
一、背景
在生产每天定时调度脚本,将hive数据100多个张表使用broker load导入StarRocks,每天使用show load去查询导入是否有导入失败的表,这样操作较为繁琐
使用Prometheus+Grafana监控,实现broker load导入报错自动发送邮件告警
测试发现,Stream load、insert load、Routine load皆可用此方式进行自动发送导入报错告警
二、Prometheus+Grafana监控安装
安装:参考论坛地址:Prometheus+Grafana部署及监控模板配置 这篇文档部署
模板:使用的监控Grafana模版(支持内存细粒度监控),论坛地址:Grafana模版(支持内存细粒度监控)
三、设定Grafana告警自动发送邮件或者钉钉通知
1.Grafana版本必须是4.0+才支持报警功能,具体相关安装教程也可以见参考网上教程
首先编辑Grafana配置文件 vi /etc/grafana/grafana.ini
在[smtp] 标签下 修改配置
#################################### SMTP / Emailing ##########################
[smtp]
enabled = true
host = xx.xx.xx.xx:25
user = xx@xx.com
####### If the password contains # or ; you have to wrap it with triple quotes. Ex “”"#password;"""
password = yourpassword
;cert_file =
;key_file =
skip_verify = true
from_address = xx@xx.com
from_name = Grafana
EHLO identity in SMTP dialog (defaults to instance_name)
;ehlo_identity = dashboard.example.com
######### SMTP startTLS policy (defaults to ‘OpportunisticStartTLS’)
;startTLS_policy = NoStartTLS
#################################### Logging ##########################
保存好配置文件之后,重启Grafana
systemctl restart grafana-server
2.进入Grafana界面设置告警
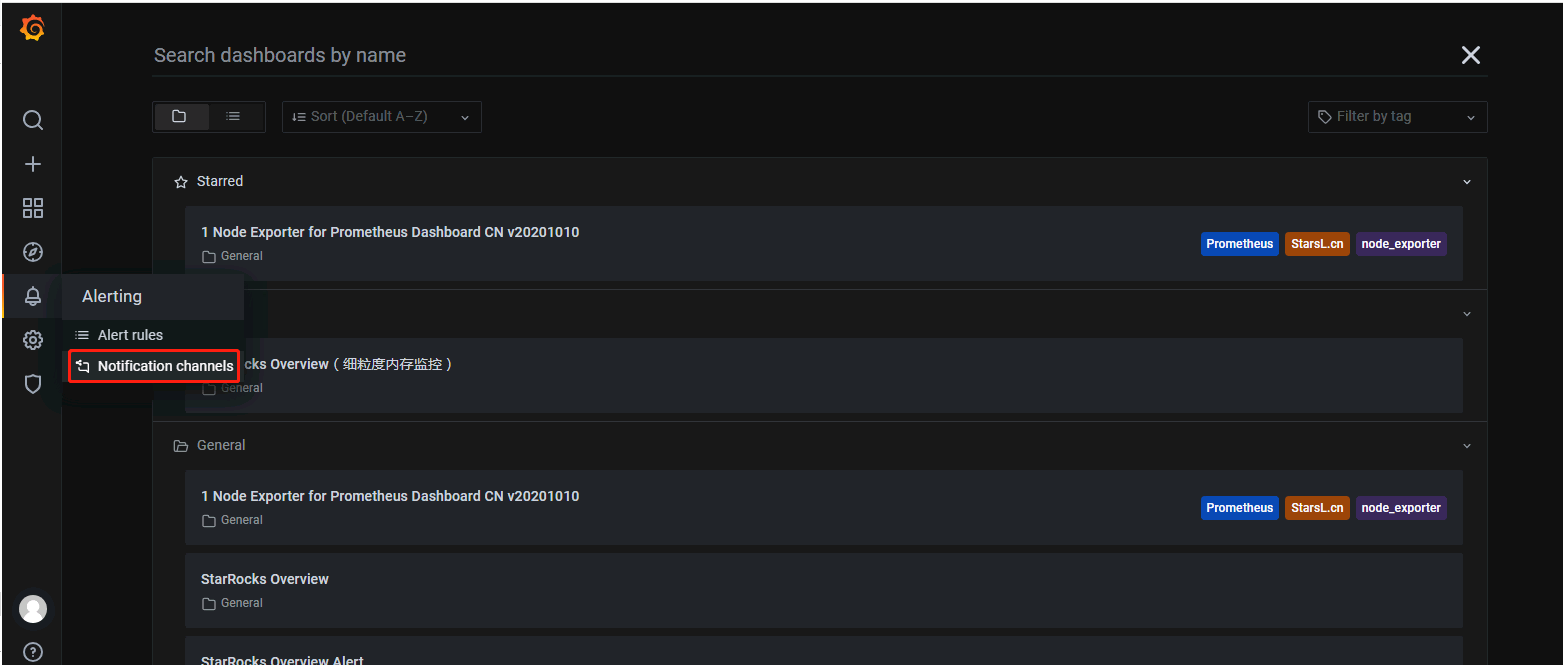
- 配置配置Notification channels
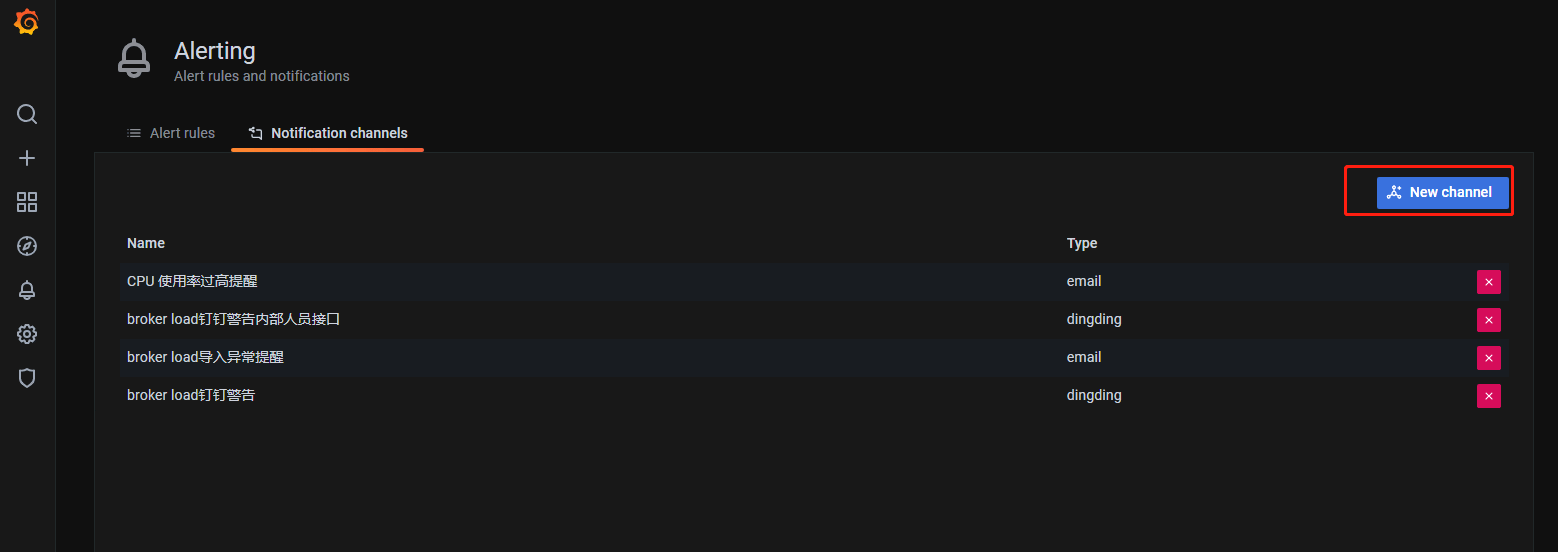
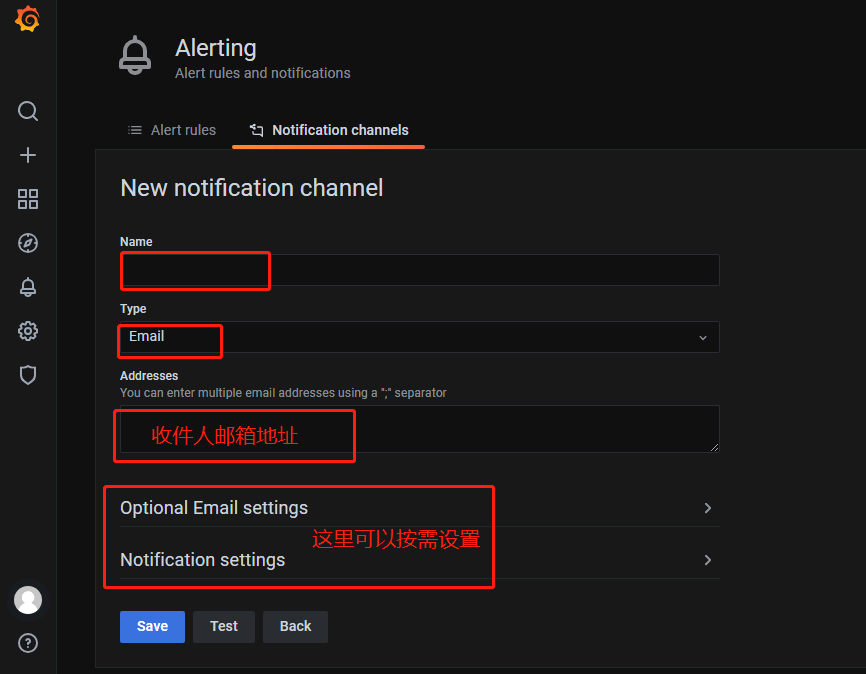
4.填写告警相关信息
填写告警名称、通知方式、收件地址
点击测试,如果出现如下图所示,显示连通正常
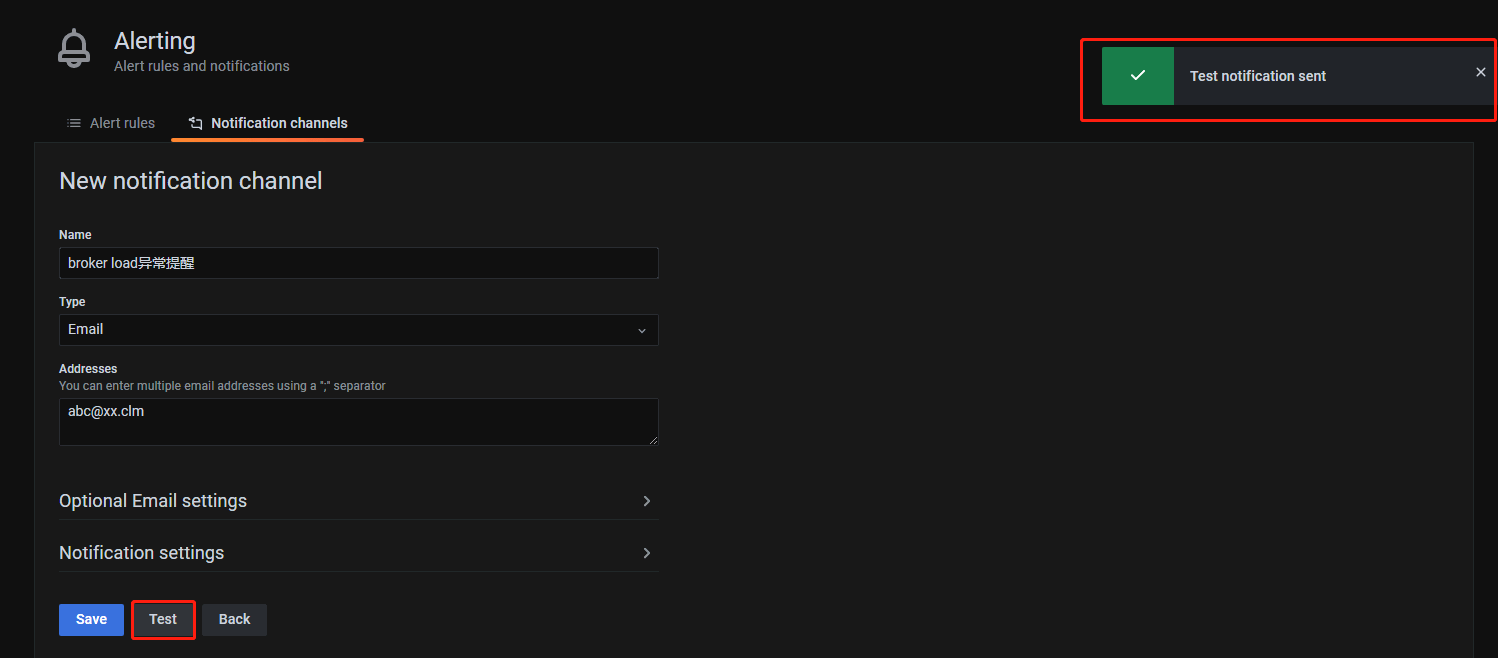
然后点击send Test ,提示成功后,刚填写的邮箱应该就可以收到如下内容的测试邮件
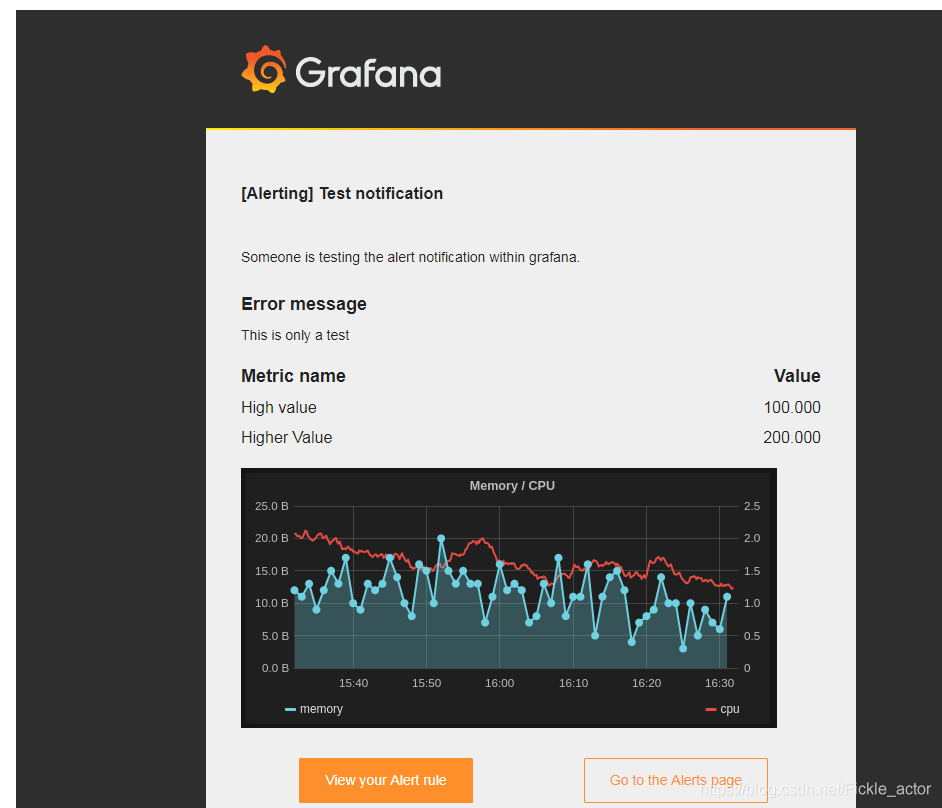
测试发送邮件,如果执行出错,可进一步查看日志
tail -f /var/log/grafana/grafana.log
5.添加 Alert Rules
首先到进入dashboard页面,左键点击你想添加Alert告警的 graph 面板的面板名,并点解 EDIT,进入面板编辑页面。
注意:只有graph panel 也就是图表面板(一般都是折线图和柱状图或者点状图)可以添加Alert ,其他面板不支持。
选择StarRocks Overview(细粒度内存监控)模板
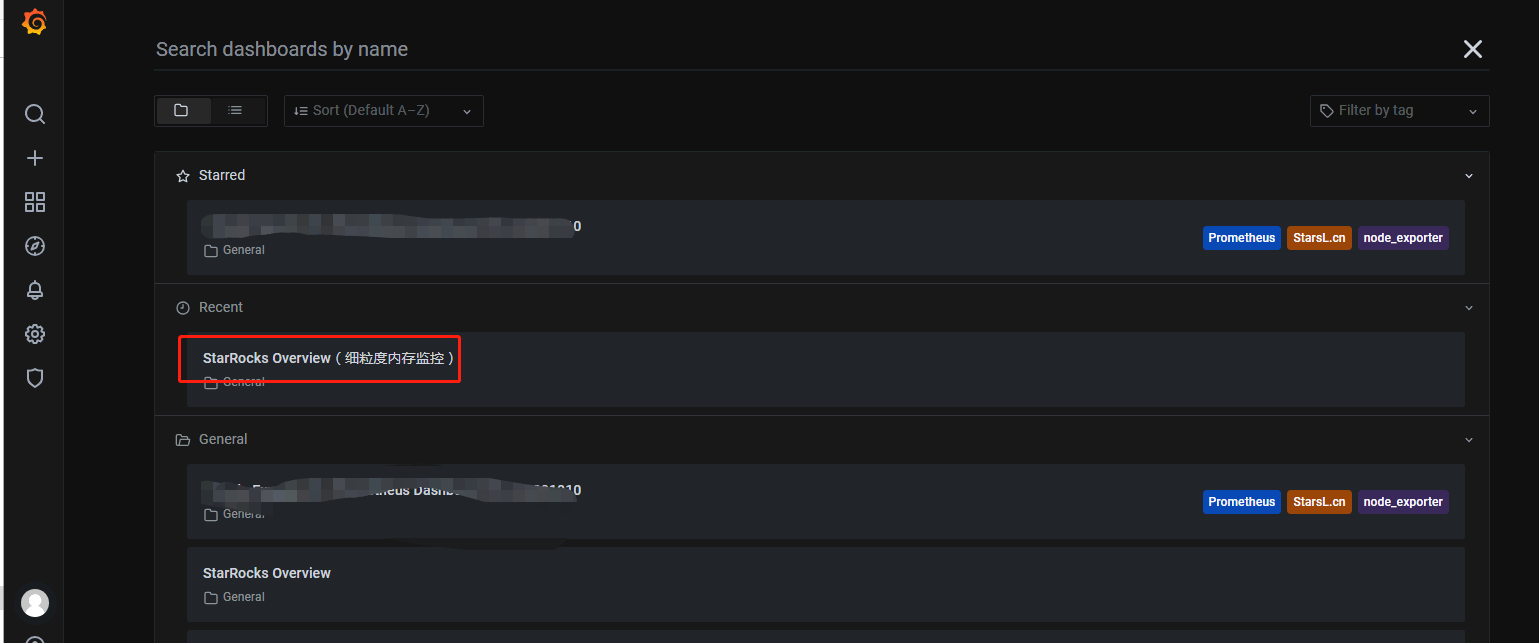
复制broker _load tendency面板
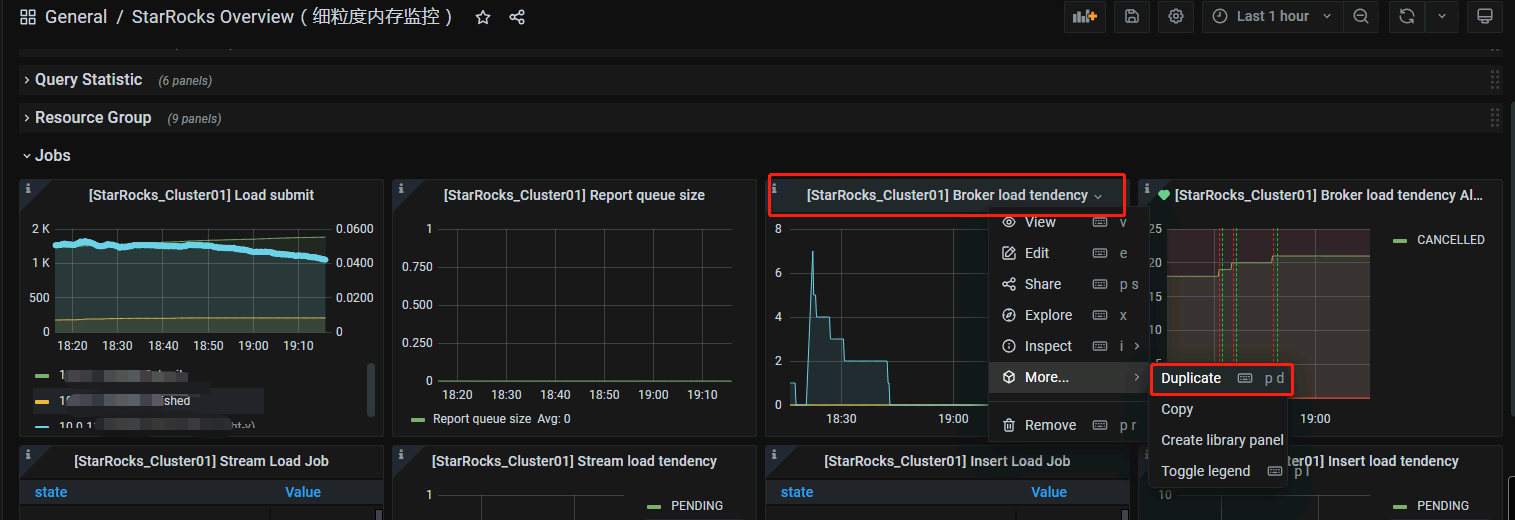
使用复制面板,选择inspect–panel JSON 修改监控脚本
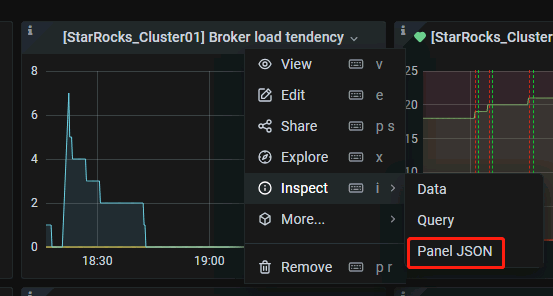
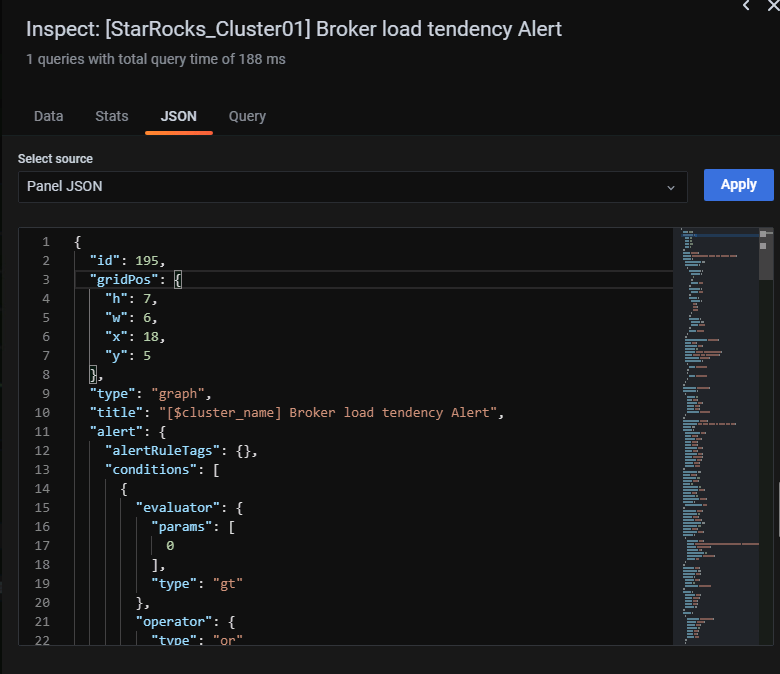
由于我们只需监控broker load导入状态为cancelled的失败记录,其他导入状态删除,主要的修改的JSON为如下内容,

具体如下
{
“id”: 195,
“gridPos”: {
“h”: 7,
“w”: 6,
“x”: 18,
“y”: 5
},
“type”: “graph”,
“title”: “[$cluster_name] Broker load tendency Alert”,
“alert”: {
“alertRuleTags”: {},
“conditions”: [
{
“evaluator”: {
“params”: [
0
],
“type”: “gt”
},
“operator”: {
“type”: “or”
},
“query”: {
“params”: [
“A”,
“1m”,
“now”
]
},
“reducer”: {
“params”: [],
“type”: “diff”
},
“type”: “query”
}
],
“executionErrorState”: “alerting”,
“for”: “0m”,
“frequency”: “1m”,
“handler”: 1,
“message”: “broker load瀵煎叆鎶ラ敊閫氱煡”,
“name”: “Broker load 瀵煎叆鎶ラ敊璀﹀憡”,
“noDataState”: “no_data”,
“notifications”: [
{
“uid”: “YmjjCiWSz”
},
{
“uid”: “bhmhHKZSk”
}
]
},
“datasource”: “Prometheus”,
“thresholds”: [
{
“value”: 0,
“op”: “gt”,
“visible”: true,
“fill”: true,
“line”: true,
“colorMode”: “critical”
}
],
“pluginVersion”: “8.0.0”,
“description”: “The trend report of broker load job”,
“links”: [],
“legend”: {
“alignAsTable”: true,
“avg”: false,
“current”: false,
“max”: false,
“min”: false,
“rightSide”: true,
“show”: true,
“sideWidth”: null,
“sort”: “current”,
“sortDesc”: true,
“total”: false,
“values”: false
},
“aliasColors”: {},
“bars”: false,
“dashLength”: 10,
“dashes”: false,
“fill”: 1,
“fillGradient”: 0,
“hiddenSeries”: false,
“lines”: true,
“linewidth”: 1,
“nullPointMode”: “null”,
“options”: {
“alertThreshold”: true
},
“percentage”: false,
“pointradius”: 5,
“points”: false,
“renderer”: “flot”,
“seriesOverrides”: [],
“spaceLength”: 10,
“stack”: false,
“steppedLine”: false,
“targets”: [
{
“exemplar”: true,
“expr”: “starrocks_fe_job{job=“xx”, exported_job=“load”, type=“BROKER”, instance=“xx”, state=“CANCELLED”}”,
“format”: “time_series”,
“interval”: “”,
“intervalFactor”: 1,
“legendFormat”: “CANCELLED”,
“refId”: “A”
}
],
“timeFrom”: null,
“timeRegions”: [],
“timeShift”: null,
“tooltip”: {
“shared”: true,
“sort”: 0,
“value_type”: “individual”
},
“xaxis”: {
“buckets”: null,
“mode”: “time”,
“name”: null,
“show”: true,
“values”: []
},
“yaxes”: [
{
“$$hashKey”: “object:1385”,
“format”: “short”,
“label”: null,
“logBase”: 1,
“max”: null,
“min”: “0”,
“show”: true
},
{
“$$hashKey”: “object:1386”,
“format”: “short”,
“label”: null,
“logBase”: 1,
“max”: null,
“min”: null,
“show”: false
}
],
“yaxis”: {
“align”: false,
“alignLevel”: null
}
}
保存,正常显示如下
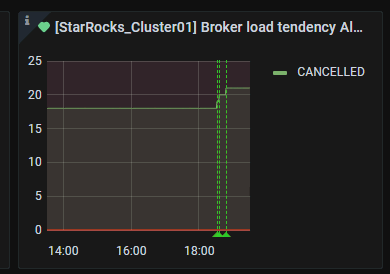
配置borker load导入失败告警
填写相关信息如下
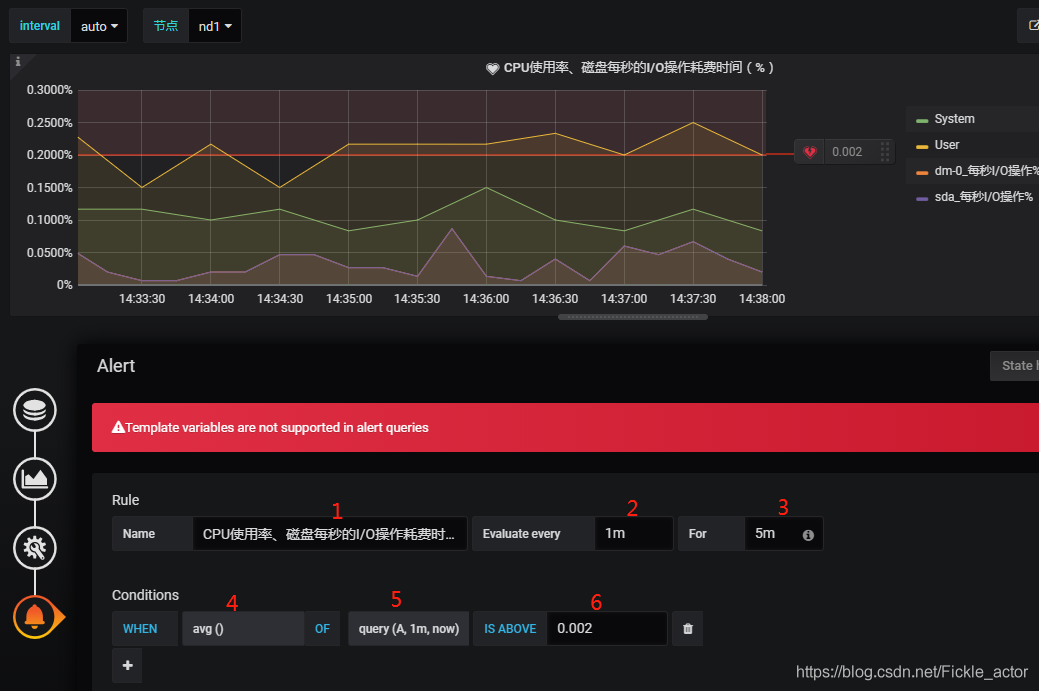
这里解释下上图中六个参数的作用
1.Rule Name :Alert规则 的名称
2 每多少时间评估一次
3的输入框里有个提示的图标,鼠标移上去会看到提示,提示的
大概意思是:如果配置了这个参数,那么当查询结果超过阀值的时候,首先会从ok状态转到pedding状态,此时是不会发邮件的,而当 超过阀值的状态的持续时间 过了配置的持续时间时,才会从pending 状态 转成 Alerting状态,并发送通知邮件
在上图中我设置的是Evaluate every 1m for 5m, 也就是说每分钟计算一次是否超过阀值,如果超过阀值的时间持续了5分钟,就发送邮件通知,如果没有的话,只是从ok 状态转为 pedding状态.
发送了通知之后还是会每分钟检查一次,状态恢复正常之前是不会再发邮件的。
而且我们配置的prometheus还有个拿数据的时间间隔,这个也会影响数据的计算。
4、5、6为触发Alert的条件
4是查询的类型,可选项有很多,最大值、最小值、平均值等等
5.这里有三个参数 , 第一个是查询的编号,这个是在Queries里面设置的,稍后再讲,每个查询在每个时间点的结果值就构成了我们看到的图。 第二个是多少时间内, 第三个是开始时间
6. 是阀值
上图的配置简单来说就是 :
A查询从当前时间开始的1分钟内的结果值的平均值如果高于阀值0.002,将会从ok状态 转变为 pedding状态,但不会发邮件,然后每分钟查询一次,如果高于阀值的持续时间超过五分钟,就会发邮件通知。
我的配置如下:
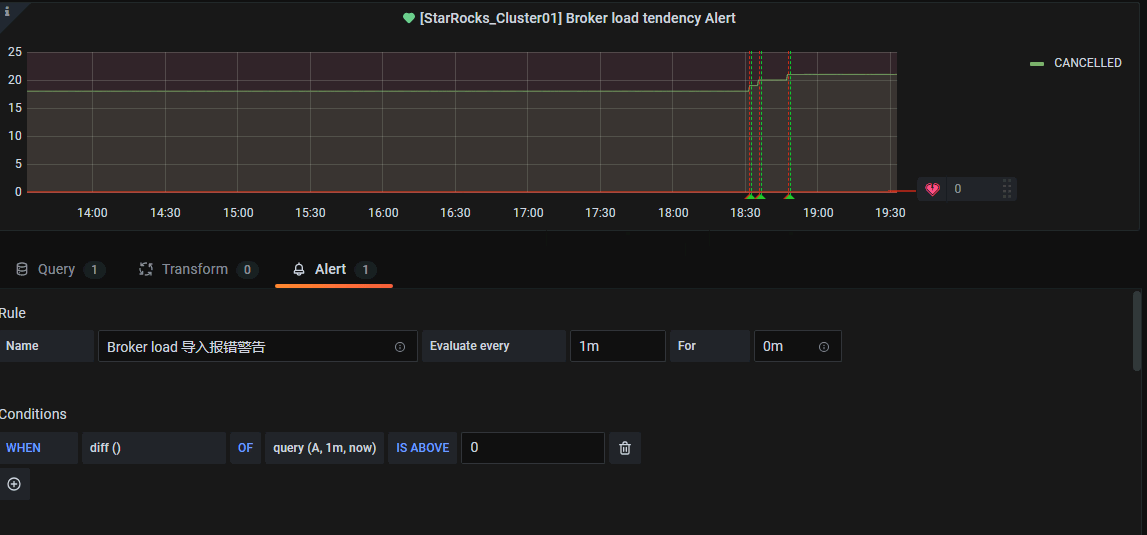
在send to 这里配置选择告警通道,第3点配置的那个
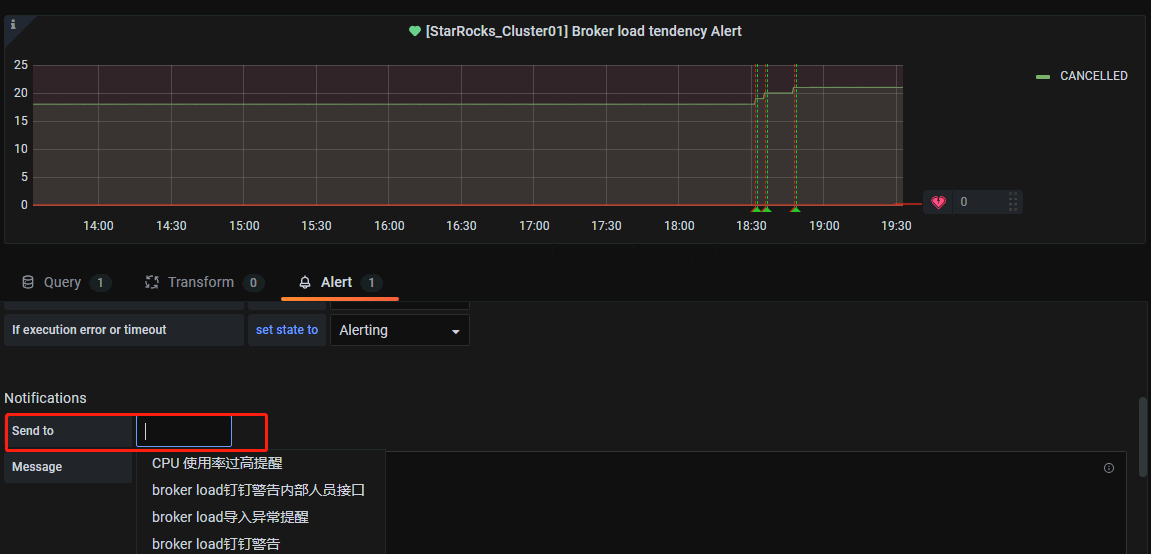
四、测试告警情况
随便broker load导入,让其主动报错,邮件收到告警如下:
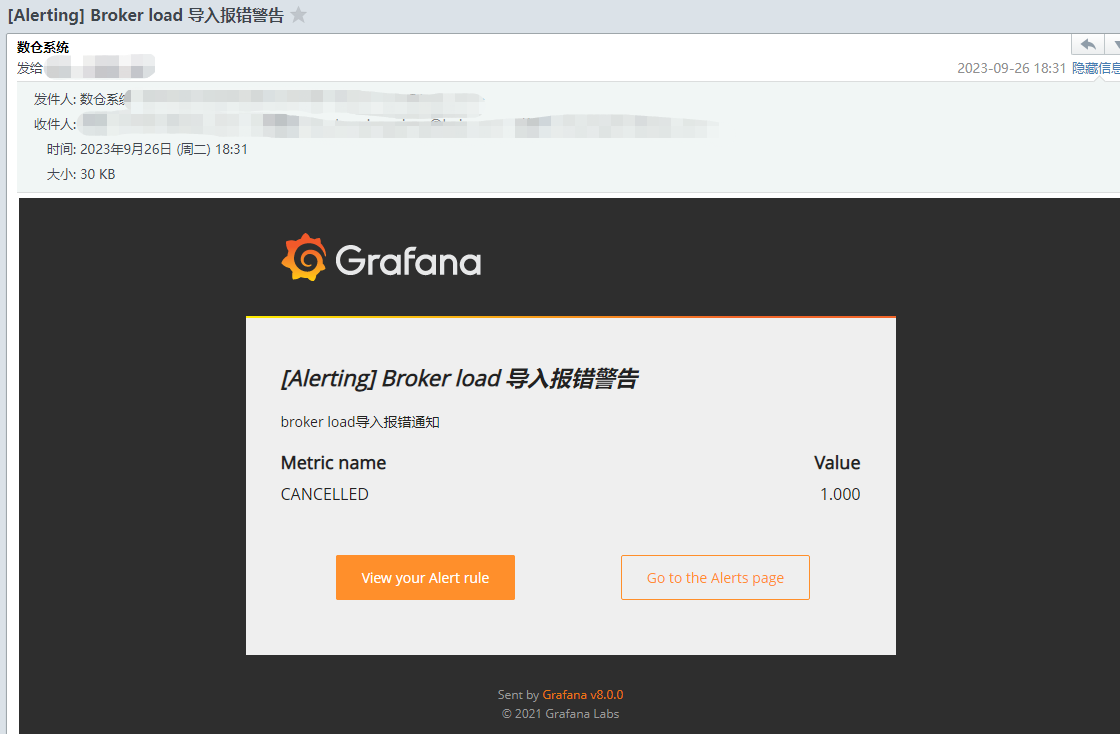
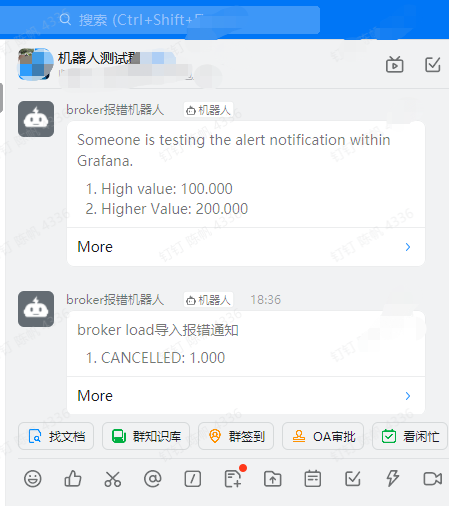
五、切换告警方式为钉钉,无需修改配置grafana.ini文件,其他设置基本与上述配置的邮件方式类似
需要配置钉钉机器人的url地址即可,具体钉钉机器人开通方式可在钉钉官网查看
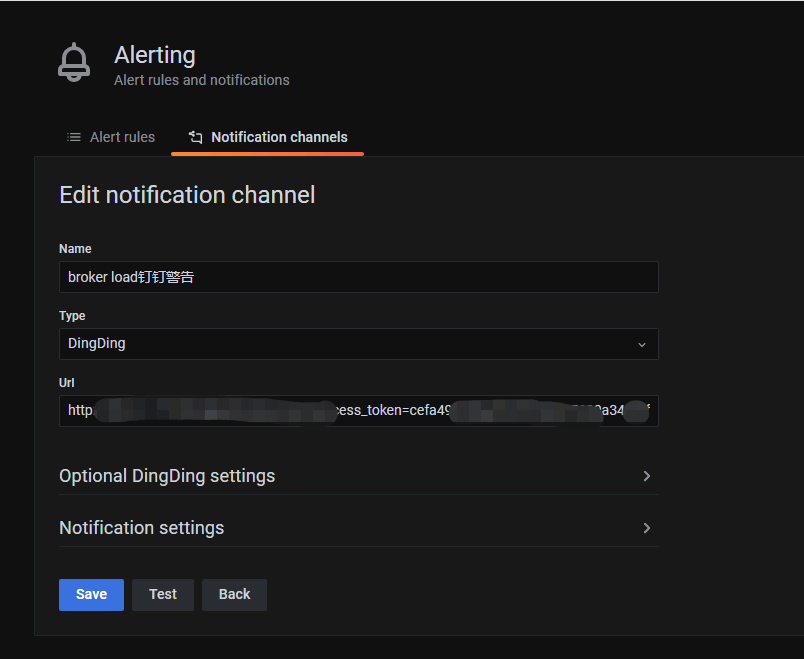
钉钉警告自动收到的信息如下所示
六、完结。