
【详述】
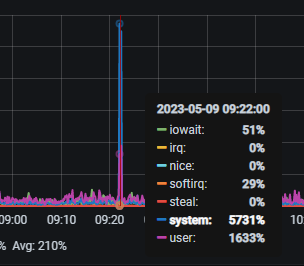
三台BE节点(500GB内存,128 CPU核心),每过一个小时左右就会有1~2分钟左右的CPU突刺,如下图
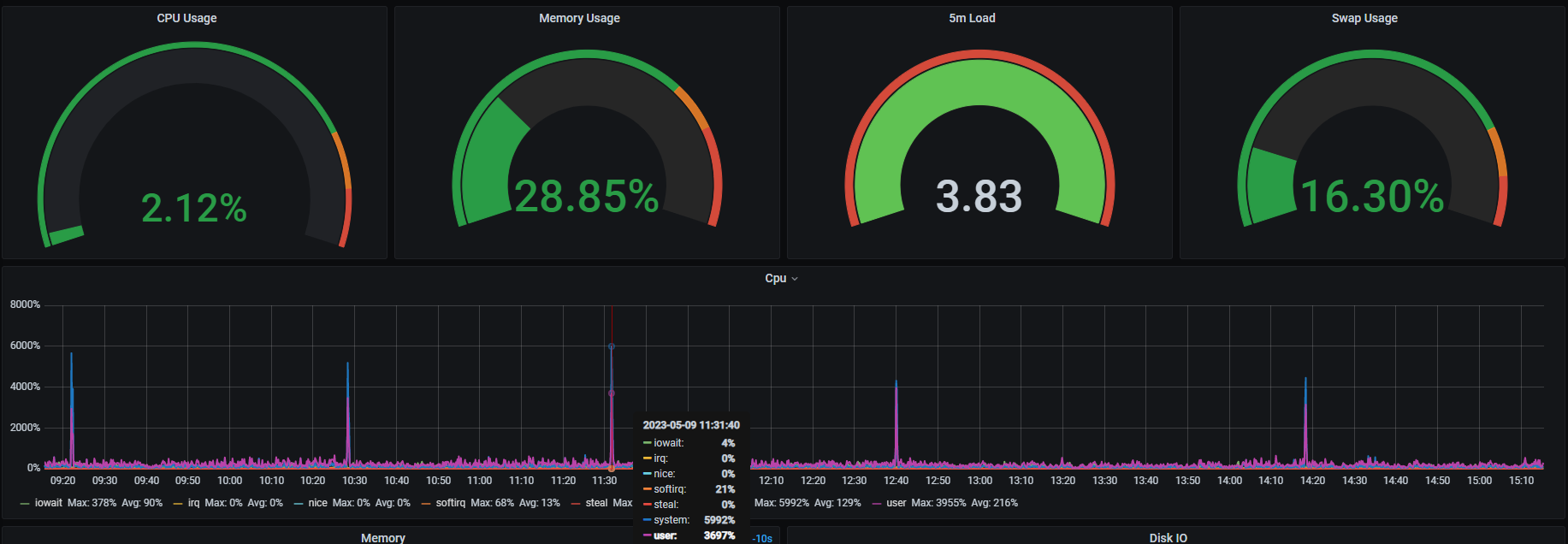
另外两台机器的监控情况也类似
我们的监控日志里面显示,这些CPU均是被BE进程占用了:
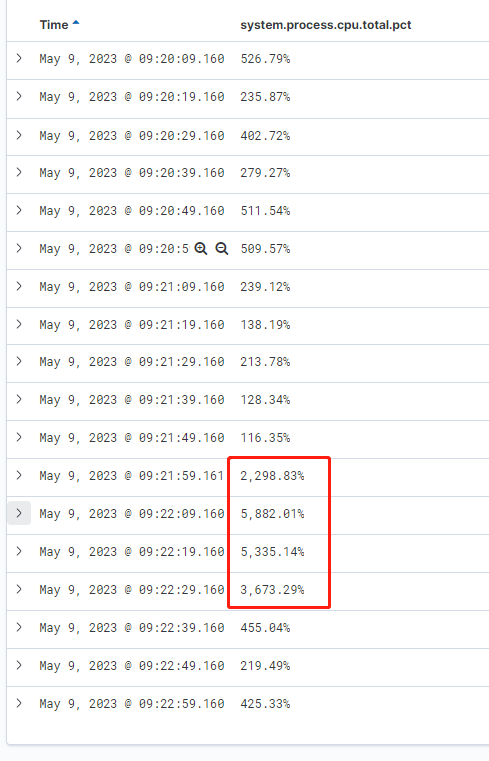
目前StarRocks中只有1000个通过Routine Load接入的实时表,基本无其他负载(新集群),所以初步判断是这些Routine Load任务导致的CPU利用率突增
再查看BE日志,发现每到高峰时,执行计划fragment数量就会突增,从500~2000左右增加到10000以上,日志内容大概如下:
I0508 20:53:14.277118 120646 fragment_executor.cpp:158] Prepare(): query_id=e0d4ac92-ee03-11ed-9009-e43d1a1b411c fragment_instance_id=e0d4ac92-ee03-11ed-9009-e43d1a1b411f backend_num=0
I0508 20:53:14.280663 120703 fragment_executor.cpp:158] Prepare(): query_id=e0d4ac92-ee03-11ed-9009-e43d1a1b411c fragment_instance_id=e0d4ac92-ee03-11ed-9009-e43d1a1b411e backend_num=2
I0508 20:53:14.356686 120533 fragment_executor.cpp:158] Prepare(): query_id=e0dff733-ee03-11ed-9009-e43d1a1b411c fragment_instance_id=e0dff733-ee03-11ed-9009-e43d1a1b411f backend_num=3
I0508 20:53:14.443708 120706 fragment_executor.cpp:158] Prepare(): query_id=e0ed8bc6-ee03-11ed-9009-e43d1a1b411c fragment_instance_id=e0ed8bc6-ee03-11ed-9009-e43d1a1b411e backend_num=2
I0508 20:53:14.513199 120635 fragment_executor.cpp:158] Prepare(): query_id=e0f8af57-ee03-11ed-9009-e43d1a1b411c fragment_instance_id=e0f8af57-ee03-11ed-9009-e43d1a1b4120 backend_num=0
【背景】做过哪些操作?
Create了1000个Routine Load Job,其中40个的并发task数目是3,其他均为1
【业务影响】
无
【StarRocks版本】
2.5.3
【集群规模】
3fe+3be(fe与be混部)
500GB内存,128 CPU核心
【表模型】
均为主键模型,Kafka的topic中UPSERT和DELETE操作都有
【导入或者导出方式】
Routine Load
【联系方式】
StarRocks社区群4-Matata
【附件】
 StarRocks 用户问答 / 性能相关 - StarRocks中文社区论坛 (mirrorship.cn)
StarRocks 用户问答 / 性能相关 - StarRocks中文社区论坛 (mirrorship.cn)