
为了更快的定位您的问题,请提供以下信息,谢谢
【详述】datapipeline导数
【背景】导主键模型表日志报错
【业务影响】没影响
【StarRocks版本】2.5.13
【集群规模】3fe(2 follower、1 master)+4be(fe与be混部)
【机器信息】16C/16G/万兆
【表模型】主键模型
【导入或者导出方式】datapipeline
【联系方式】社区群13-麦咪
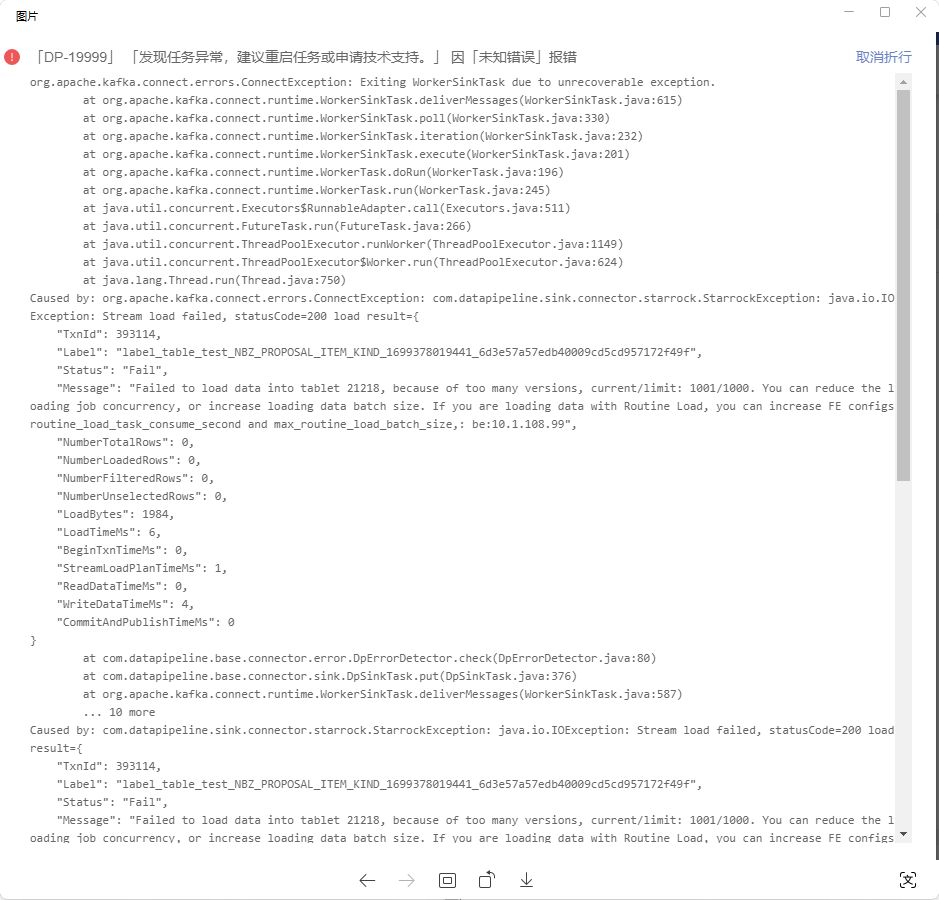
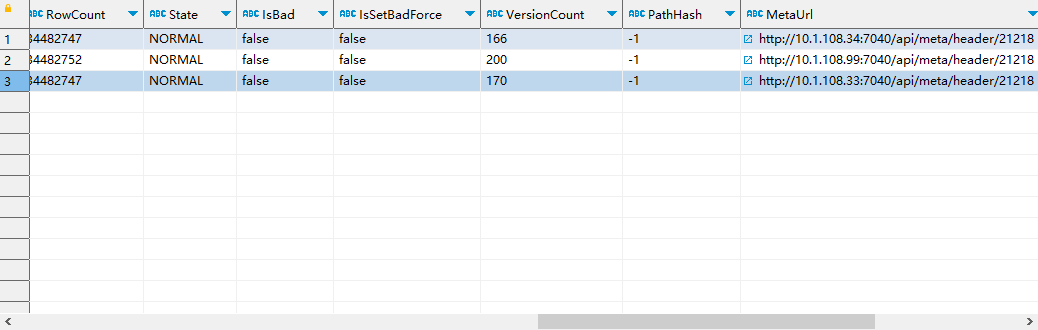
这个看起来是版本超过限制了,默认1000。可以show tablet 21218;然后执行下DetailCmd,看下输出结果里各个副本的versioncount是多少。
导入的时候需要配置下sink的参数,一般建议10秒以上sink一次
我叫厂商那边能不能调整一下导入频率,这是datapipeline去导的
这个看起来已经降下去了,应该是sink的频率太高导致的,可以调整下,应该都有参数可以调整的
starrocks这边有没有什么参数控制的呢
主要还是调大些sink的频率。starrocks这边可以稍微调高一些compaction的参数加快合并,如果当前be负载不高的话,比如be的update_compaction_num_threads_per_disk和update_compaction_check_interval_seconds
第一个调大,第二个调小是吗
对的,但要注意集群负载
这个会消耗CPU资源吗,还是内存资源呢
CPU、IO、内存都会有消耗
技术老师,问一下compaction机制是怎么样的,是磁盘还是内存的compaction呢
compaction要读取磁盘上的rowset文件,加载到内存里进行文件的合并,并生成新的rowset文件,最后要写回到磁盘上,compaction会消耗IO、内存、CPU资源。
嗯嗯,这个是在什么情况下才会触发呢,一导数就会吗,跟表的数据模型有关系吗
每批次导入的数据会生成一个rowset。 Compaction 分为两种类型:base compaction 和 cumulative compaction。其中 cumulative compaction 则主要负责将多个最新导入的 rowset 合并成较大的 rowset,而 base compaction 会将 cumulative compaction 产生的 rowset 合入到 start version 为 0 的基线数据版本(Base Rowset)中,是一种开销较大的 compaction 操作。compaction的触发机制比较复杂,但一般情况下,新的数据导入较多批次会触发compaction。不同表的数据模型也有不一样的compaction机制,主要是主键模型和其他模型的机制差异,这块比较复杂,目前暂时没有解读的文章,感兴趣的话只能先看看源码了
好的了解,谢谢。
技术老师,有什么参数可以调整导数的速度,现在生产环境4台be节点256G/128C的配置,一张112822255的主键表,全量导了十多小时这种速度正常吗太慢了吧
是的这个太慢了,你们是怎么导的,sink的参数怎么配置的,期间集群的资源使用怎么样?
datapipeline工具导的,就建表导数,没设置什么配置,就一个攒批写,5000条写一次