一般是有三个参数控制的,sink批次的间隔(interval)、sink批次的行数(rownum)、sink批次的数据size(size),三个参数哪个先达到就进行一次sink写入。如果导入期间集群压力不大的话,可以把interval调到15秒,rownum调到1w行,size调到100MB这样。

另外也可以看下数据远端读取的速度是否和写入速度匹配,比如瓶颈是不是在读取?
以及这个表是怎么建的,分桶数怎样,是否包含比较多的大字段?1亿多行的话存储占用多少

一般是有三个参数控制的,sink批次的间隔(interval)、sink批次的行数(rownum)、sink批次的数据size(size),三个参数哪个先达到就进行一次sink写入。如果导入期间集群压力不大的话,可以把interval调到15秒,rownum调到1w行,size调到100MB这样。
任务删掉了,找不到了,分桶数16,占存储22G,没有比较大的字段。昨天同时同步三张表分别17331042、112908951、208439295这么大,分桶数16、32、32,占用空间566MB、20GB、16GB,改成这样的设置好像快一些了 ,这个分桶数有什么要求吗,有没有什么限制之类的
,这个分桶数有什么要求吗,有没有什么限制之类的
一般导入后的数据/3副本/分桶数在1G左右为宜。现在同步的速度大概怎样,可以看下grafana里的load rows。如果表比较大的话,使用分区表也会比较好
昨天大概是这个速度吧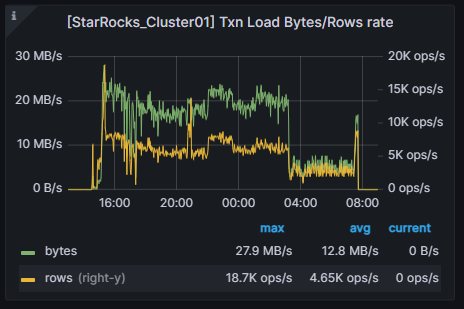 ,分区表还没涉及到,建表的分桶数设多少都可以的吧,如果这张表几百G分桶数是不是也要配几百个
,分区表还没涉及到,建表的分桶数设多少都可以的吧,如果这张表几百G分桶数是不是也要配几百个 
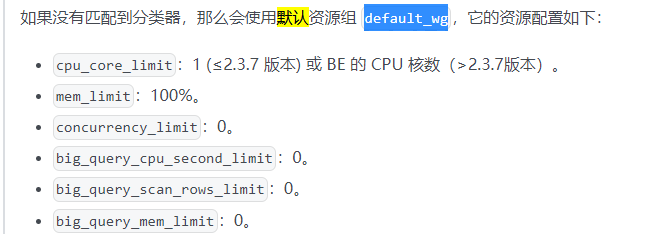
默认资源组应该是不显示的。
那我不创建资源组配这几个参数还有效吗
开启了资源组,不创建新的资源组,查询就会进入默认资源组。注意哟,低版本只能select语句才能进入。如果你是create table as xx select或者 insert into xx select 是进不去的。也就没办法控制资源,高版本insert可以控制。
2.5最新版本可以的吧
是的,2.5最新版可以