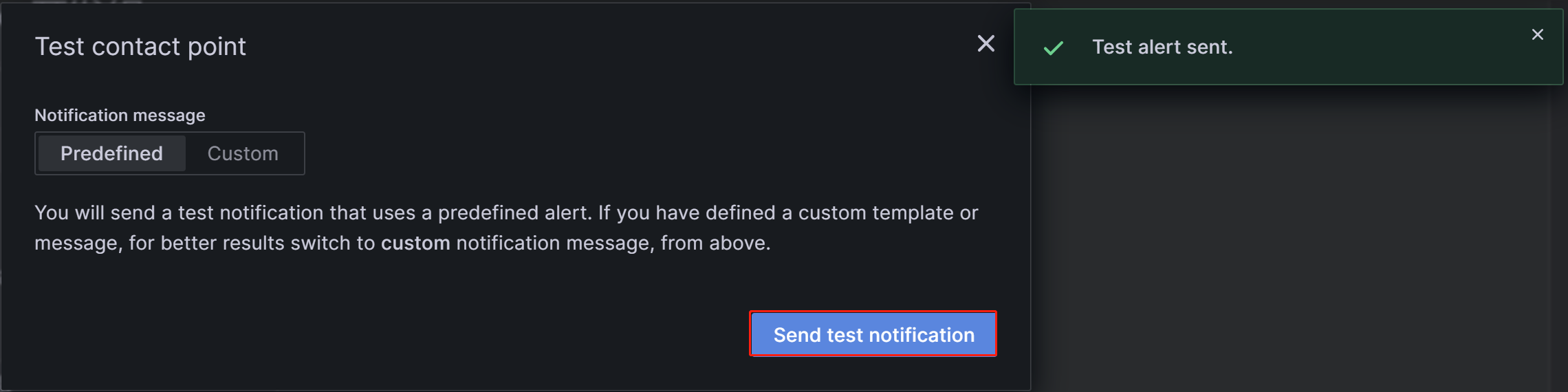
在一个告警渠道中,是允许通过Add contact point integration来配置多种通知方式的,这里我们不再展开。关于Contact points的更细节的介绍可参考Grafana官方文档:
在确认可以正常收到告警提示邮件后,就可以点击页面下方的“Save contact point”按钮完成告警渠道的配置。
为了便于后续演示,假设我们在这一步使用不同的邮箱创建了“ StarRocks 开发组” 和 “ StarRocks 运维组” 两个告警渠道。
4.3 设置通知策略
Grafana通过“通知策略”来关联“告警渠道”和“告警规则”。“通知策略”使用“标签匹配器”为我们提供了一种将不同告警路由到不同接收者的灵活方法,可以实现运维过程中常规的“告警分组”。
我们先点击:菜单->Alerting右侧的展开符号->Notification policies,进入通知策略配置页面。

进入菜单后,可以看到默认有一个Default policy:
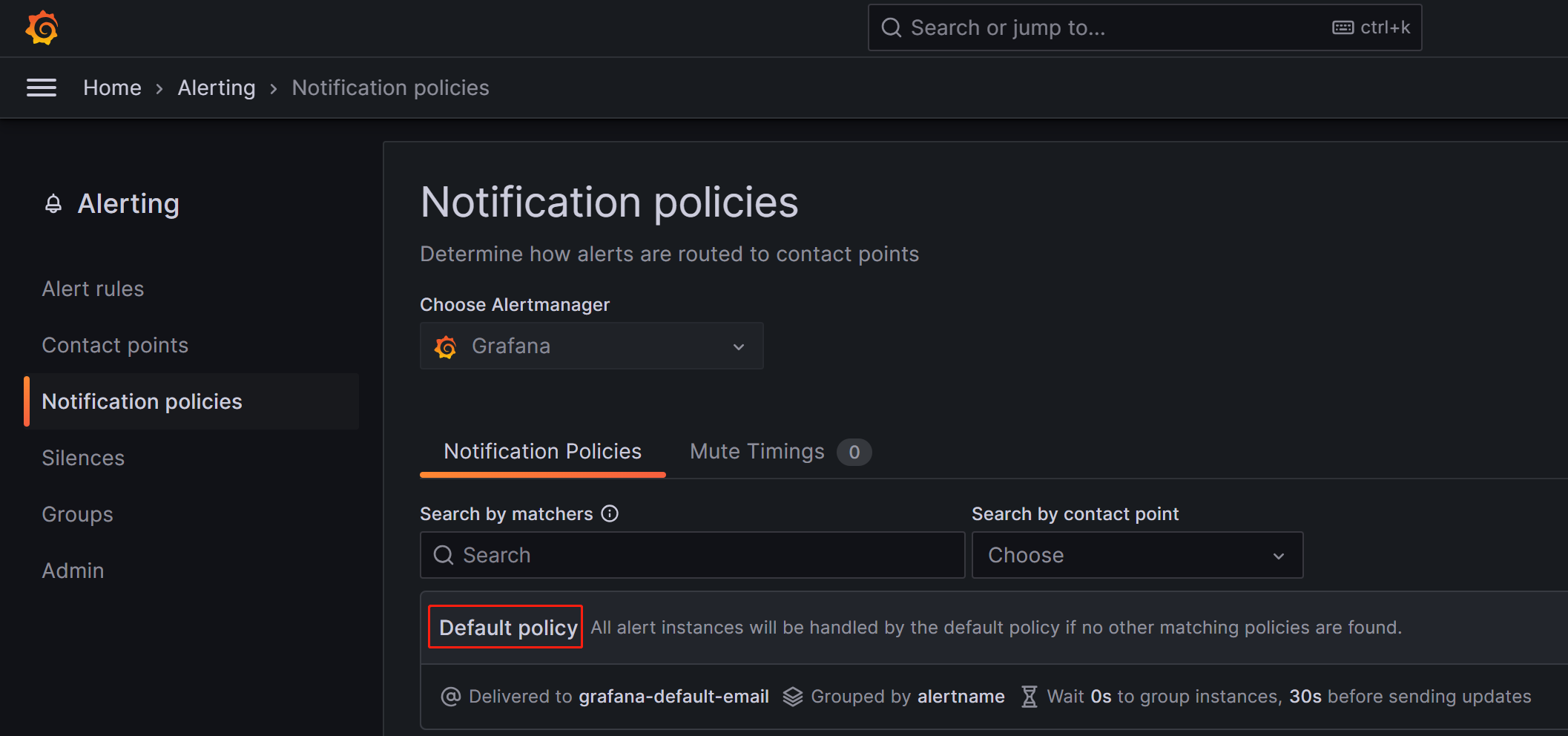
Notification policies使用的是Tree structure,Default policy即表示默认的根策略,在我们不设置其他策略时,所有的告警规则都会默认匹配至该策略,然后使用其中配置的Default contact point默认告警渠道来进行告警。
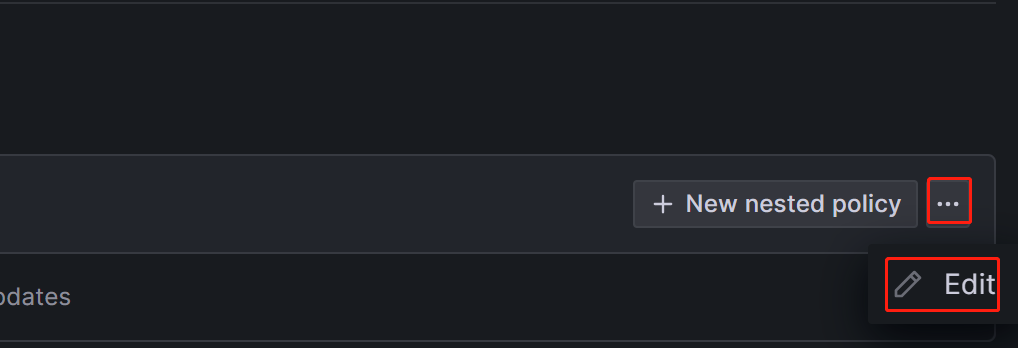
我们点击Default policy右侧的省略号->Edit,编辑Default policy:
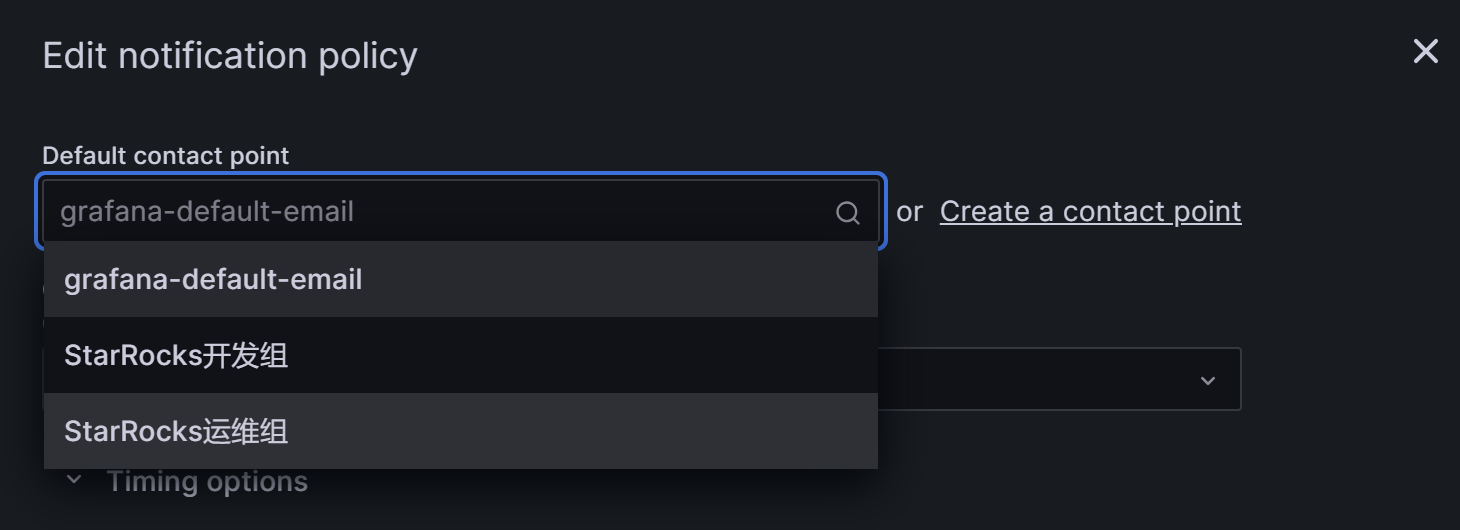
首先在Default contact point中选择前面创建好的“告警渠道”,例如我们选择“StarRocks运维组”:
Group分组是Grafana Alerting中的一个关键概念,它将具有相似性质的告警实例分类到单个漏斗中,我们本次演示的场景暂时不考虑分组,可以保留默认的分组或者将其中的分组给叉掉:
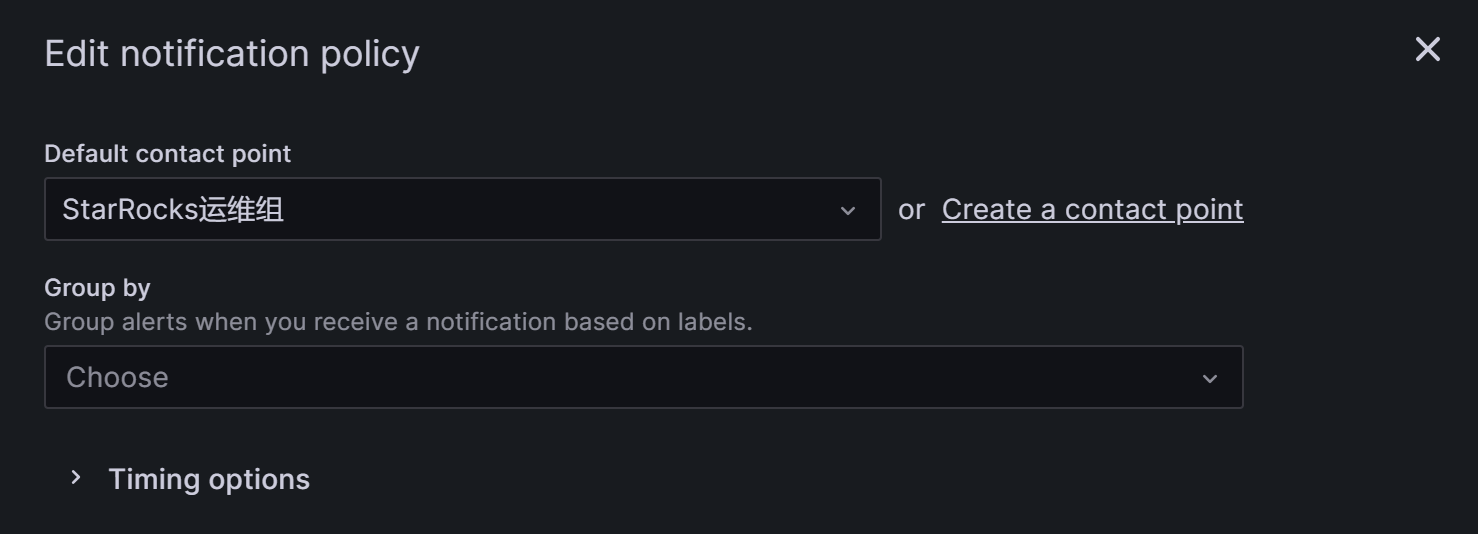
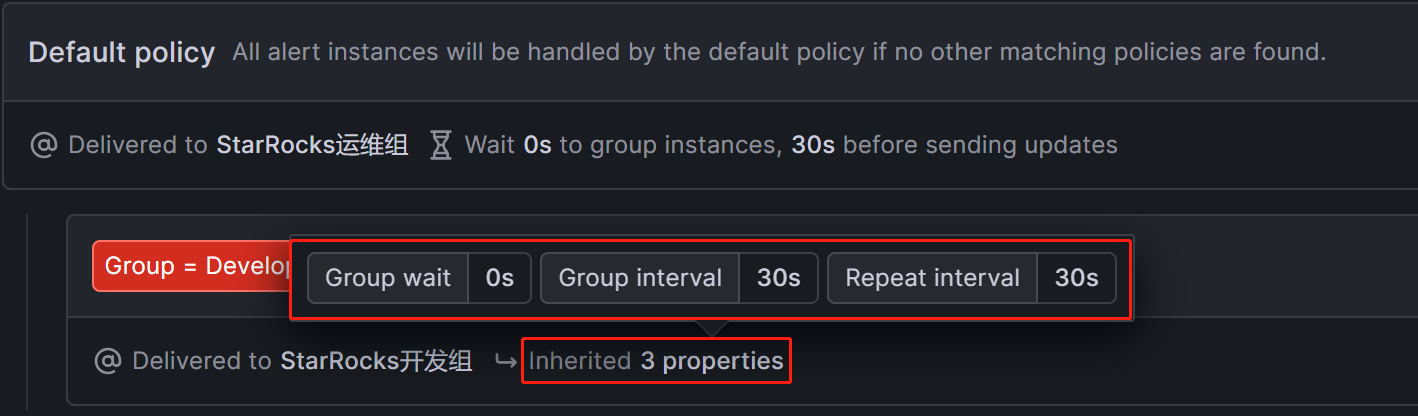
展开Timing options窗口,可以看到有三处时间配置选项group_wait、group_interval和repeat_interval。这三个参数的释义描述相对模糊,先附上官网的参数说明:
Group wait : The waiting time until the initial notification is sent for a new group created by an incoming alert. Default 30 seconds.
Group interval : The waiting time to send a batch of alert instances for existing groups. This means that notifications will not be sent any sooner than 5 minutes (default) since the last batch of updates were delivered, regardless of whether the alert rule interval for those alert instances was lower. Default 5 minutes.
Repeat interval : The waiting time to resend an alert after they have successfully been sent. This means notifications for firing alerts will be re-delivered every 4 hours (default). Default 4 hours.
针对StarRocks集群,我们可以将这三个时间配置如下图,这样实现的效果即为:在 满足告警条件 后的0s(group_wait),会首次发送告警邮件,之后每经过1分钟(group interval +repeat interval),会再次发送告警邮件。
说明:上文提到的是“满足告警条件”而非“触发告警阈值”,这是由于为避免误报,我们在配置告警规则时,通常会设置为“触发告警阈值”后持续多长时间才视为“满足告警条件”。
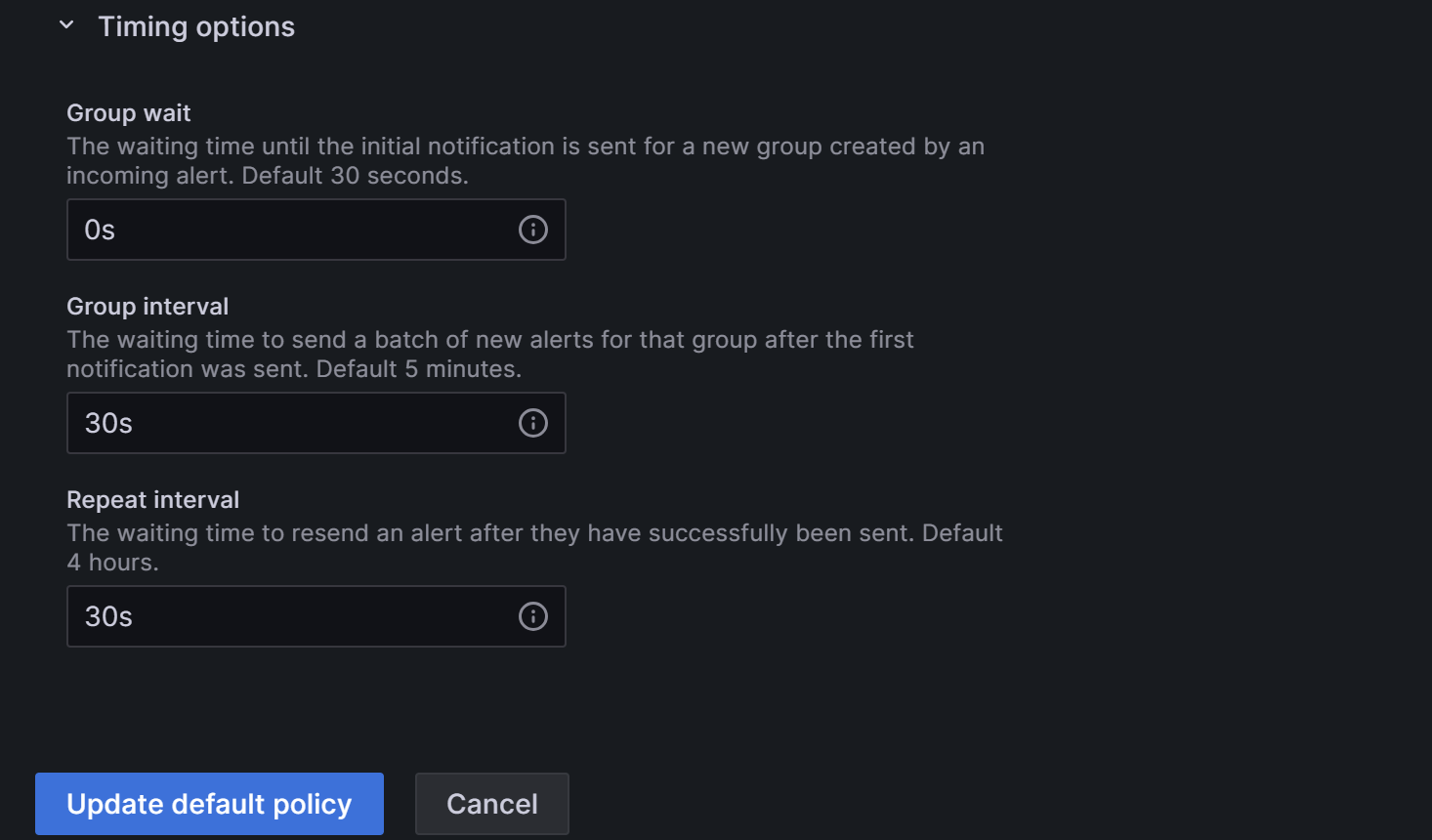
配置完成后点击“Update default policy”完成策略更新。
为了方便演示,我们再在Notification policies页面点击“New nested policy”按钮创建一个子策略。
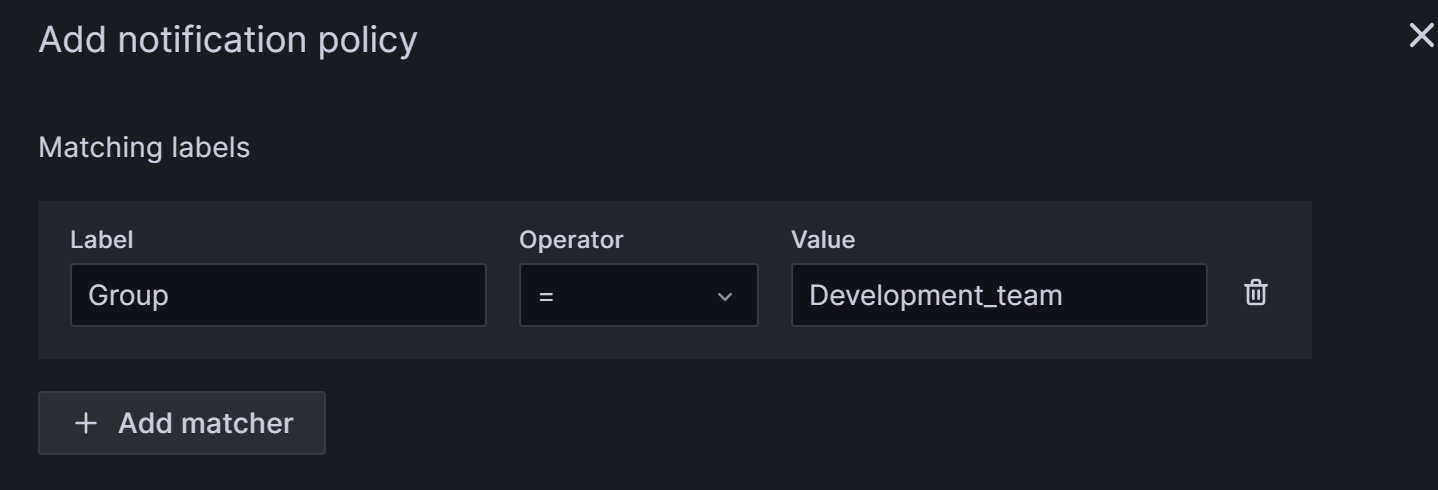
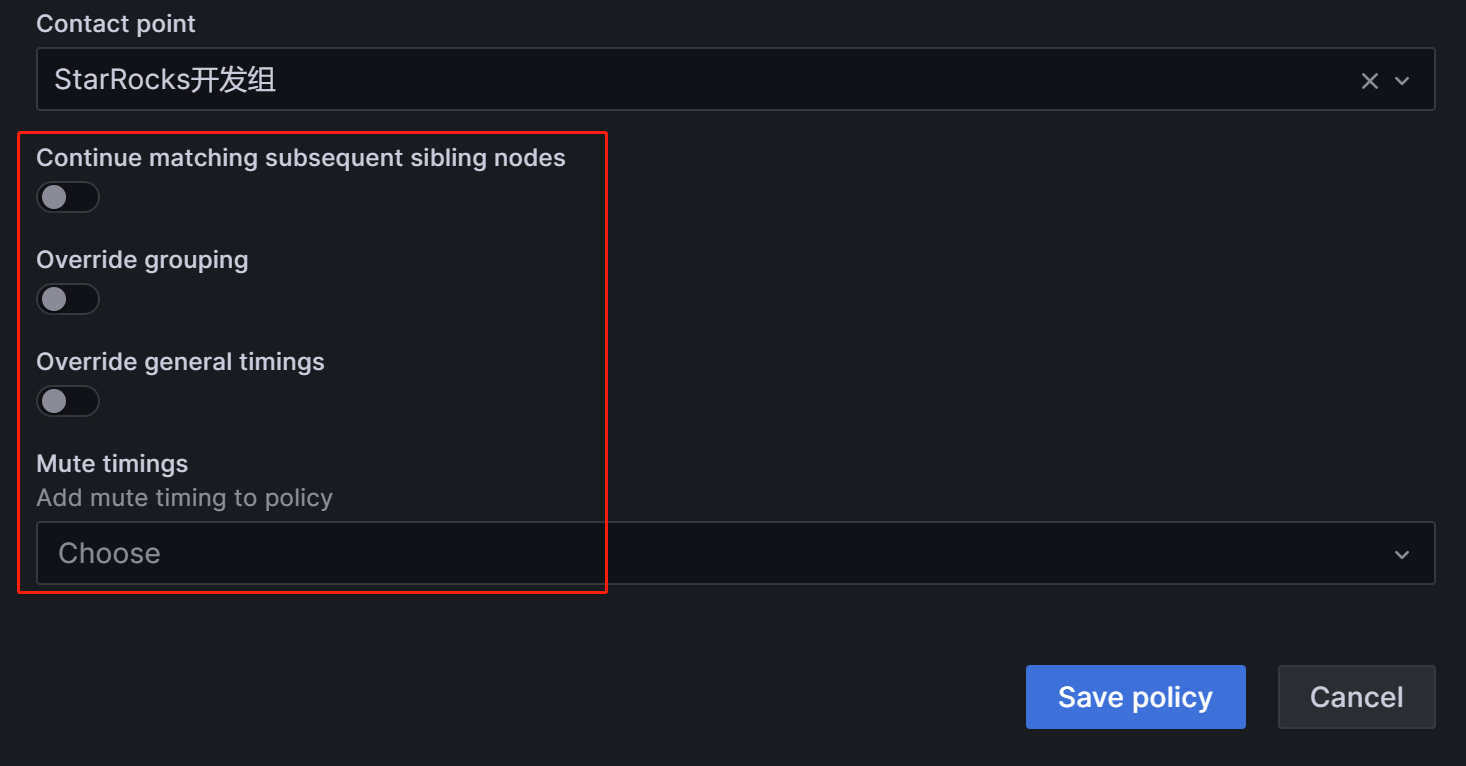
子策略中用Label表示我们的匹配规则。在子策略中定义的Label,我们可以在后续配置“告警规则”时作为条件进行匹配,例如我们这里配置Label为:
Group=Development_team
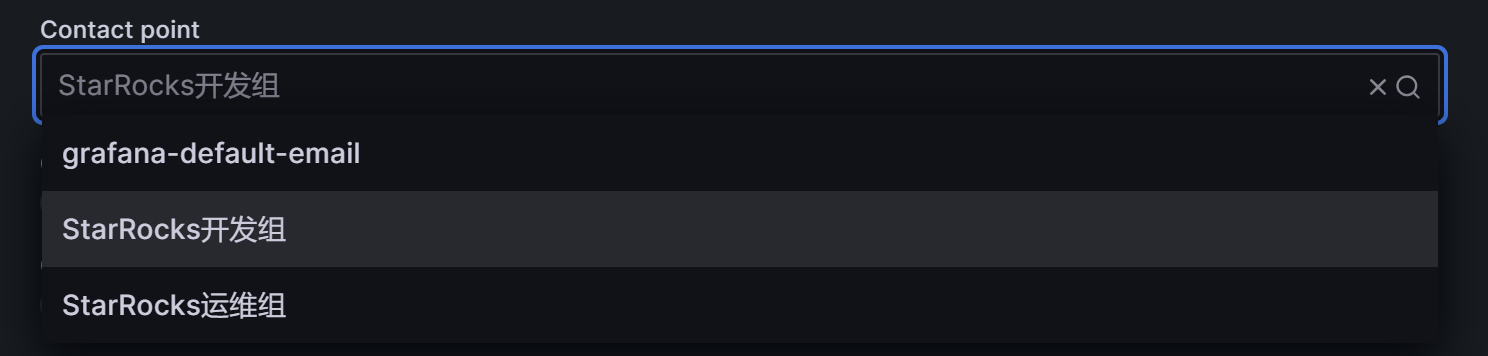
在Contact point中,选择告警渠道为“StarRocks开发组”,这样后续在告警规则中配置Label为“Group=Development_team”的告警项,就会使用“StarRocks开发组”这个渠道进行告警:
再下面的几个选项,我们均使用默认值,这样简单处理,让子策略继承父策略的“时间选项”属性。配置完成后点击“Save policy”保存策略:
若大家对通知策略的细节感兴趣,或者业务中有更复杂的告警场景要求,可以参考官网文档notifications章节:
4.4 创建告警规则
完成上述准备工作后,就可以开始告警规则的创建。告警规则可在Grafana Dashboard中配置,使用浏览器访问192.168.110.23:9090,登陆后可以在页面顶部的搜索栏中快速访问我们前面配置的Dashboard:

4.4.1 FE/BE异常监控
对于StarRocks集群,所有FE和BE节点状态需均为alive,任一节点状态为DEAD都应触发告警,以便运维或开发人员及时排查异常原因。
为方便演示,我们选用Overview下的Frontends Status和Backends Status指标项配置对FE和BE的状态监控。在Prometheus中可以配置多套StarRocks集群,需注意Overview下的这两项是全部集群的而非单套集群的,若需针对单套集群进行配置,在我们掌握方法后,可以使用Cluster Overview下的项自行配置。
1、FE告警规则配置
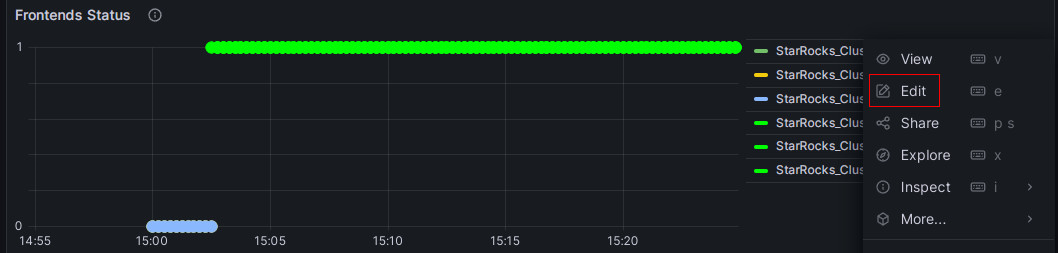
对Frontends Status配置告警,点击监控项右上角“三个点”样式的Menu菜单按钮,点击Edit,在弹出的页面中选择“Alert”菜单,点击“Create alert rule from this panel”开始创建规则:
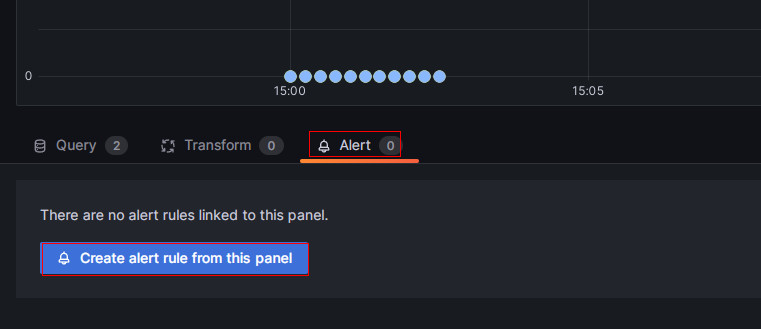
整个告警规则的配置需要5步,我们逐项说明:
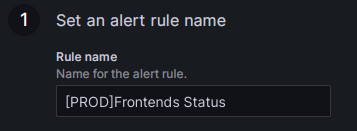
1 )规则名称
默认取值为监控项的title。若集群较多,也可以添加集群名作为前缀进行区分,例如:
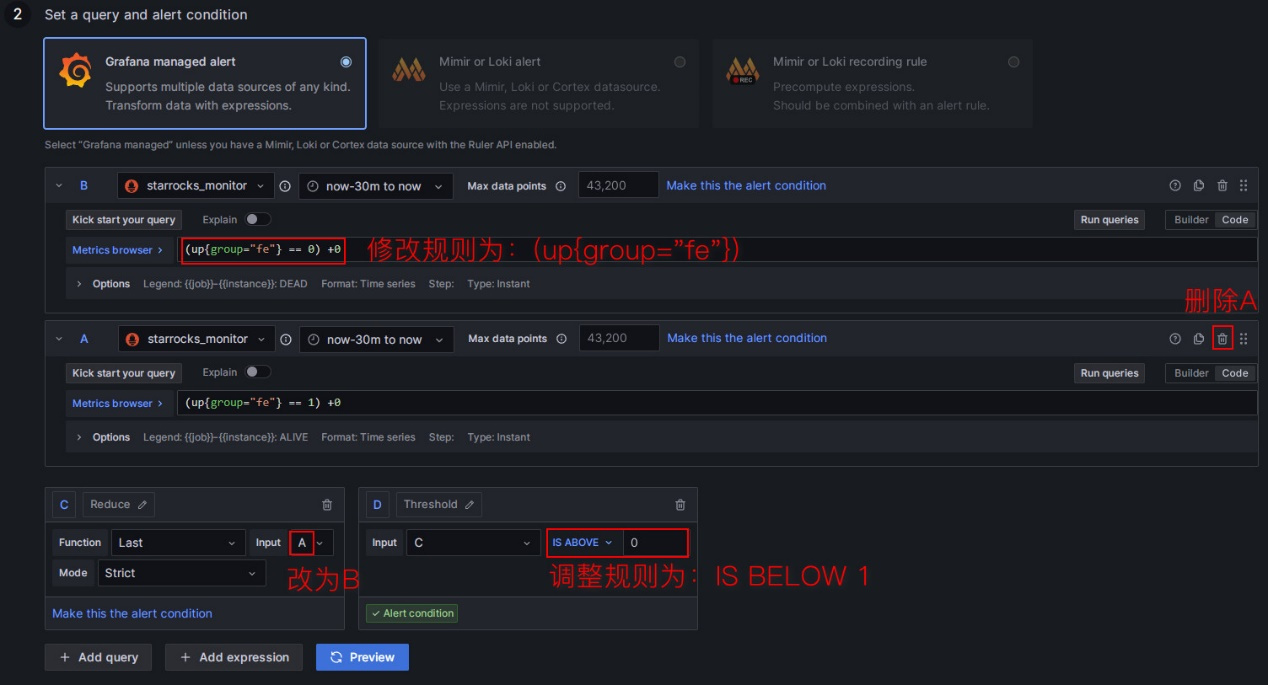
2 )设置告警规则
这一步操作,不熟悉Prometheus和Grafana的同学会比较懵,我们先对原始菜单自上而下做如图处理:
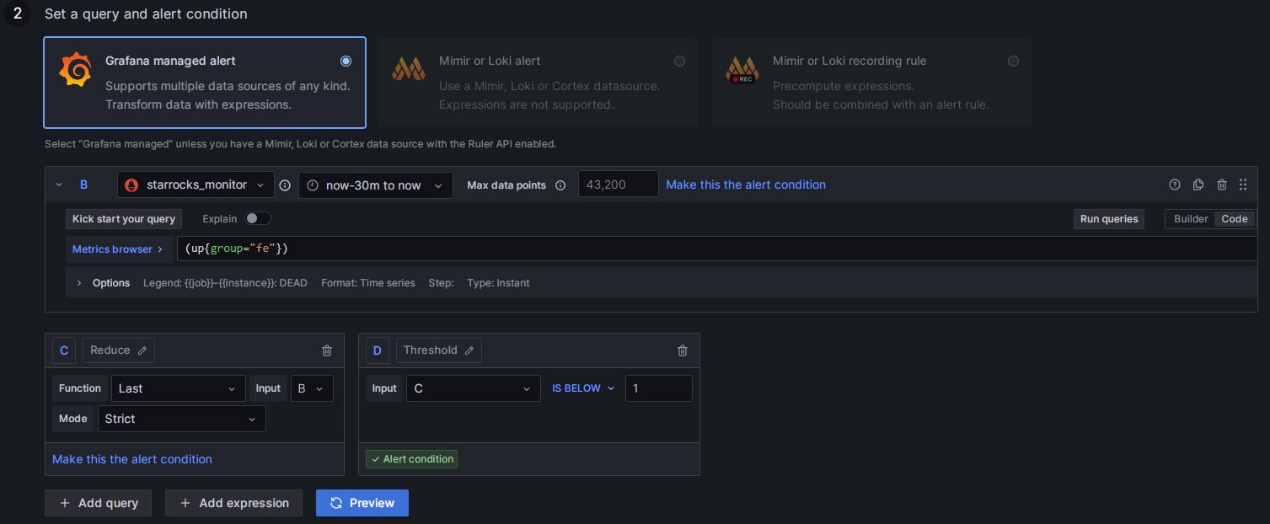
处理完成后的界面为:
接下来我们稍作展开进行解释。
在Grafana中配置告警规则通常可分为三步:
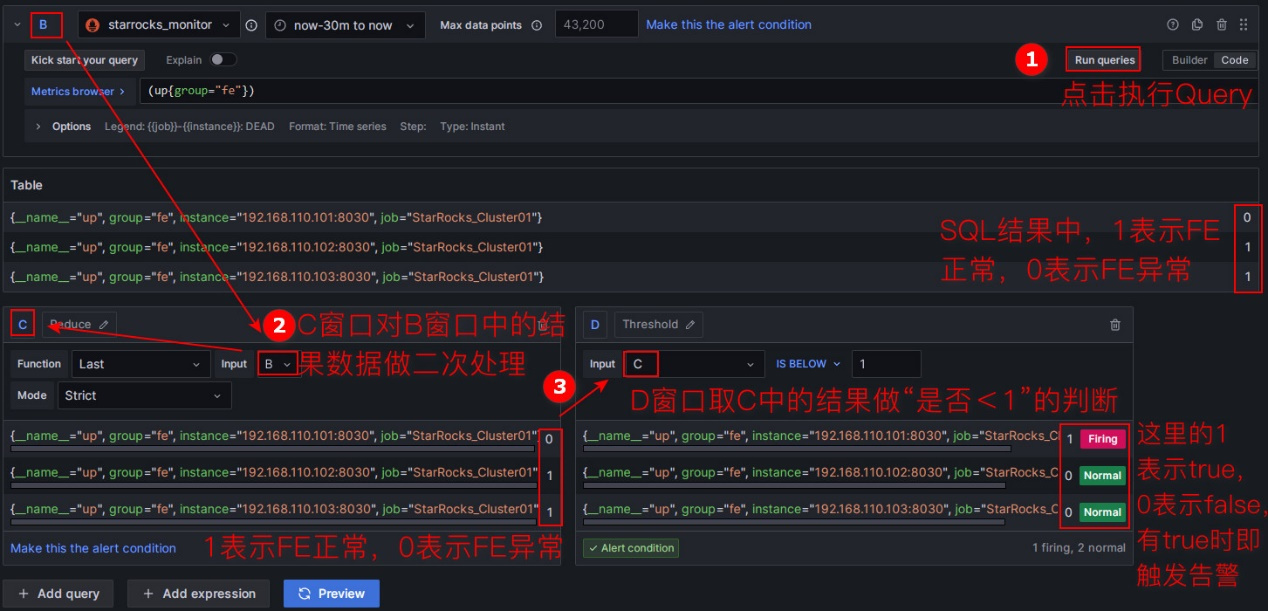
①:通过PromQL查询获取Prometheus中指标项的值,PromQL是Prometheus自己开发的数据查询DSL语言,我们在Dashboard的json模板中也有使用到,每个监控项的expr属性即为对应的PromQL。我们可通过点击下图的“Run queries”按钮来查看查询结果;
②:对①中的结果数据做函数和模式的处理。通常使用Last函数获取最新的值,使用Strict严格模式来保证若非数字数据可以展示为NaN;
③:对②中的结果设置判断规则。以FE为例,FE状态正常时,②中得到的结果为1,若FE宕掉,则会为0,因此可以设置判断规则为“小于1”,出现该情况时即会触发告警。
3 )告警规则评估
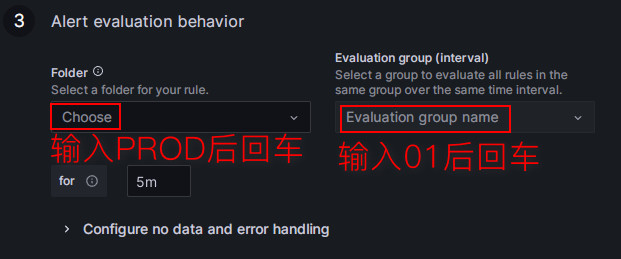
这里用来配置评估警报规则的频率以及更改其状态的速度(官网翻译),通俗的讲就是在这里配置“多久使用上面的告警规则进行一次检查”,以及“发现异常后,这个异常情况持续多久才触发告警(避免单次的抖动引起误报)”。每个评估组都包含一个独立的评估间隔,用于确定检查警报规则的频率,这里我们单独为StarRocks生产集群创建新的文件夹PROD,在其中创建新的Evaluation group为01:
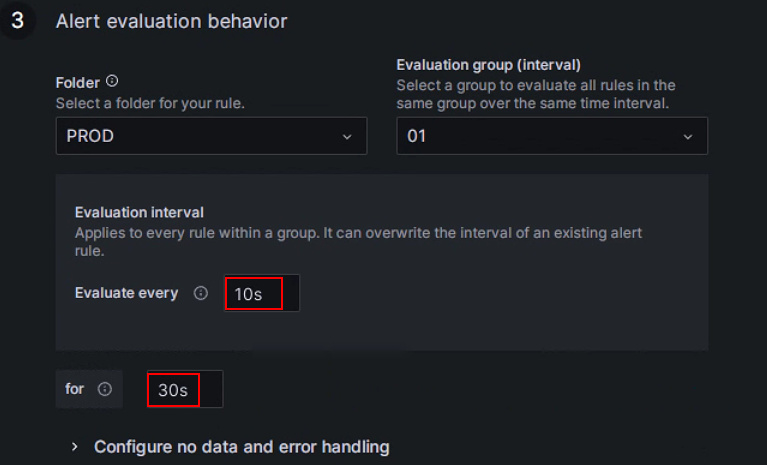
为该组配置检查周期为每10秒一次,异常持续30秒后“满足告警条件”触发告警:
说明:在前面配置告警渠道章节,我们提到了Disable resolved message选项,在集群“对应服务异常恢复”到“发送服务恢复”的邮件的时间受上图Evaluate every参数影响,也即Grafana进行新的检查发现服务恢复后,就会触发邮件发送。
4 )添加告警说明
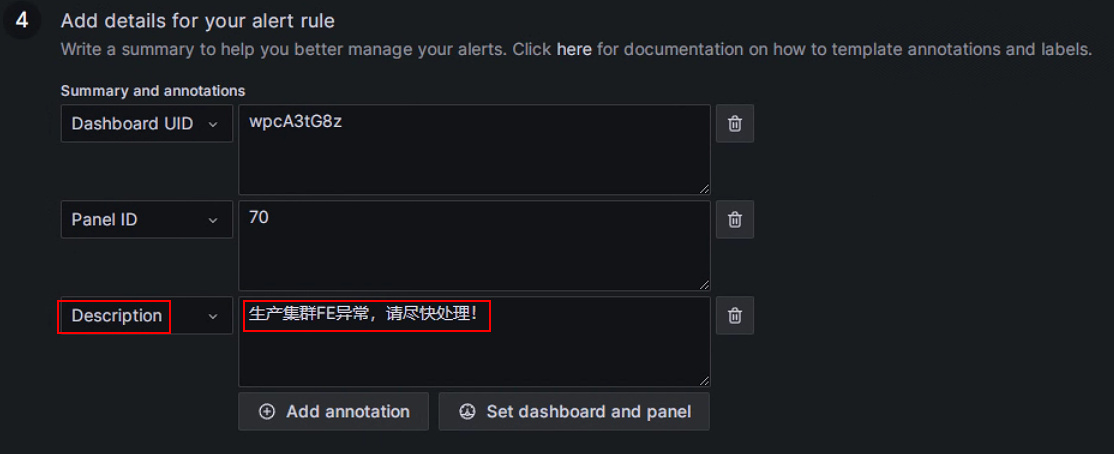
通常我们在这里配置告警邮件的内容信息。下图中的Dashboard UID和Panel ID分别唯一标识我们的Dashboard和监控指标项(可以在监控模板的json文件中看到),这里不要手动修改,直接点击“Add annotation”:

在Choose下拉框中选择Description,自定义添加告警邮件中的描述内容,例如写为:生产集群FE异常,请尽快处理!
5 )匹配通知策略
这里可以与我们4.3章节设置的“通知策略”相绑定。在默认什么都不配置的情况下,所有告警规则都会匹配到Default policy,在满足告警条件后,就会使用Default policy中我们配置的“StarRocks运维组”告警渠道,向其中配置的邮箱群发告警信息。
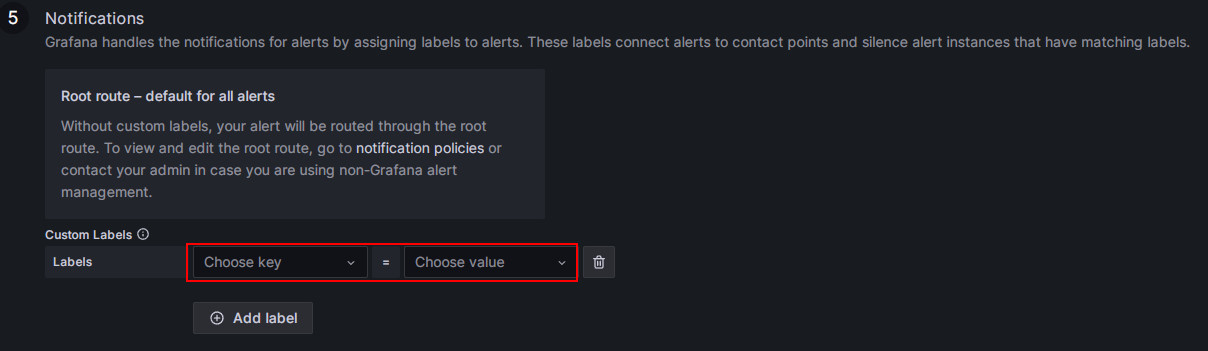
若我们想使用前文创建的绑定了“StarRocks开发组”的子策略,这里的Label就要和子策略中的对应的上,子策略中Label为:
Group=Development_team
Frontends Status项本次我们就配置对应的Label(手动输入后回车):

配置完成后,当满足告警条件,邮件就会发送至“StarRocks开发组”,Default policy策略中运维组的同学不会再收到邮件。
全部配置完成后,点击页面右上方的Save rule and exit按钮,即可保存规则并退出编辑页面:
2、告警触发测试
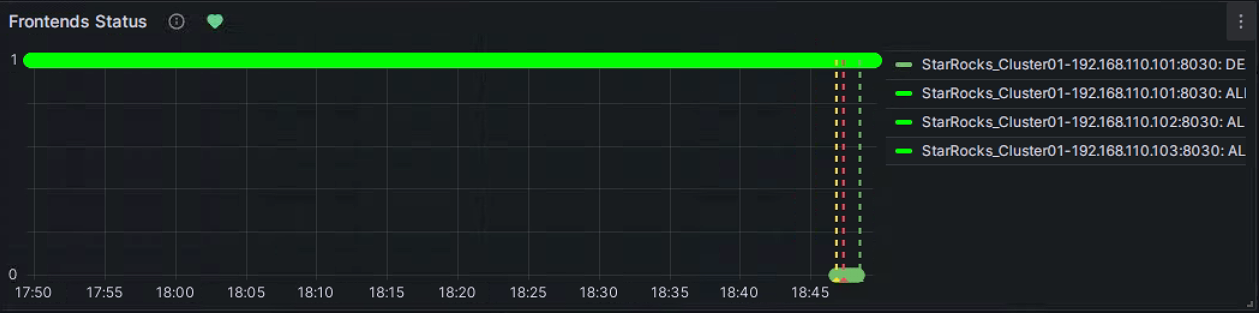
我们可以手动停止一个FE进行告警测试,可以看到Frontends Status标题右侧的心形提示符会经历绿、黄、红这三个状态。
绿色: 在上次周期检查时,该指标项各实例状态正常,未触发告警。并不保证当前状态正常,因为检查是周期性的,例如我们上面配置的10s,同时Prometheus也是15秒取一个metric点,所以在服务出现异常后,会有一个时间上的延迟,但通常延迟都不会到分钟级。
黄色: 上次周期检查发现该指标项有实例出现了异常,但异常还未达到上面配置的“异常持续时间”,不会发送告警,会继续周期检查,直到异常时间达到了“异常持续时间”。在此期间,若状态恢复,则提示符会变回绿色。
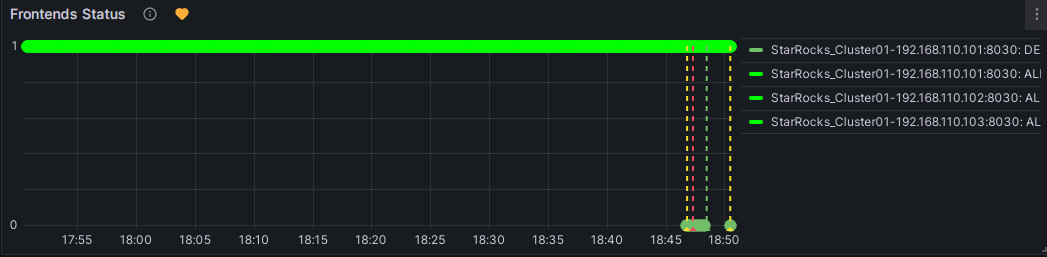
红色: 当黄色异常状态达到“异常持续时间”后,提示符变为红色,触发邮件告警,发送告警邮件。直至异常解除后才恢复绿色。
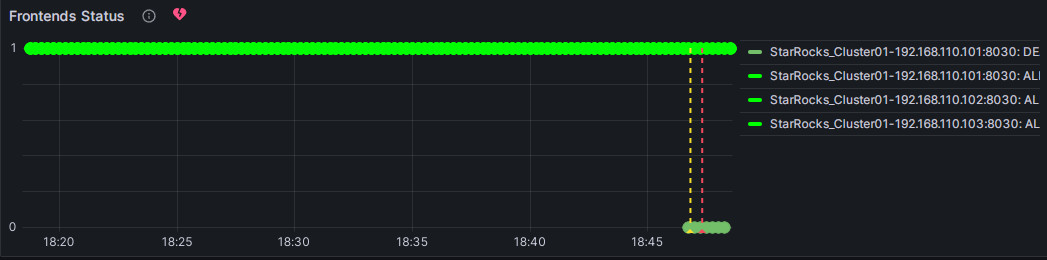
异常告警邮件示例:
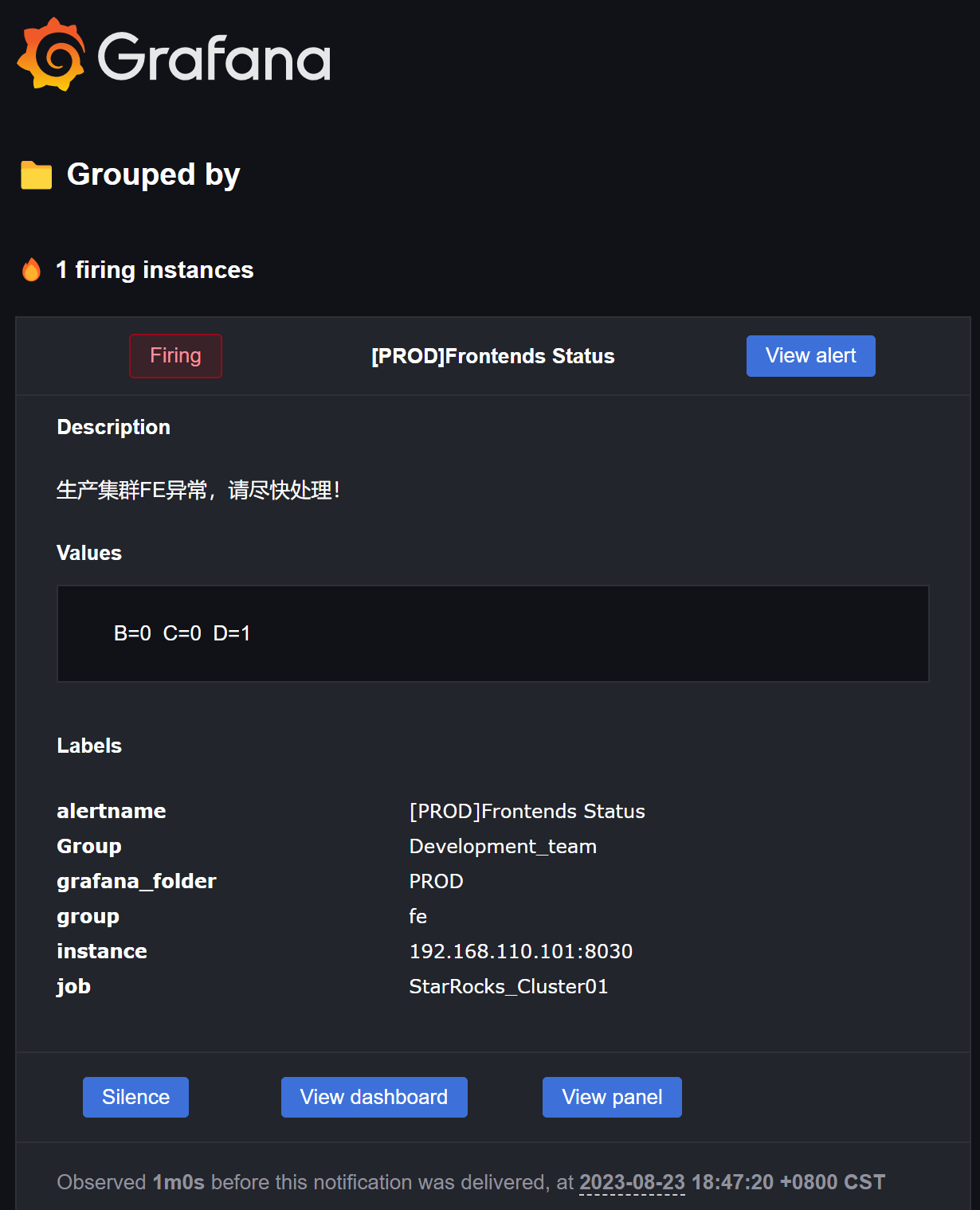
服务恢复邮件示例:
3、手动暂停报警
若异常需要较长时间处理,或其他原因导致告警持续触发,为避免一直发送告警邮件,临时暂停对此告警规则的评估。
可通过Dashboard再次进入该指标项的Alert菜单,编辑告警规则:
在Alert evaluation behavior中打开Pause evaluation按钮即可:
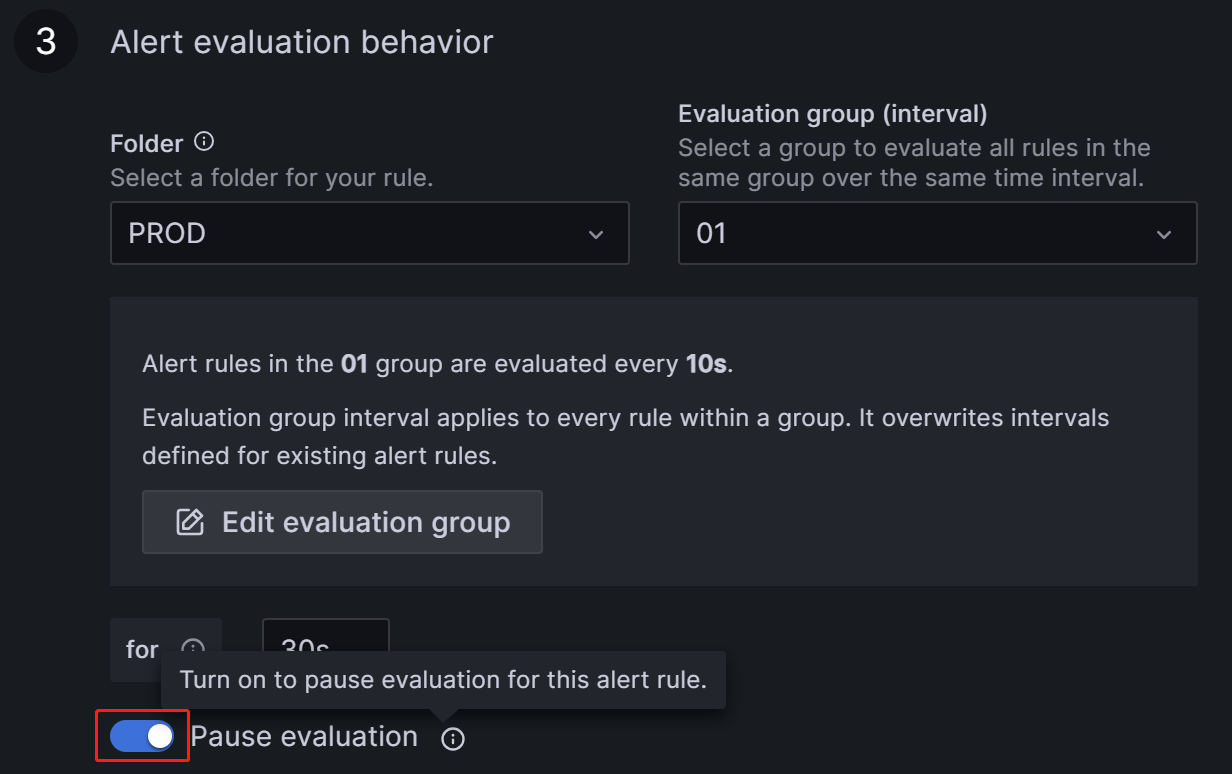
注意:开启暂停按钮后,也会收到一次服务恢复的邮件提示。
4、BE告警规则配置
掌握FE的规则配置操作后,BE的规则配置基本相同,编辑指标项Backends Status,在Edit rule页面的主要配置如下:
1)Set an alert rule name:配置为[PROD]Backends Status。
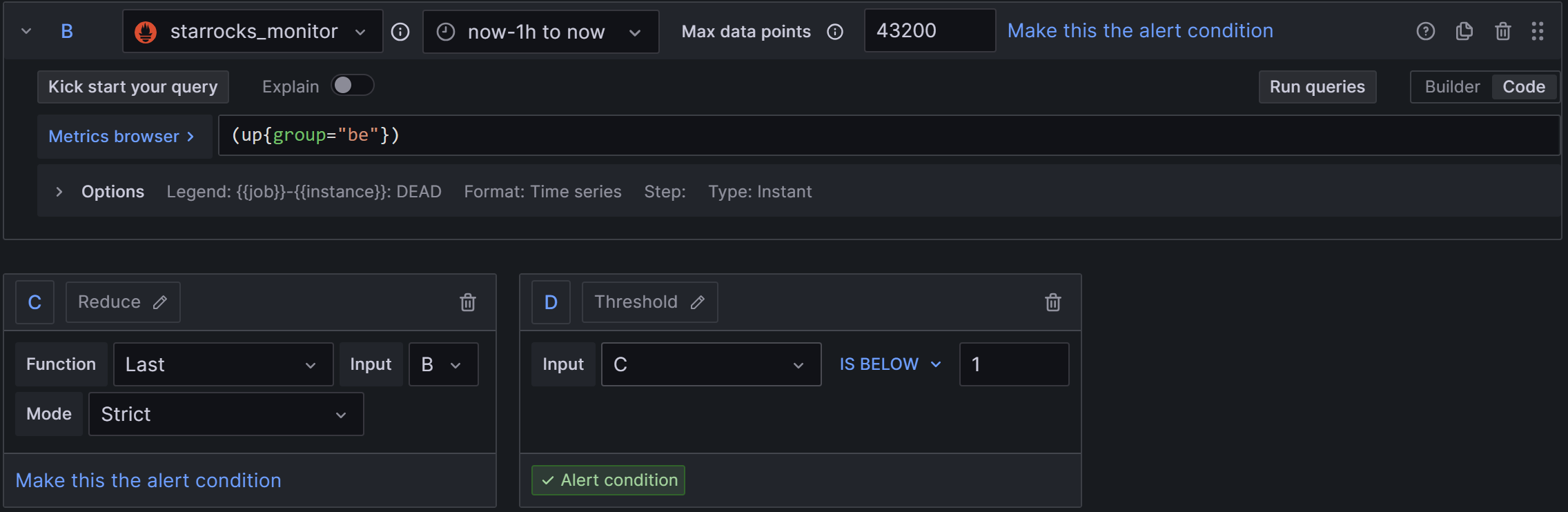
2)Set a query and alert condition:PromSQL处写为(up{group=“be”}),其他配置同FE,如下图:
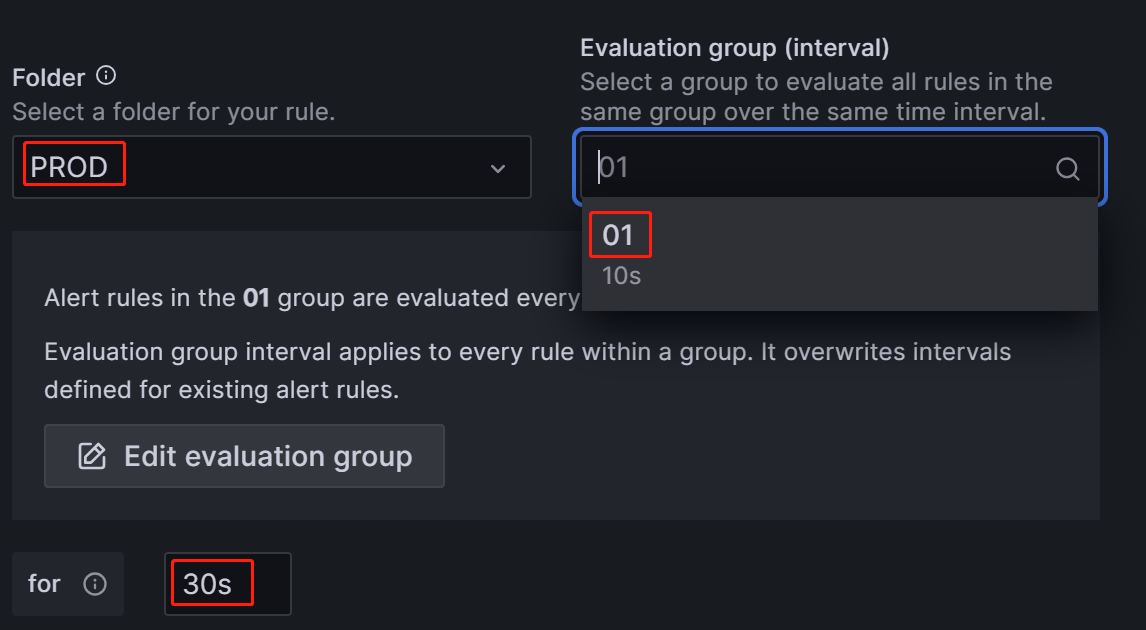
3)Alert evaluation behavior:选择上文创建的PROD目录和01组,“异常持续时间”仍配置为30s即可:
4)Add details for your alert rule:Add annotation后,选择Description,输入告警描述,例如:生产集群BE服务异常,请尽快恢复服务。BE异常后的堆栈信息会打印在be.out中,可根据日志定位原因。
5)Notifications:Labels配置同FE。若不配置Label,使用默认的Default policy,告警邮件发送至“运维组”。
4.4.2 查询失败监控
查询失败对应的指标项为Query Statistic下的Query Error,同样编辑该指标项进入Alert Rule配置菜单,在操作上较之前仍非常接近,各个配置项的说明如下:
1)Set an alert rule name:配置为[PROD] Query Error。
2)Set a query and alert condition:删除B(或者不动它,都不影响),在A中取C的值,C中PromQL使用原本默认的rate(starrocks_fe_query_err{job=“StarRocks_Cluster01”}[1m]),它表示每分钟失败的查询条数除以60s,若一分钟内失败的查询数超过了60次,这个值是可能大于1的。此外,“超时”的SQL也会被计入该项。然后在D中配置规则为A IS ABOVE 0.05,如下图:

3)Alert evaluation behavior:选择上文创建的PROD目录和01组,“异常持续时间”仍配置为30s。
4)Add details for your alert rule:Add annotation后,选择Description,输入告警描述,例如:查询失败率较高,需尽快排查资源占用情况或合理配置查询超时时间(例如set global query_timeout=500,单位为秒)。
5)Notifications:Labels配置同FE。若不配置Label,使用默认的Default policy,告警邮件发送至“运维组”。
4.4.3 外部感知失败监控
该项主要监控Schema Change操作,对应的指标项为BE tasks下的Schema Change,主要监控Schema Change失败的速率,发现大于0就告警。当触发报警后通常可调大变更表操作可用的内存上限,默认为2G,对应参数为be.conf中memory_limitation_per_thread_for_schema_change=2,可将值调整为5。各个配置项的说明如下:
1)Set an alert rule name:配置为[PROD] Schema Change。
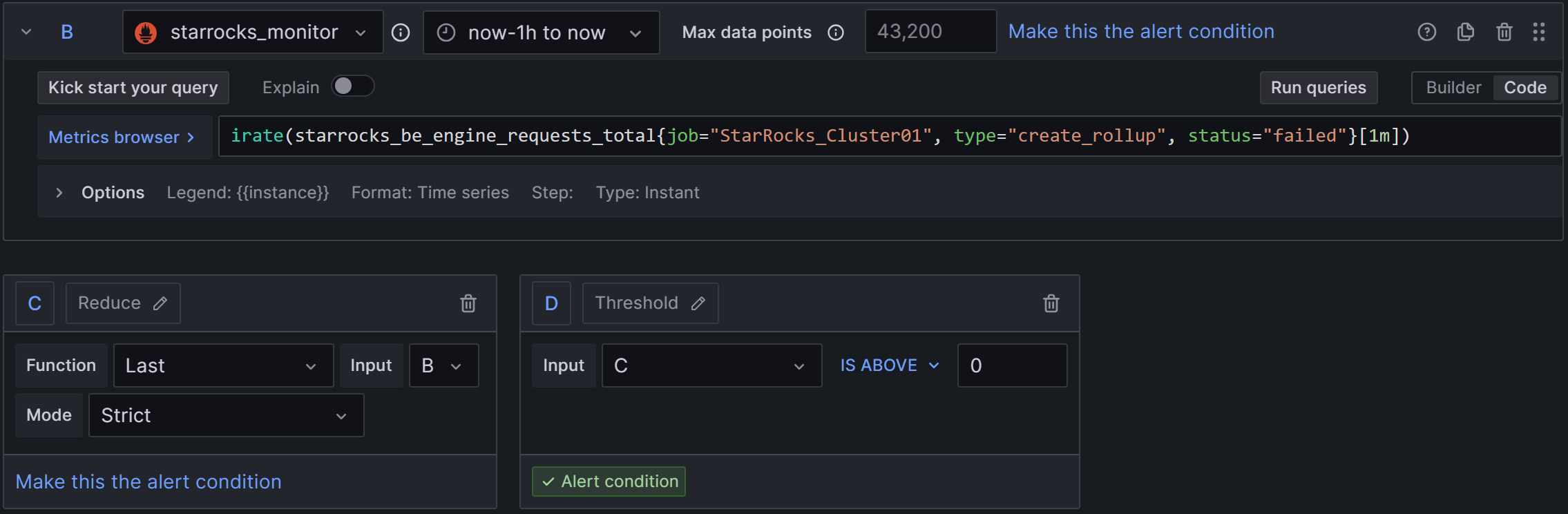
2)Set a query and alert condition:删除A(或者不动它,都不影响),在C中取B的值,B中PromQL使用原本默认的irate(starrocks_be_engine_requests_total{job=“StarRocks_Cluster01”, type=“create_rollup”, status=“failed”}[1m]),它表示每分钟失败的Schema Change任务速率,即1分钟内失败的任务数除以60s的结果。然后,在D中配置规则为C IS ABOVE 0,如下图:
3)Alert evaluation behavior:选择上文创建的PROD目录和01组,“异常持续时间”同样可配置为30s。
4)Add details for your alert rule:Add annotation后,选择Description,输入告警描述,例如:发现变更表任务失败,请尽快排查,通常可调大变更表操作可用的内存上限,默认为2G,对应参数为be.conf中memory_limitation_per_thread_for_schema_change=2,可将值调整为5。
5)Notifications:Labels配置同FE。若不配置Label,使用默认的Default policy,告警邮件发送至“运维组”。
4.4.4 内部操作失败监控
1、BE Compaction Score
该指标项对应Cluster Overview下的BE Compaction Score,主要用于监控集群的Compaction压力,各个配置项的说明如下:
1)Set an alert rule name:配置为[PROD] BE Compaction Score。
2)Set a query and alert condition:使用默认值,只需要修改C中规则为B IS ABOVE 800,如下图:
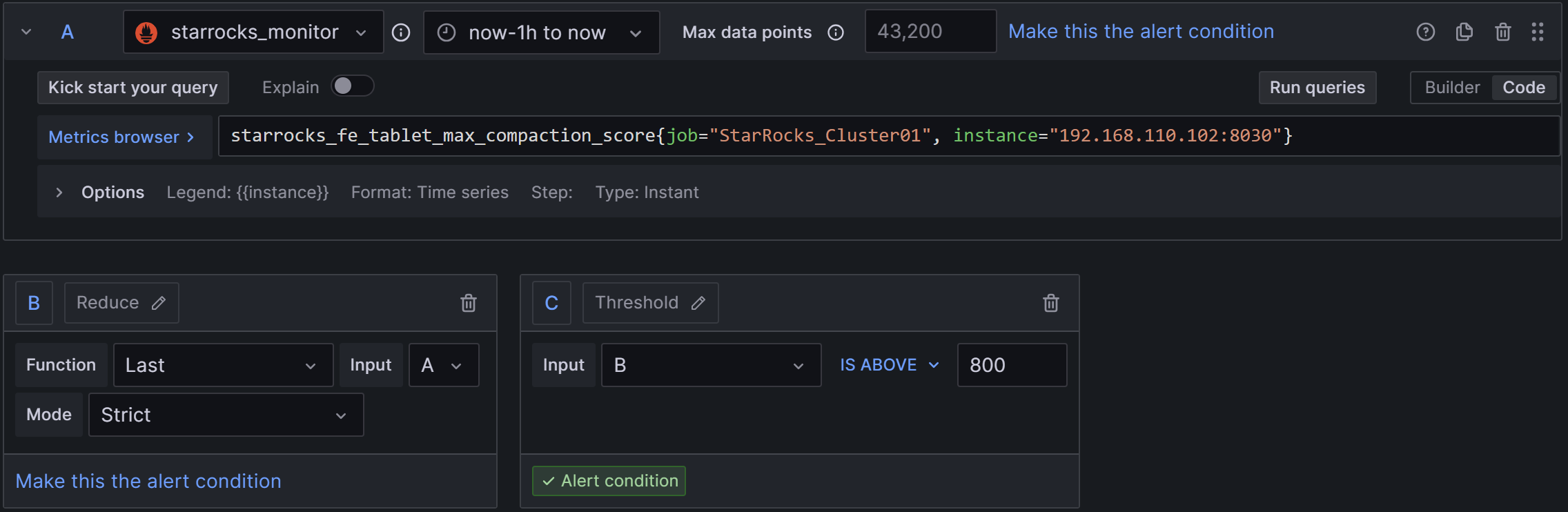
3)Alert evaluation behavior:选择上文创建的PROD目录和01组,“异常持续时间”同样配置为30s。
4)Add details for your alert rule:Add annotation后,选择Description,输入告警描述,例如:集群Compaction压力过大,请排查是否存在高频或高并发的导入行为,并尽快降低导入频率。若集群CPU、内存和IO资源充足,可适当加快集群Compaction策略。
5)Notifications:Labels配置同FE。若不配置Label,使用默认的Default policy,告警邮件发送至“运维组”。
2、Clone
该指标项对应BE tasks中的Clone,主要指StarRocks内部副本均衡或副本修复操作,通常不会失败,各个配置项的说明如下:
1)Set an alert rule name:配置为[PROD] Clone。
2)Set a query and alert condition:删除A(或者不动它,都不影响),在C中取B的值,B中PromQL使用原本默认的irate(starrocks_be_engine_requests_total{job=“StarRocks_Cluster01”, type=“clone”, status=“failed”}[1m]),它表示每分钟失败的Clone任务速率,即1分钟内失败的任务数除以60s的结果。然后,在D中配置规则为C IS ABOVE 0,如下图:
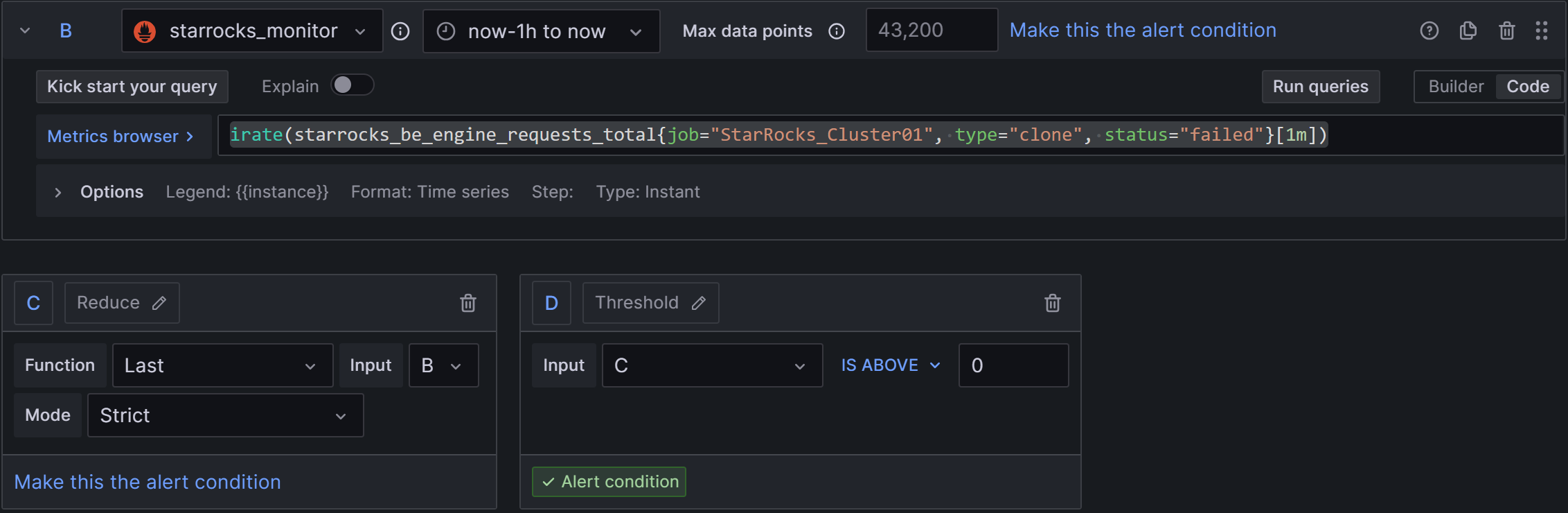
3)Alert evaluation behavior:选择上文创建的PROD目录和01组,“异常持续时间”同样配置为30s。
4)Add details for your alert rule:Add annotation后,选择Description,输入告警描述,例如:监测到出现克隆任务失败,请检查集群BE状态、磁盘状态、网络状态。
5)Notifications:Labels配置同FE。若不配置Label,使用默认的Default policy,告警邮件发送至“运维组”。
4.4.5 服务可用性监控
服务可用性监控初步只整理了对bdb中元数据日志条数,该项对应Cluster Overview下的Meta Log Count,各个配置项的说明如下:
1)Set an alert rule name:配置为[PROD] Meta Log Count。
2)Set a query and alert condition:使用默认值,只需要修改C中规则为B IS ABOVE 100000,如下图:
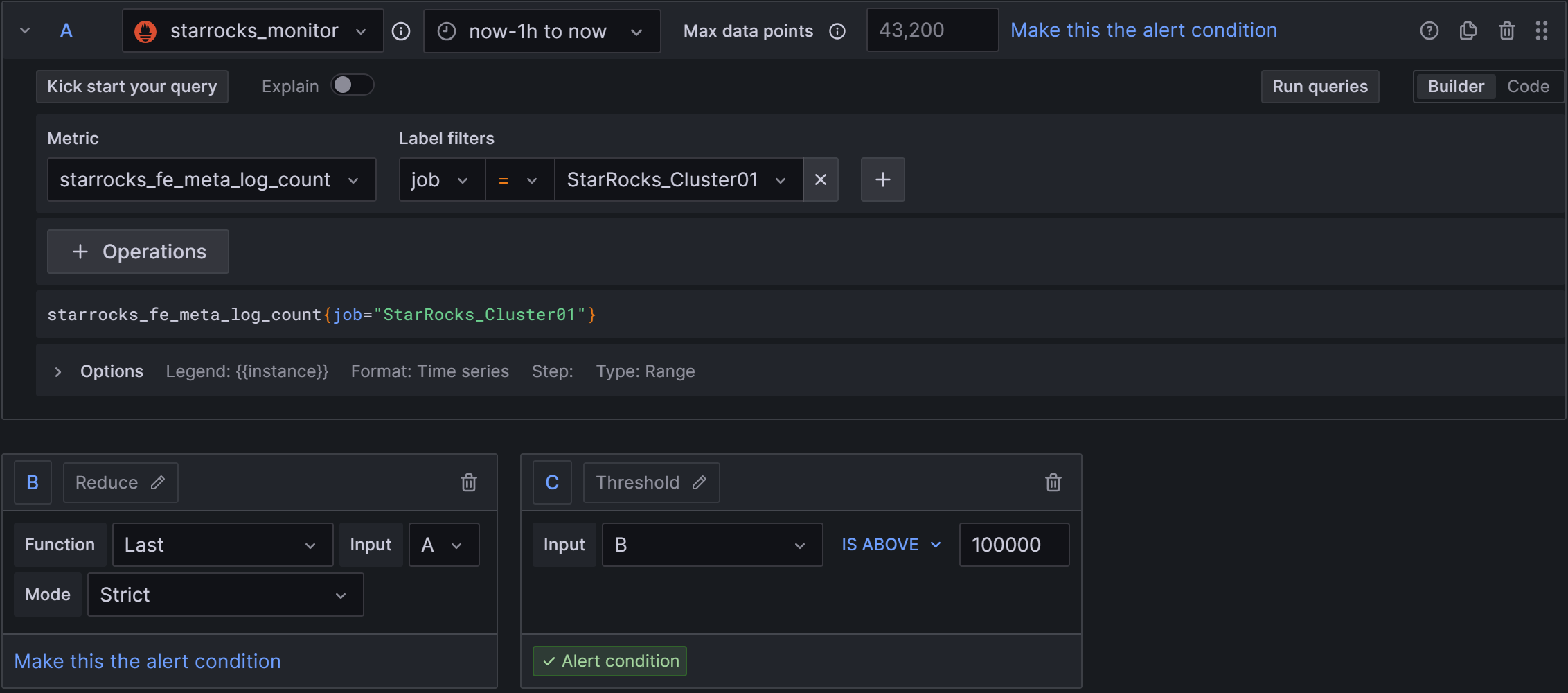
3)Alert evaluation behavior:选择上文创建的PROD目录和01组,“异常持续时间”同样配置为30s。
4)Add details for your alert rule:Add annotation后,选择Description,输入告警描述,例如:监测到FE bdb中元数据条数远大于期望值,这通常代表Checkpoint动作失败,请尽快排查fe.conf中的Xmx堆内存配置是否合理。
5)Notifications:Labels配置同FE。若不配置Label,使用默认的Default policy,告警邮件发送至“运维组”。
4.4.6 机器过载监控项
1、BE CPU Idle
对应BE下的BE CPU Idle,注意Idle表示空闲,各个配置项的说明如下:
1)Set an alert rule name:配置为[PROD] BE CPU Idle。
2)Set a query and alert condition:使用默认值,只需要修改C中规则为B IS BELOW 10,如下图:
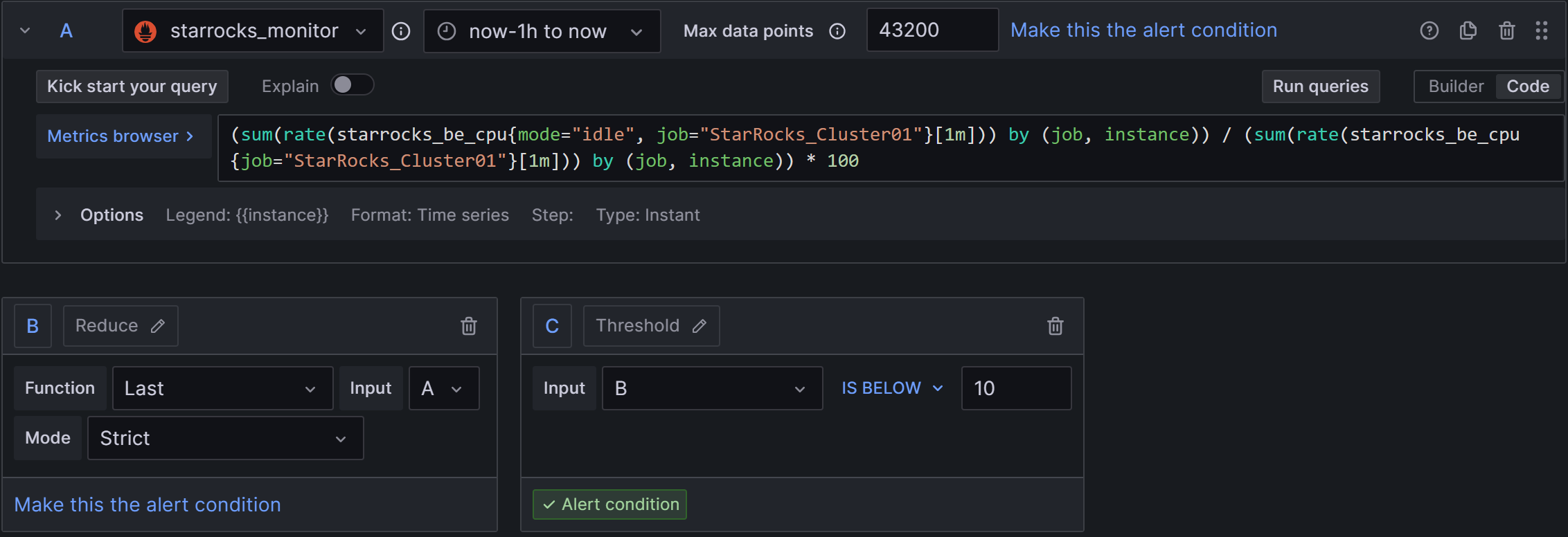
3)Alert evaluation behavior:选择上文创建的PROD目录和01组,“异常持续时间”同样配置为30s。
4)Add details for your alert rule:Add annotation后,选择Description,输入告警描述,例如:BE CPU存在持续过高的情况,这将严重影响集群中的其他业务,请尽快排查集群是否异常或是否存在CPU资源瓶颈。
5)Notifications:Labels配置同FE。若不配置Label,使用默认的Default policy,告警邮件发送至“运维组”。
2、BE Mem
对应BE下的BE Mem,表示BE的内存使用量,各个配置项的说明如下:
1)Set an alert rule name:配置为[PROD] BE Mem。
2)Set a query and alert condition:内存的取值需要根据服务器的实际内存和mem_limit做一些粗略处理,例如通过free -h查看当前服务器内存是61G,因为FE和BE混部,我们限制了mem_limit=80%,则BE可用的内存实际为61 * 0.8 ≈ 49G,则此处公式可写为:starrocks_be_process_mem_bytes{job=“StarRocks_Cluster01”} / (49 * 1024 * 1024 * 1024),
只需要修改C中规则为B IS ABOVE 0.9,如下图:
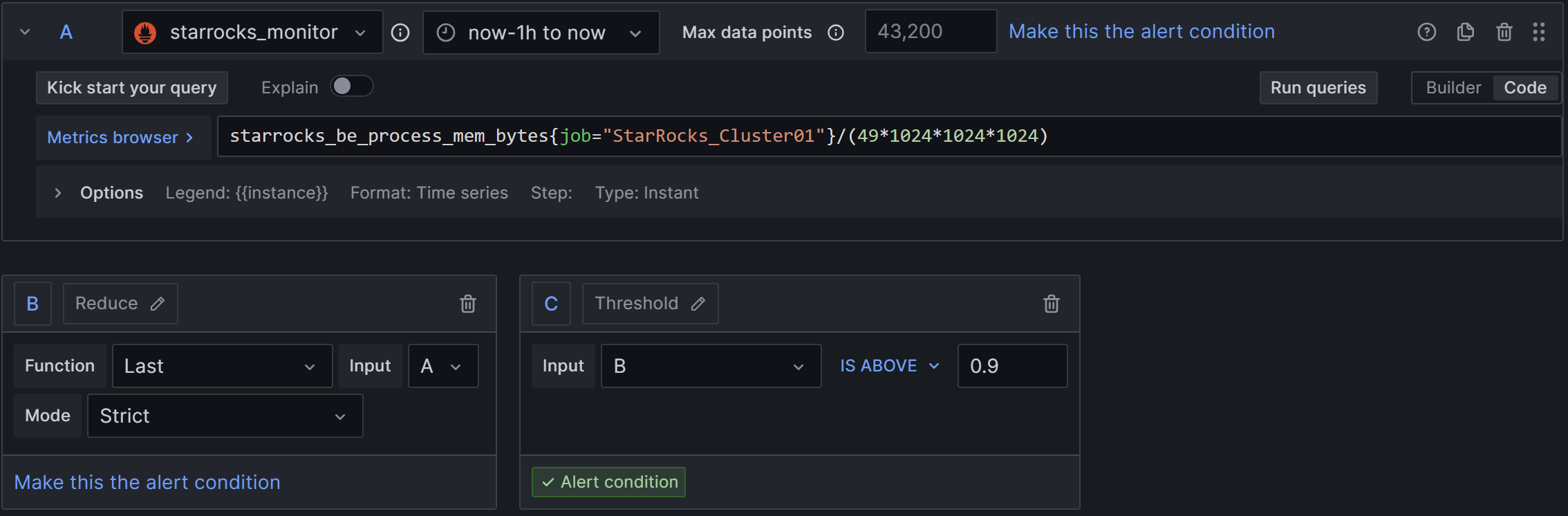
3)Alert evaluation behavior:选择上文创建的PROD目录和01组,“异常持续时间”同样配置为30s。
4)Add details for your alert rule:Add annotation后,选择Description,输入告警描述,例如:BE内存占用已接近BE可用内存上限,为避免业务失败,请尽快拓展内存或增加BE节点。
5)Notifications:Labels配置同FE。若不配置Label,使用默认的Default policy,告警邮件发送至“运维组”。
3、Disks Avail Capacity
对应BE下的Disk Usage,该指标表示BE存储路径所在目录的剩余空间比例。各个配置项的说明如下:
1)Set an alert rule name:配置为[PROD] Disks Avail Capacity。
2)Set a query and alert condition:使用默认值,只需要修改C中规则为B IS BELOW 0.2,如下图:
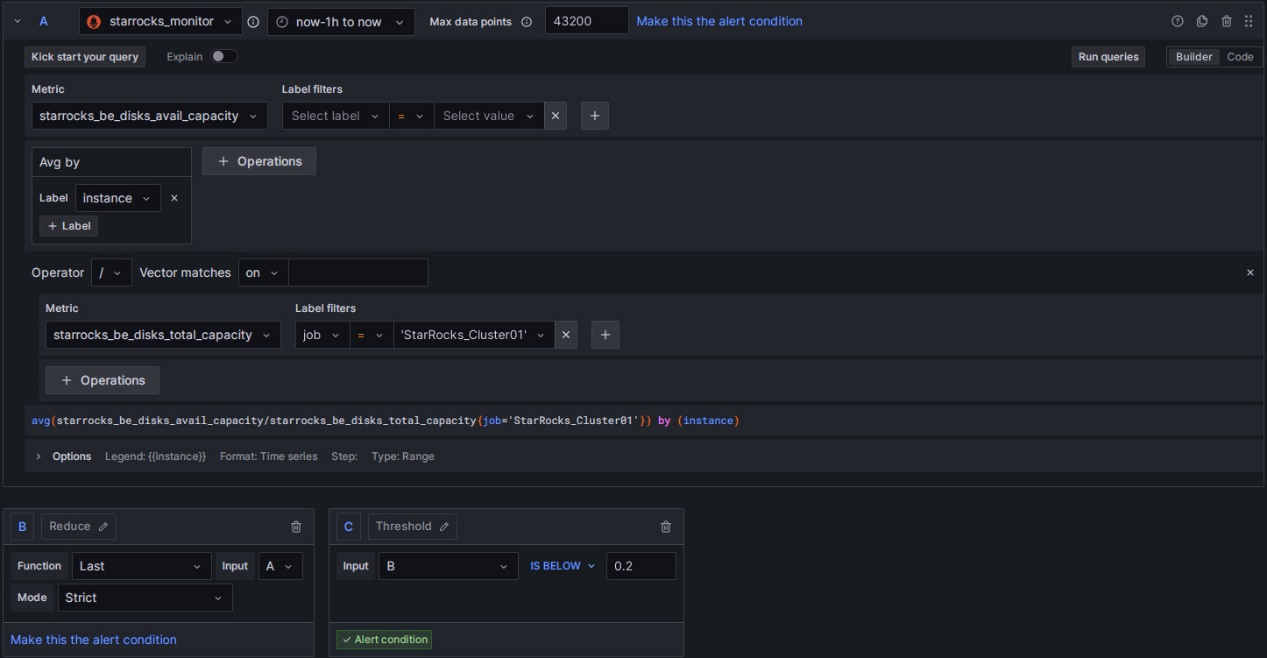
3)Alert evaluation behavior:选择上文创建的PROD目录和01组,“异常持续时间”同样配置为30s。
4)Add details for your alert rule:Add annotation后,选择Description,输入告警描述,例如:BE磁盘可用空间已低于20%,请尽快清理释放磁盘空间或扩容磁盘。
5)Notifications:Labels配置同FE。若不配置Label,使用默认的Default policy,告警邮件发送至“运维组”。
4、FE JVM Heap Stat
指标项为Overview下的Cluster FE JVM Heap Stat,在fe.conf中我们为FE配置了堆内存使用上限值,这个指标可以表示FE使用的JVM内存占其中的比例,各个配置项的说明如下:
各个配置项的说明如下:
1)Set an alert rule name:配置为[PROD] FE JVM Heap Stat。
2)Set a query and alert condition:使用默认值,只需要修改C中规则为B IS ABOVE 80,如下图:
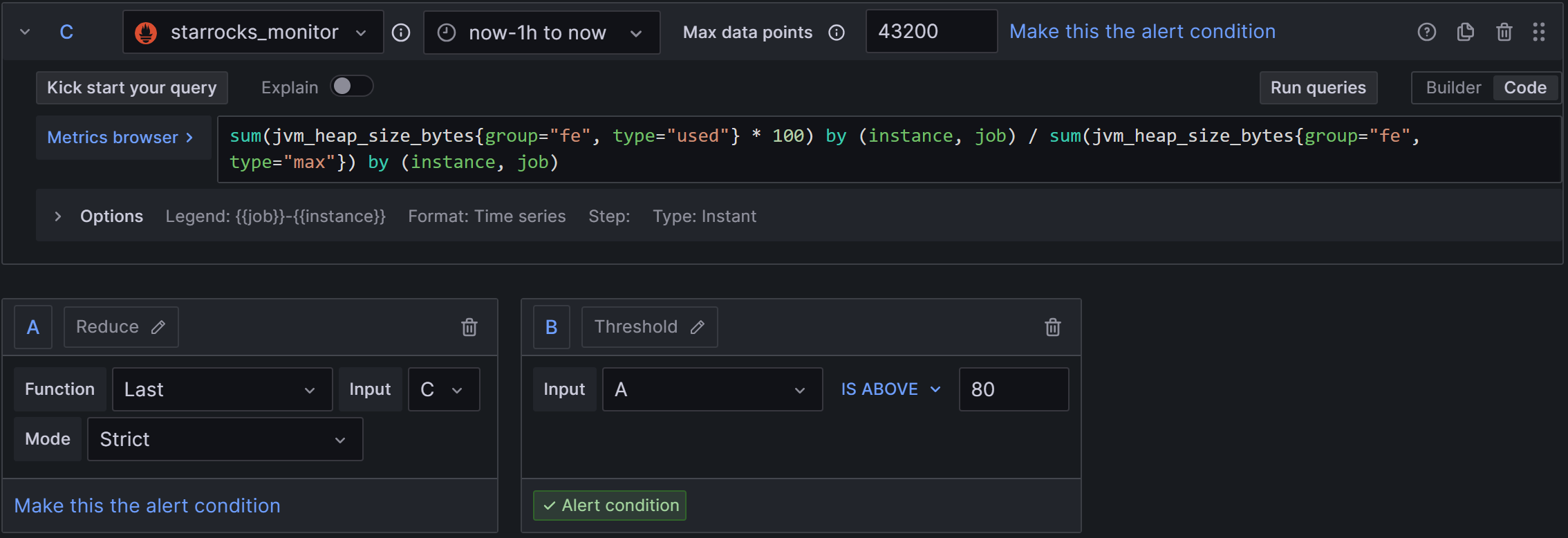
3)Alert evaluation behavior:选择上文创建的PROD目录和01组,“异常持续时间”同样配置为30s。
4)Add details for your alert rule:Add annotation后,选择Description,输入告警描述,例如:FE堆内存使用率过高,请尽快调大fe.conf中堆内存上限。
5)Notifications:Labels配置同FE。若不配置Label,使用默认的Default policy,告警邮件发送至“运维组”。
4.5 查看已创建的规则
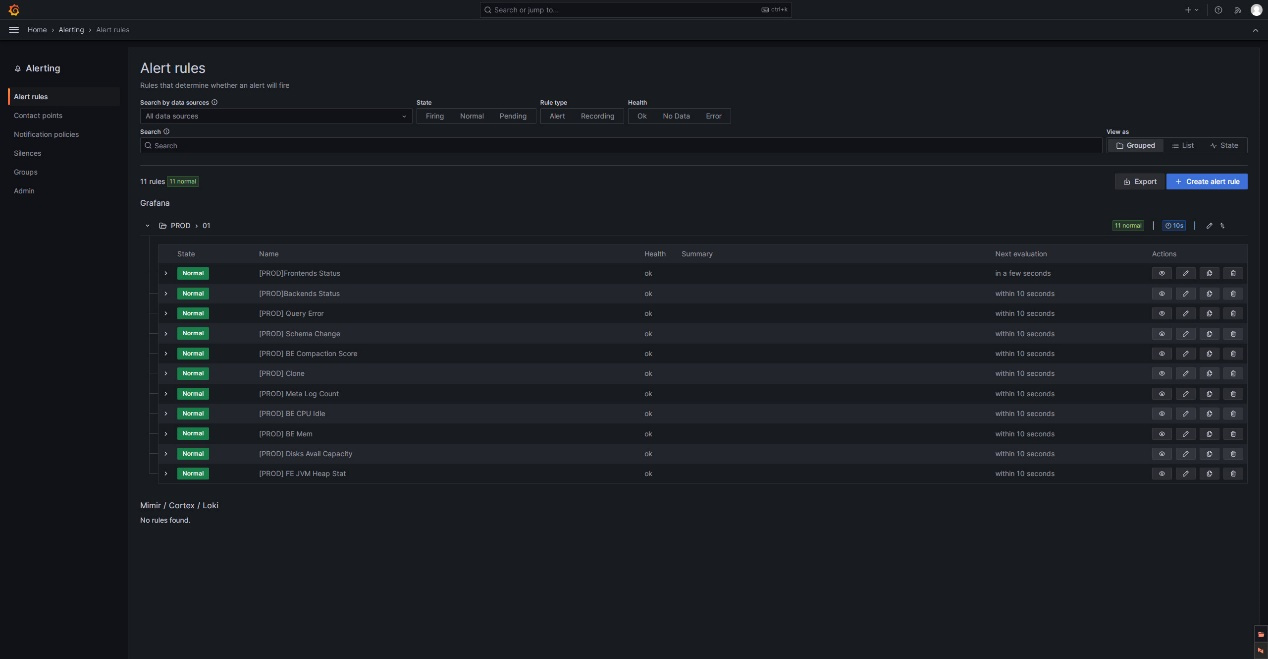
在Grafana中,所有创建的告警规则可以通过菜单->Alerting右侧的展开按钮->Alert rules查看和管理。
展开我们创建的PROD目录的01组,可以看到我们配置的所有告警项的状态和下一轮检查时间,也可以通过这里的编辑按钮对告警规则进行添加或修改:
五、补充说明
5.1 个别指标项值始终为0
目前监控模板的指标项中,BE IO Util和Cumulative Compaction Score可能会出现值一直为0,这是由于当前BE的Metric信息中starrocks_be_max_disk_io_util_percent和starrocks_be_tablet_cumulative_max_compaction_score这两项始终为0引起的。其中磁盘IO为0是由于某些虚拟机下StarRocks无法正确取值,Compaction项为0或是由于metric没有正确取值,该情况已反馈StarRocks RD,指标项当前均先保留。
5.2 Dashboard无法感知异常
Grafana页面取值依赖于所在服务器的系统时间,若集群异常后Grafana页面一直不变,可排查是否由于服务器时钟不一致引起,然后进行集群校时。
5.3 告警分级的实现思路
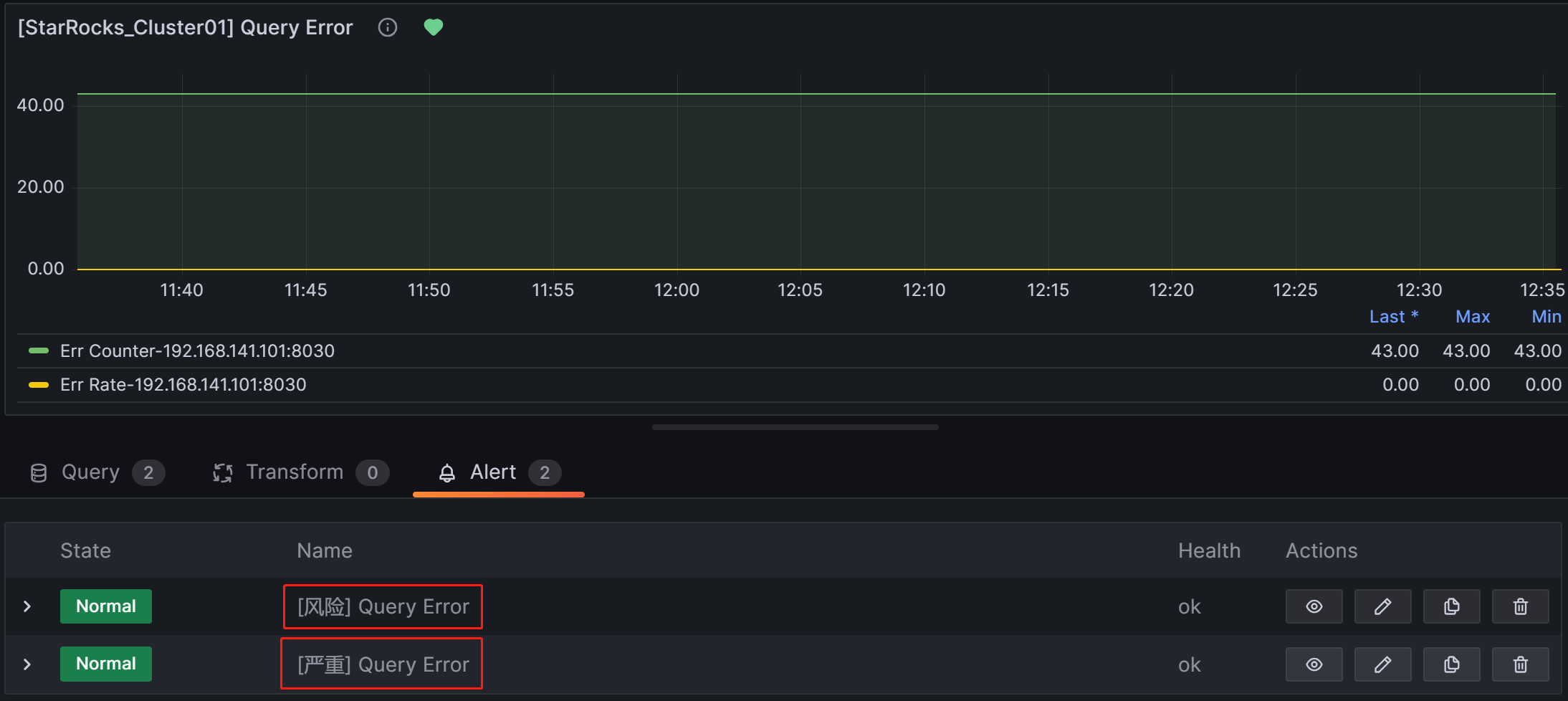
Grafana中实现告警分级的方法有比较多,这里补充一种实现比较简单的,以Query Error项为例,我们可以为其创建两个告警规则,设置不同的告警阈值,例如:
风险: 失败率>0.05,提示为风险,告警发送给开发组;
严重: 失败率>0.20,提示为严重,告警发送给运维组。因失败率大于0.2时自然就大于0.05,所以此时开发组和运维组都会收到告警通知。
结束语:本指南是结合业务对StarRocks配置监控告警的归纳整理,让社区的小伙伴可以不用在网上东拼西凑的找实现方式。若文档中存在描述不正确或不规范的地方,欢迎社区同学指正。
