背景
我们经常会遇到fe或者be服务内存占用比较多的情况,本文分享下怎么排查内存被哪些对象占用
排查思路
fe 内存分析
因为fe是java程序,所以一般分析内存占用,可以使用以下指令
查看 gc 是否频繁
jstat -gcutil $pid 1000 1000
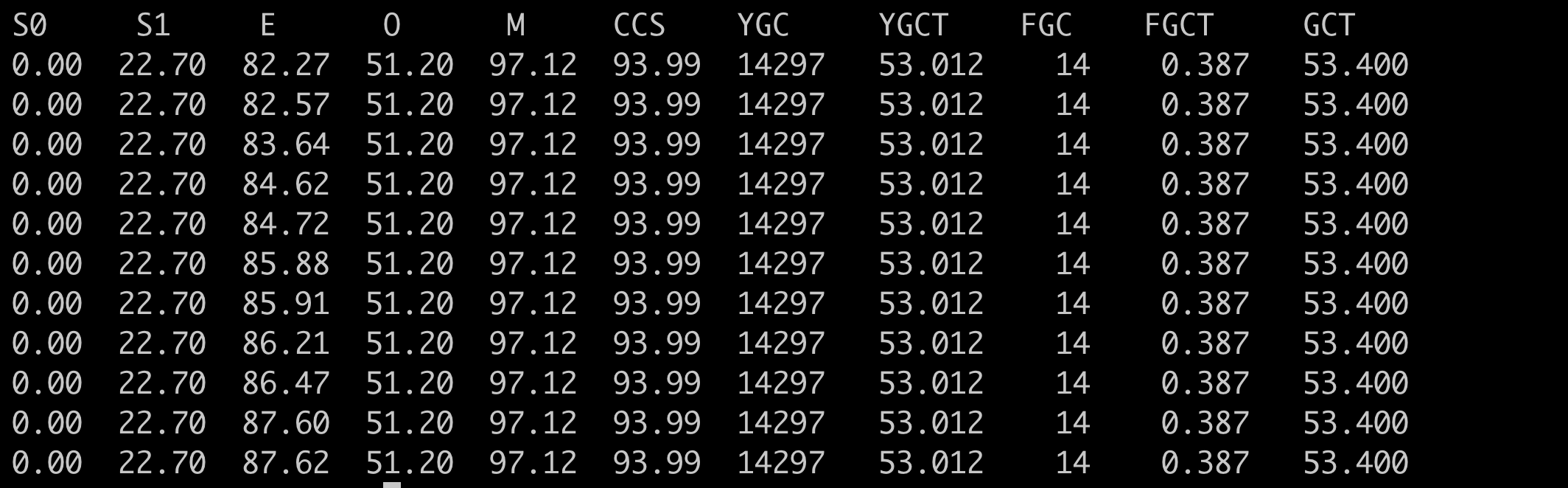
S0 — 新生代中Survivor space 0区已使用空间的百分比
S1 — 新生代中Survivor space 1区已使用空间的百分比
E — 新生代已使用空间的百分比
O — 老生代已使用空间的百分比
M — 元数据区使用比例
YGC — 从应用程序启动到当前,发生Yang GC 的次数
YGCT — 从应用程序启动到当前,Yang GC所用的时间【单位秒】
FGC — 从应用程序启动到当前,发生Full GC的次数
FGCT — 从应用程序启动到当前,Full GC所用的时间
GCT — 从应用程序启动到当前,用于垃圾回收的总时间【单位秒】
如果 S0 S1 E 这三个空间都有值的时候说明可能存在问题。因为正常情况下是每次GC后,S0区、S1区中的空间总有一个是会被完全清空(根据GC垃圾回收算法),因此S0 S1一直存在被占用时则回收不彻底,导致内存泄漏现象,随之时间拉长,甚至出现OOM
如果 FGC 一直在持续增长,说明有内存一直在申请或者没有释放,这个时候需要获取dump分析是哪些对象占用内存多
jmap -histo pid是一个比较轻量的命令,用于查看各个对象的内存统计。
注:如果只看常驻内存的对象,要加
:live参数:jmap -histo:live pid,但是加上:live之后会触发full gc,对于内存使用比较大的进程,卡顿会很明显,生产环境慎用
be 内存分析
 2.0以后的版本,一般不会再出现be服务oom的问题,如果出现则一般是因为以下两个问题
2.0以后的版本,一般不会再出现be服务oom的问题,如果出现则一般是因为以下两个问题
- 基础环境参数配置不正确,例如swap未关闭、overcommit配置不正确,详情见 https://docs.starrocks.io/zh/docs/deployment/environment_configurations/
- be服务和其他服务混合部署,BE 的配置文件 (be.conf) 中 mem_limit 配置不合理,默认是机器内存的90%,如果和其他服务混合部署,需要配置mem_limit=(机器总内存-其他服务占用内存-1~2g(系统预留))
比如机器内存40G,上面有个Mysql,理论上限会用4G,那么配置下mem_limit=34G (40-4-2)
建议配置 prometheus+grafana监控,可以很直观的看到各个模块内存变化的趋势,参考 StarRocks监控报警配置指南
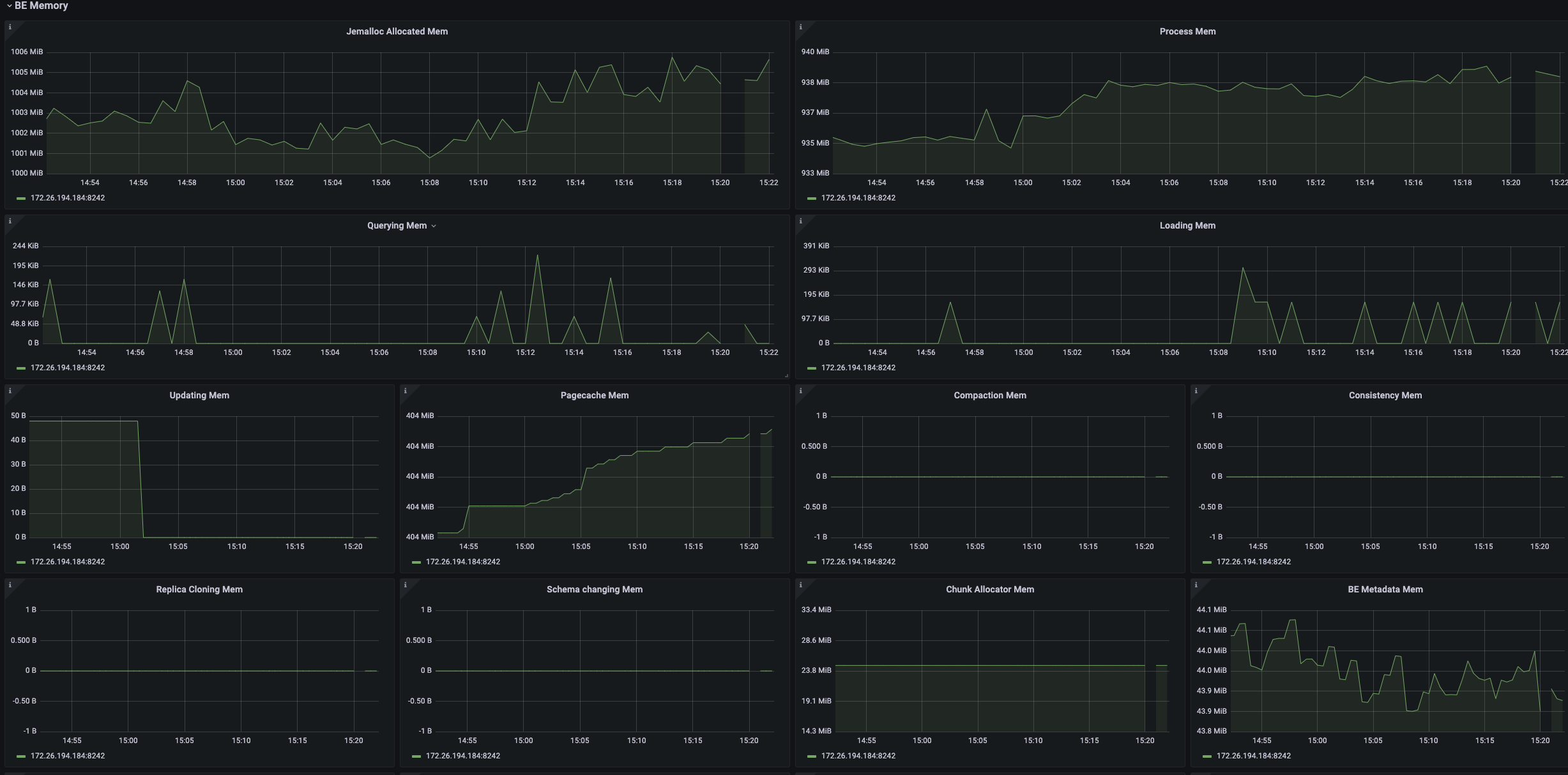
另外be也可以通过如下几个手段分析当前内存占用情况
1.metrics接口
curl -XGET -s http://BE_IP:BE_HTTP_PORT/metrics | grep "^starrocks_be_.*_mem_bytes\|^starrocks_be_tcmalloc_bytes_in_use"
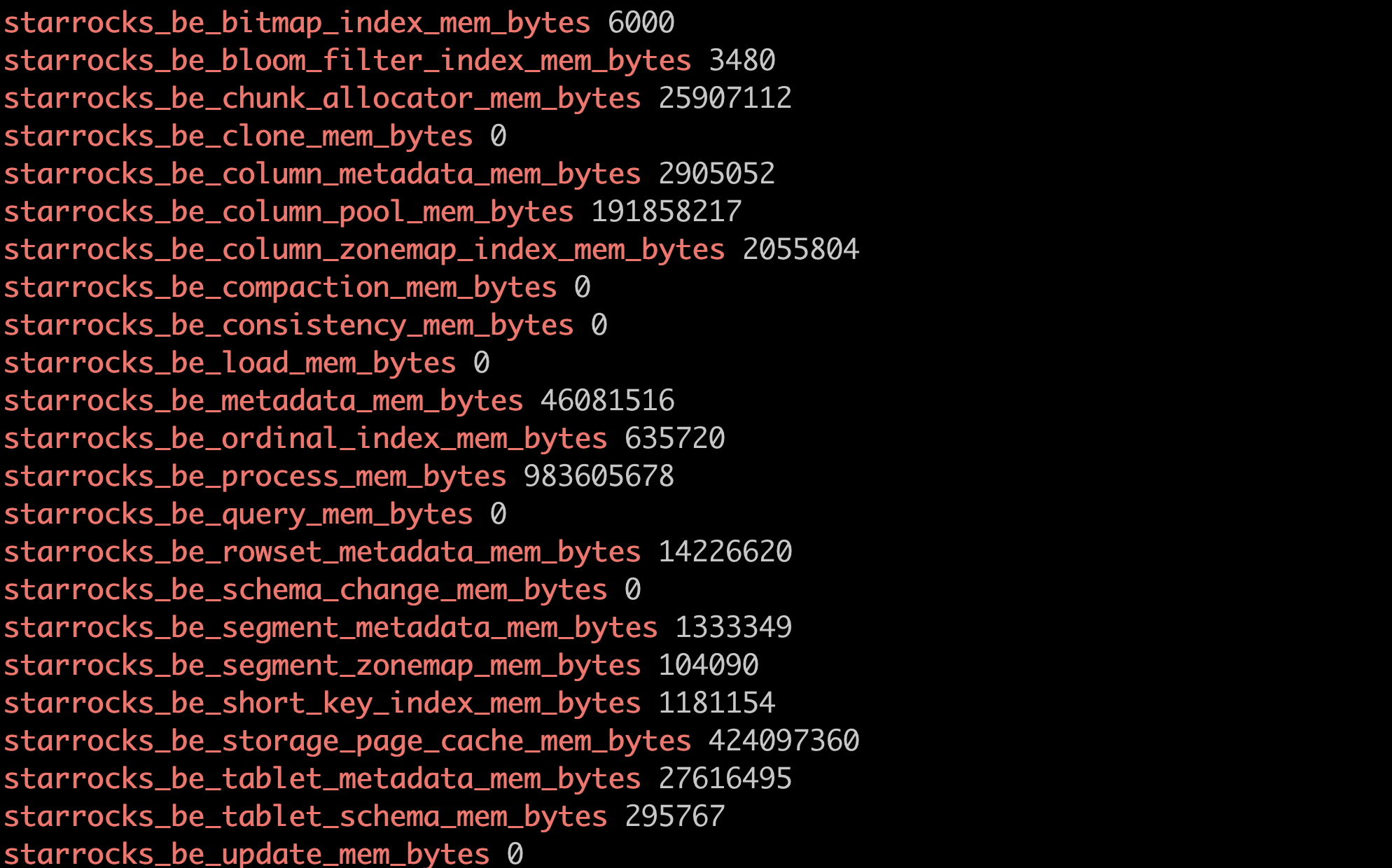
主要关注以下指标
starrocks_be_clone_mem_bytes 0 ## clone tablet 使用的内存, 内存使用一般比较小
starrocks_be_compaction_mem_bytes 0 ## Compaction 内存使用
starrocks_be_load_mem_bytes 0 ## 导入内存使用
starrocks_be_process_mem_bytes 95674408 ## 我们内存统计的 BE 进程内存使用
starrocks_be_query_mem_bytes 0 ## 查询内存使用
starrocks_be_schema_change_mem_bytes 0 ## SchemaChange 内存使用
starrocks_be_storage_page_cache_mem_bytes 0 ## BE 自有 StoragePageCache 内存使用
starrocks_be_tablet_meta_mem_bytes 14249776 ## Tablet 元数据内存使用
starrocks_be_update_mem_bytes 0 ## PrimaryKey 模型内存使用
2.mem_tracker接口
http://be_ip:8040/mem_tracker
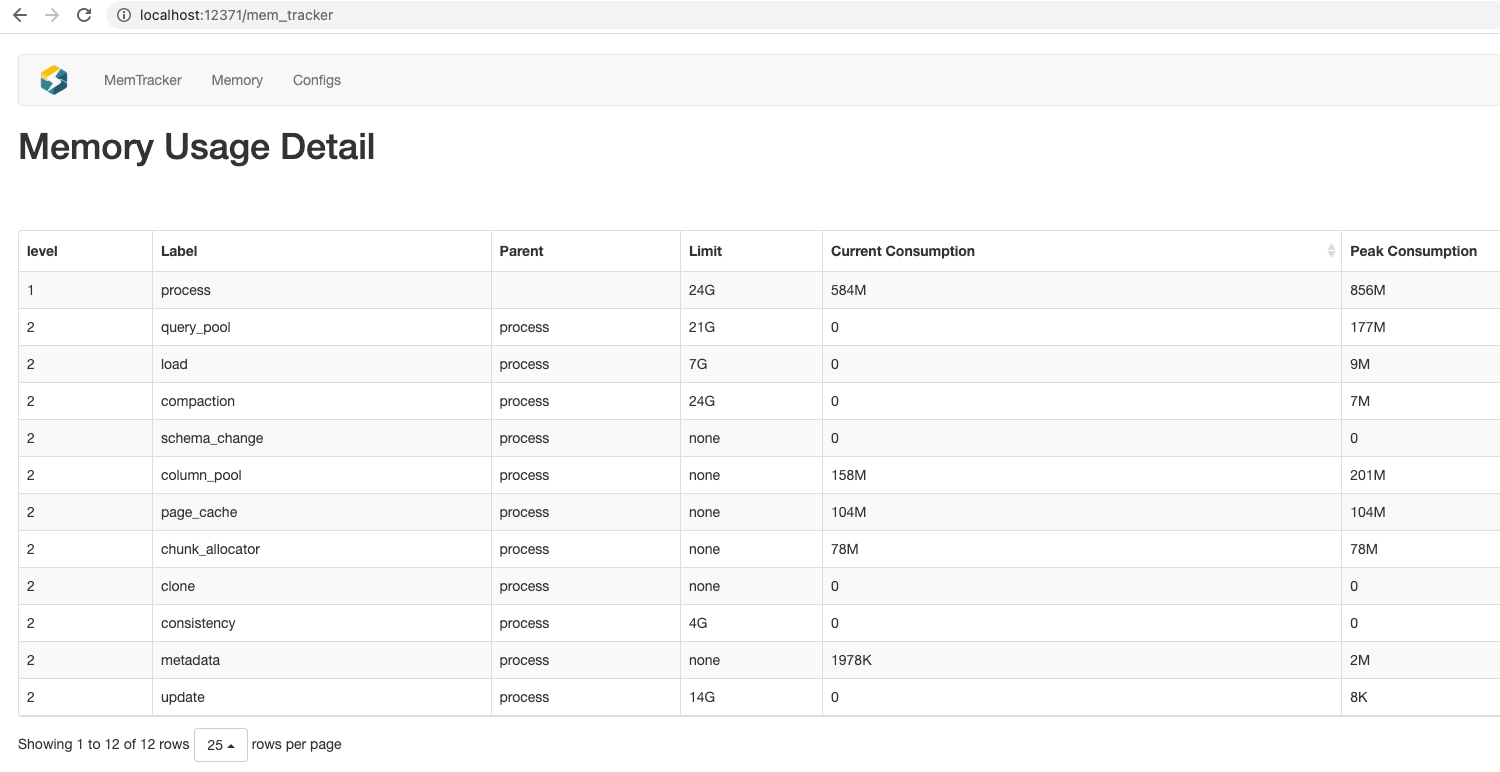
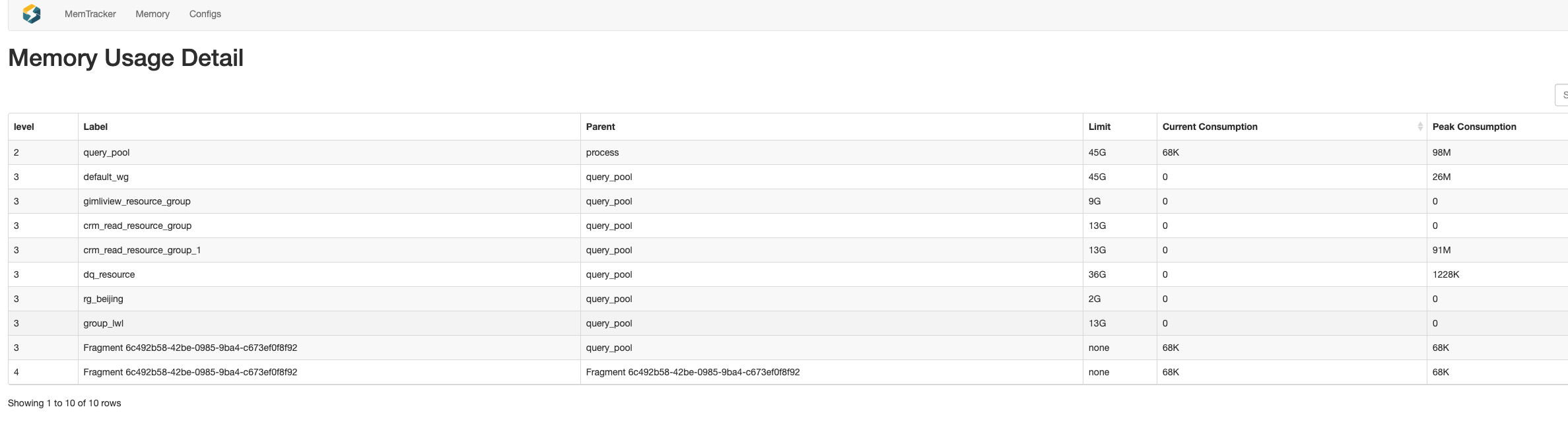
进一步查看当前有哪些查询占比高
http://be_ip:8040/mem_tracker?type=query_pool&upper_level=5
进一步查看主键模型哪些占用高
http://be_ip:8040/mem_tracker?type=update&upper_level=4

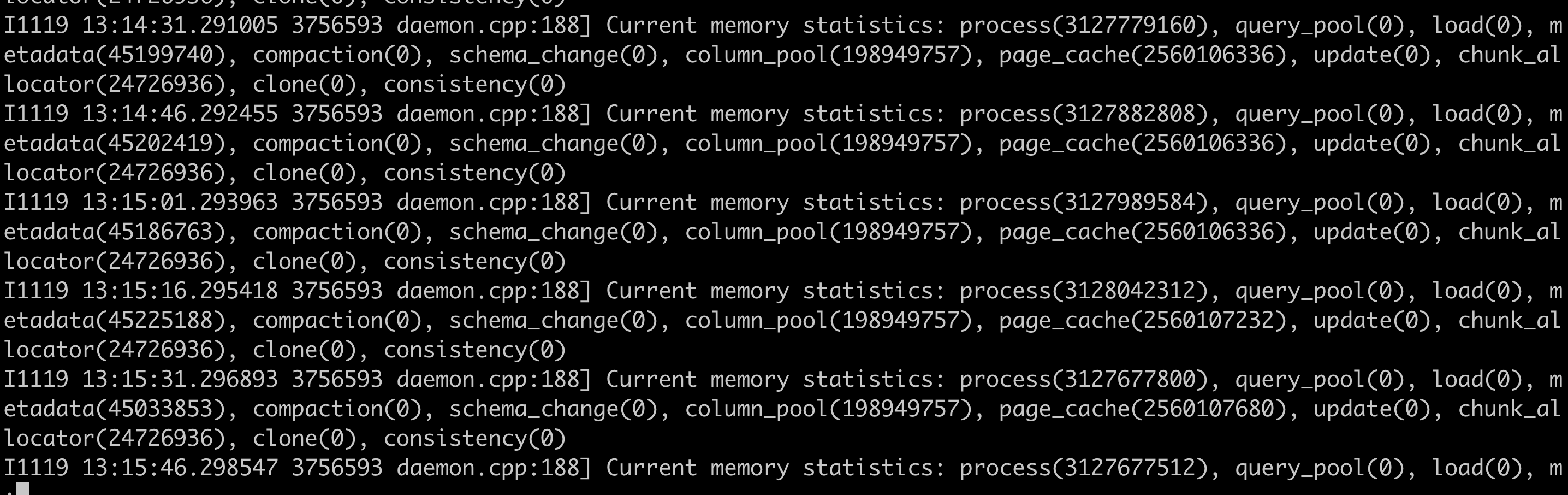
3.be日志
目前be.INFO中会每间隔15s统计当前各个模块内存占用
grep "Current memory statistics" be.INFO|less