【详述】
问题现象: Routine Load导致CPU利用率突增(达到5000%以上)
起初以为是Routine Load导致的CPU突刺,后来经过各种排查和分析源码,最终定位到了是Checkpoint线程导致的CPU突刺:
查看FE日志,发现高峰时间段和Checkpoint时间非常吻合,每次Checkpoint的时候,必定出现CPU突刺,结合代码和其他日志,逐渐定位到原因:Checkpoint线程回放最近一段时间新增的journal的时候,也把journal中statistics相关的entry(OperationType.OP_ADD_BASIC_STATS_META)回放了,由此触发了statistics更新的过程,且是之前记录的journal堆积到了这一个时间点,此过程在集群上上会造成瞬时600个左右的statistics更新任务(因为Routine Load任务较多,且频繁更新表数据,所以触发的statistics统计任务也较多,这些统计任务都会被写到journal里面作为一条entry,在replay这些journal的时候,又被重复执行了),这些任务会被分发给BE执行,因此占用较高的CPU,造成突刺
不只是Routine Load,只要StarRocks中实时表过多(我们另外一个集群使用Flink写入很多表,也有突刺现象),就会造成这种现象
除了Checkpoint日志和突刺时间吻合之外,还有另外1个验证方式:关闭statistics自动收集:突刺现象消失
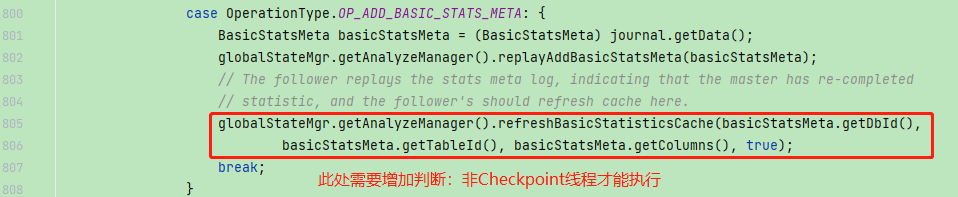
代码BUG:Checkpoint不应该触发statistics的更新,因为这些更新完成的统计信息只是临时的,Checkpoint完成之后就会被抛弃,属于无效更新;只有Follower节点才需要在replay这些journal的时候触发statistics的更新:
com.starrocks.persist.EditLog
修改代码,上线完成后,突刺消失:
下图中红框内为上线之前的突刺,代码于20:00上线,上线完成后,不再出现突刺现象

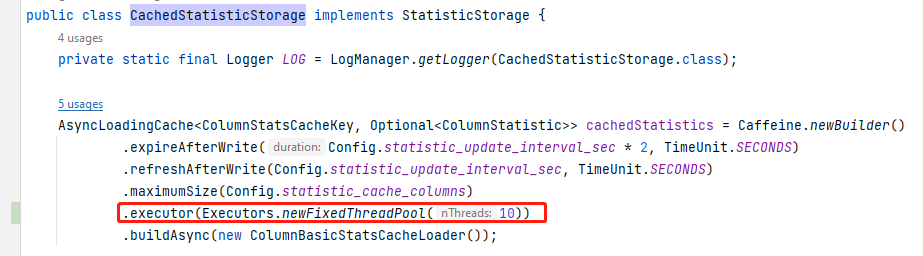
主要问题是,触发statistics自动全量收集的时候(其实准确点,不是收集而是刷新statistics缓存),是异步的 cache 实现的(com.starrocks.sql.optimizer.statistics.CachedStatisticStorage#getColumnStatistics),底层好像默认使用ForkJoinPool,而这个是没有做并发控制的,极端情况会用上很多线程(而手动创建的采集任务默认是3个并发控制: statistic_collect_concurrency,和这里自动的不同),有什么好办法可以避免这种情况吗?虽然修改代码后,我们的Checkpoint线程已经不再触发突刺了,但是未来不排除别的情况导致自动全量收集出现类似的堆积现象
【背景】做过哪些操作?
Create了1000个Routine Load Job,其中40个的并发task数目是3,其他均为1
【业务影响】
无
【StarRocks版本】
2.5.3
【集群规模】
3fe+3be(fe与be混部)
500GB内存,128 CPU核心
【表模型】
均为主键模型,Kafka的topic中UPSERT和DELETE操作都有
【导入或者导出方式】
Routine Load
【联系方式】
StarRocks社区群4-Matata
【附件】