
本文分享导入失败排查思路
1赞
背景
本文主要描述导入问题的排查思路和常见问题解决方法。这里简单阐述下不同导入方式的流程,方便大家理解导入流程和排查问题,具体的可参考文档导入章节。
排查流程
Stream Load
Stream load内部调用链路
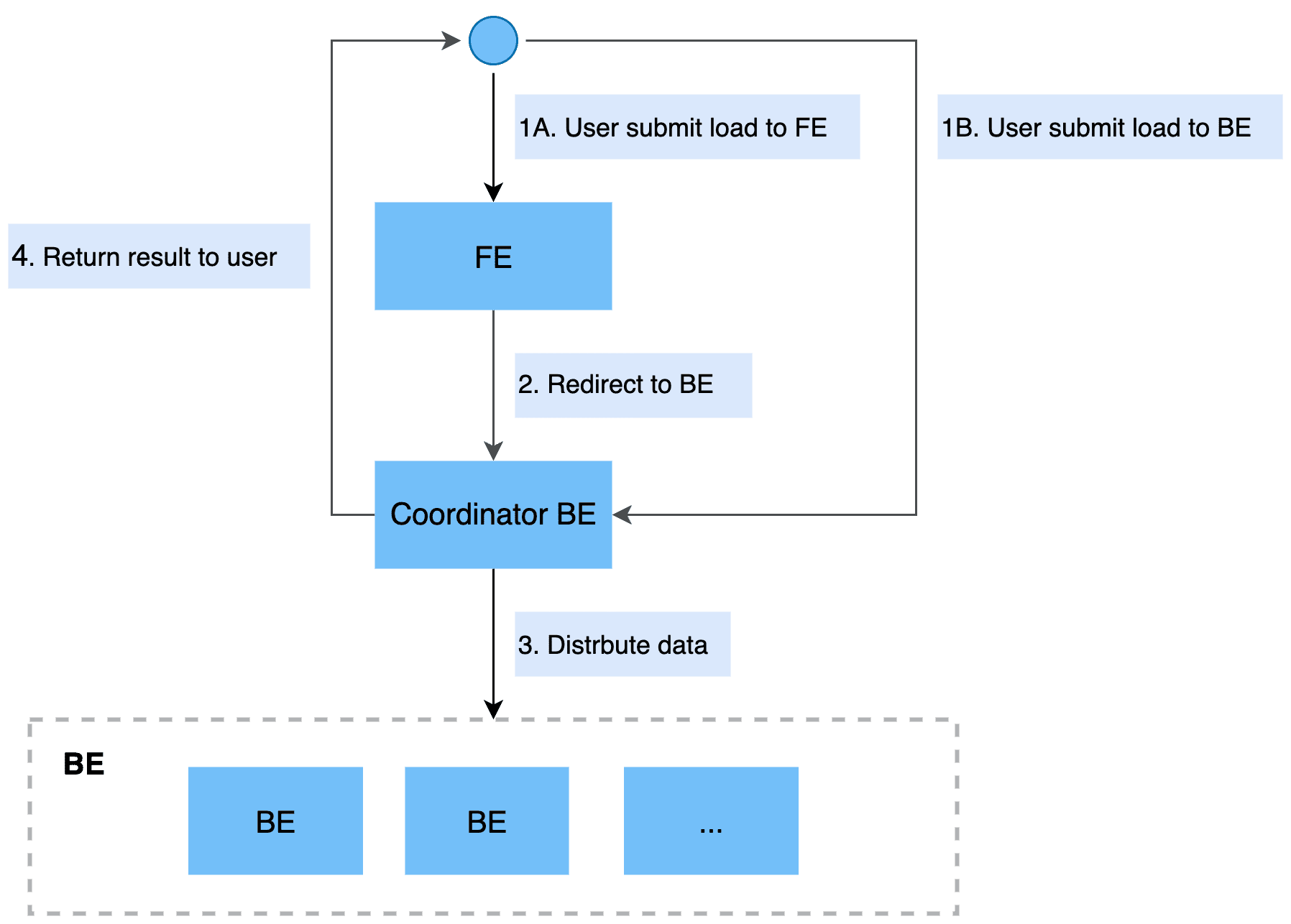
Stream Load是一种同步执行的导入方式。用户通过 HTTP 协议发送请求将本地文件或数据流导入到 StarRocks中,并等待系统返回导入的结果状态,从而判断导入是否成功。
暂时无法在文档外展示此内容
- 通过返回值判断
{
"Status":"Fail",
"BeginTxnTimeMs":1,
"Message":"too many filtered rows",
"NumberUnselectedRows":0,
"CommitAndPublishTimeMs":0,
"Label":"4682d766-0e53-4fce-b111-56a8d8bef390",
"LoadBytes":69238389,
"StreamLoadPutTimeMs":4,
"NumberTotalRows":7077604,
"WriteDataTimeMs":4350,
"TxnId":33,
"LoadTimeMs":4356,
"ErrorURL":"http://192.168.10.142:8040/api/_load_error_log?file=__shard_2/error_log_insert_stmt_e44ae406-32c7-6d5c-a807-b05607a57cbf_e44ae40632c76d5c_a807b05607a57cbf",
"ReadDataTimeMs":1961,
"NumberLoadedRows":0,
"NumberFilteredRows":7077604
}
- 返回值Status:非Success,
a. 存在ErrorURL
Curl ErrorURL,例如
curl "http://192.168.10.142:8040/api/_load_error_log?file=__shard_2/error_log_insert_stmt_e44ae406-32c7-6d5c-a807-b05607a57cbf_e44ae40632c76d5c_a807b05607a57cbf"
b.不存在ErrorURL
{
"TxnId":2271727,
"Label":"4682d766-0e53-4fce-b111-56a8d8bef2340",
"Status":"Fail",
"Message":"Failed to commit txn 2271727. Tablet [159816] success replica num 1 is less then quorum replica num 2 while error backends 10012",
"NumberTotalRows":1,
"NumberLoadedRows":1,
"NumberFilteredRows":0,
"NumberUnselectedRows":0,
"LoadBytes":575,
"LoadTimeMs":26,
"BeginTxnTimeMs":0,
"StreamLoadPutTimeMs":0,
"ReadDataTimeMs":0,
"WriteDataTimeMs":21,
"CommitAndPublishTimeMs":0
}
查看本次导入的load_id和调度到的be节点
grep -w $TxnId fe.log|grep "load id"
#输出例子:
2021-12-20 20:48:50,169 INFO (thrift-server-pool-4|138) [FrontendServiceImpl.streamLoadPut():809] receive stream load put request. db:ssb, tbl: demo_test_1, txn id: 1580717, load id: 7a4d4384-1ad7-b798-f176-4ae9d7ea6b9d, backend: 172.26.92.155
在对应的be节点查看具体原因
grep $load_id be.INFO|less
I0518 11:58:16.771597 4228 stream_load.cpp:202] new income streaming load request.id=f145be377c754e94-816b0480c5139b81, job_id=-1, txn_id=-1, label=metrics_detail_1652846296770062737, db=starrocks_monitor, tbl=metrics_detail
I0518 11:58:16.776926 4176 load_channel_mgr.cpp:186] Removing finished load channel load id=f145be377c754e94-816b0480c5139b81
I0518 11:58:16.776930 4176 load_channel.cpp:40] load channel mem peak usage=1915984, info=limit: 16113540169; consumption: 0; label: f145be377c754e94-816b0480c5139b81; all tracker size: 3; limit trackers size: 3; parent is null: false; , load_id=f145be377c754e94-816b0480c5139b81
如果查不到具体原因,可以继续查看线程上下文,比如上文的 4176
grep -w 4176 be.INFO|less
Broker Load
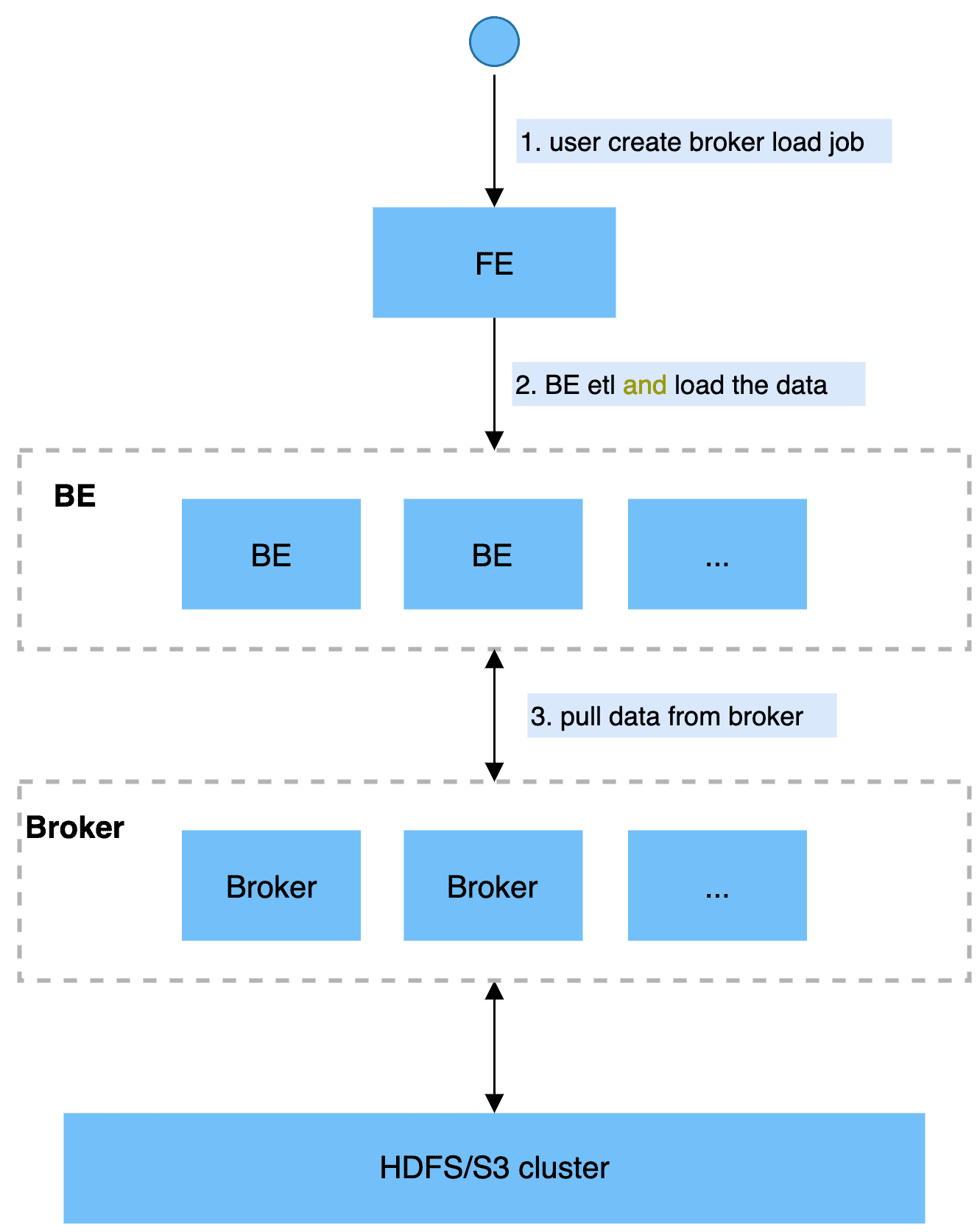
用户在提交导入任务后,FE 会生成对应的 Plan 并根据目前 BE 的个数和文件的大小,将 Plan 分给多个 BE 执行,每个 BE 执行一部分导入任务。BE 在执行过程中会通过 Broker 拉取数据,在对数据预处理之后将数据导入系统。所有 BE 均完成导入后,由 FE 最终判断导入是否成功。
暂时无法在文档外展示此内容
目前一个Broker Load的任务流程会经过PENDING–>LOADING–>FINISHED(或CANCELLED)的流程,当状态为CANCELLED的时候需要介入排查。
- Show load查看任务状态,状态为CANCELLED的时候进一步跟进
- 如果URL不为空,则curl $URL查看具体报错信息
- 如果URL为空,通过fe日志查看load id和be
- 检查hdfs文件路径是否指定正确,可以指定到具体文件也可以指定某目录下的所有文件
- hdfs导入请检查一下是否有k8s认证,并进行配置
grep $JobnId fe.log
- be中查看具体异常
grep $load_id be.INFO
ErrorMsg中的type取值:
-
USER-CANCEL: 用户取消的任务
-
ETL-RUN-FAIL: 在ETL阶段失败的导入任务
-
ETL-QUALITY-UNSATISFIED: 数据质量不合格,也就是错误数据率超过了 max-filter-ratio
-
LOAD-RUN-FAIL: 在LOADING阶段失败的导入任务
-
TIMEOUT: 导入任务没在超时时间内完成
-
UNKNOWN: 未知的导入错误
Routine Load
+-----------------+
fe schedule job | NEED_SCHEDULE | user resume job
+-----------+ | <---------+
| | | |
v +-----------------+ ^
| |
+------------+ user(system)pause job +-------+----+
| RUNNING | | PAUSED |
| +-----------------------> | |
+----+-------+ +-------+----+
| | |
| | +---------------+ |
| | | STOPPED | |
| +---------> | | <-----------+
| user stop job+---------------+ user stop job
|
|
| +---------------+
| | CANCELLED |
+-------------> | |
system error +---------------+
上图表示的是routine load的任务状态机
show routine load for db.job_name
MySQL [load_test]> SHOW ROUTINE LOAD\G;
*************************** 1. row ***************************
Id: 14093
Name: routine_load_wikipedia
CreateTime: 2020-05-16 16:00:48
PauseTime: 2020-05-16 16:03:39
EndTime: N/A
DbName: default_cluster:load_test
TableName: routine_wiki_edit
State: PAUSED
DataSourceType: KAFKA
CurrentTaskNum: 0
JobProperties: {"partitions":"*","columnToColumnExpr":"event_time,channel,user,is_anonymous,is_minor,is_new,is_robot,is_unpatrolled,delta,added,deleted","maxBatchIntervalS":"10","whereExpr":"*","maxBatchSizeBytes":"104857600","columnSeparator":"','","maxErrorNum":"1000","currentTaskConcurrentNum":"1","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"starrocks-load","currentKafkaPartitions":"0","brokerList":"localhost:9092"}
CustomProperties: {}
Statistic: {"receivedBytes":162767220,"errorRows":132,"committedTaskNum":13,"loadedRows":2589972,"loadRowsRate":115000,"abortedTaskNum":7,"totalRows":2590104,"unselectedRows":0,"receivedBytesRate":7279000,"taskExecuteTimeMs":22359}
Progress: {"0":"13824771"}
ReasonOfStateChanged: ErrorReason{code=errCode = 100, msg='User root pauses routine load job'}
ErrorLogUrls: http://172.26.108.172:9122/api/_load_error_log?file=__shard_54/error_log_insert_stmt_e0c0c6b040c044fd-a162b16f6bad53e6_e0c0c6b040c044fd_a162b16f6bad53e6, http://172.26.108.172:9122/api/_load_error_log?file=__shard_55/error_log_insert_stmt_ce4c95f0c72440ef-a442bb300bd743c8_ce4c95f0c72440ef_a442bb300bd743c8, http://172.26.108.172:9122/api/_load_error_log?file=__shard_56/error_log_insert_stmt_8753041cd5fb42d0-b5150367a5175391_8753041cd5fb42d0_b5150367a5175391
OtherMsg:
1 row in set (0.01 sec)
当任务状态为PAUSED或者CANCELLED的时候需要介入排查
任务状态为PAUSED时:
- 可以先查看ReasonOfStateChanged定位下原因,例如“Offset out of range”
- 若ReasonOfStateChanged为空,查看ErrorLogUrls可查看具体的报错信息
curl ${ErrorLogUrls}
如果以上方法不能获取具体异常,可以执行以下命令查看,由于routine load是按周期调度的stream load任务,所以可以通过调度的任务查看任务的状态
show routine load task where JobName="routine_load_wikipedia"
查看Message字段可以看到具体异常
如果以上方法都不能排查到问题,可以拿到job id在be.INFO日志中找到txn id,然后通过txn id在be.INFO中查看上下文
Spark Load
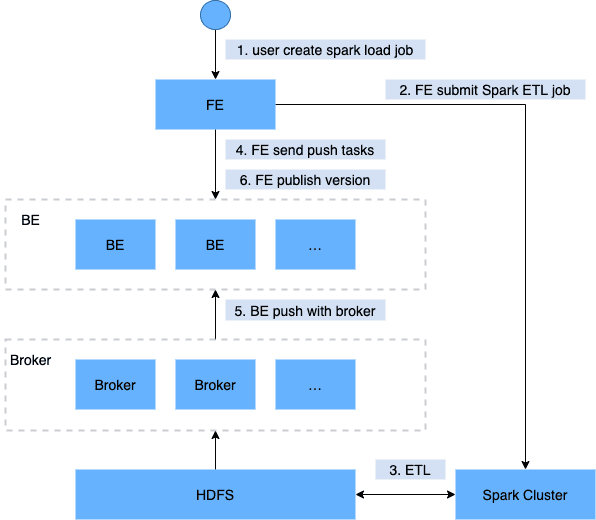
查看任务
show load order by createtime desc limit 1\G
或者
show load order where label="$label"\G
*************************** 1. row ***************************
JobId: 76391
Label: label1
State: FINISHED
Progress: ETL:100%; LOAD:100%
Type: SPARK
EtlInfo: unselected.rows=4; dpp.abnorm.ALL=15; dpp.norm.ALL=28133376
TaskInfo: cluster:cluster0; timeout(s):10800; max_filter_ratio:5.0E-5
ErrorMsg: N/A
CreateTime: 2019-07-27 11:46:42
EtlStartTime: 2019-07-27 11:46:44
EtlFinishTime: 2019-07-27 11:49:44
LoadStartTime: 2019-07-27 11:49:44
LoadFinishTime: 2019-07-27 11:50:16
URL: http://1.1.1.1:8089/proxy/application_1586619723848_0035/
JobDetails: {"ScannedRows":28133395,"TaskNumber":1,"FileNumber":1,"FileSize":200000}
- 先查看ErrorMsg,判断是否可直观判断
- 如果上一步得不到具体异常,则在fe/log/spark_launcher_log/下面查找日志,日志命名为spark-launcher-{load-job-id}-{label}.log
- 如果上一步还查不到具体异常,可以在fe.WARNING日志中查找日志
- 如果上一步查不到异常,则访问spark ui查到对应executor日志
Insert Into
Insert into也是大家目前遇到问题比较多的导入方式。目前Insert into支持以下两种方式:
- 方式一:Insert into table values ();
- 方式二:Insert into table1 xxx select xxx from table2
方式一不建议在线上使用
由于insert into导入方式是同步的,执行完会立即返回结果。可以通过返回结果判断导入成功或失败。
Flink-connector
写入StarRocks是封装的stream load,内部流程可参考Stream Load导入
无法复制加载中的内容
由于Flink-connector底层走的是stream load的方式,所以可以参考stream load排查方式进行。
- 首先从Flink日志中搜索"_stream_load"关键字,确认成功发起了stream load任务
- 然后排查搜索对应stream load的label,搜索该label的导入返回结果,如下图
{
"Status":"Fail",
"BeginTxnTimeMs":1,
"Message":"too many filtered rows",
"NumberUnselectedRows":0,
"CommitAndPublishTimeMs":0,
"Label":"4682d766-0e53-4fce-b111-56a8d8bef390",
"LoadBytes":69238389,
"StreamLoadPutTimeMs":4,
"NumberTotalRows":7077604,
"WriteDataTimeMs":4350,
"TxnId":33,
"LoadTimeMs":4356,
"ErrorURL":"http://192.168.10.142:8040/api/_load_error_log?file=__shard_2/error_log_insert_stmt_e44ae406-32c7-6d5c-a807-b05607a57cbf_e44ae40632c76d5c_a807b05607a57cbf",
"ReadDataTimeMs":1961,
"NumberLoadedRows":0,
"NumberFilteredRows":7077604
}
- 接下来参考stream load排查流程即可
Flink-CDC
写入StarRocks是封装的stream load,内部流程可参考Stream Load导入
- Flink任务没有报错的时候
第一步:确认binlog是否开启,可以通过 SHOW VARIABLES LIKE 'log_bin’查看;
第二步:确认flink、flink-cdc、flink-starrocks-connector和mysql版本(MySQL版本为5.7和8.0.X)是否满足要求,flink、flink-cdc和flink-starrocks-connector的大版本需要一致,例如都是1.13版本
第三步:逐步判断是查源表还是写starrocks的问题,这里利用下面的sql文件演示一下,该文件是Flink-cdc中第7步生成的flink-create.1.sql
CREATE DATABASE IF NOT EXISTS `test_db`;
CREATE TABLE IF NOT EXISTS `test_db`.`source_tb` (
`id` STRING NOT NULL,
`score` STRING NULL,
PRIMARY KEY(`id`)
NOT ENFORCED
) with (
'username' = 'root',
'password' = 'xxx',
'database-name' = 'test',
'table-name' = 'test_source',
'connector' = 'mysql-cdc',
'hostname' = '172.26.92.139',
'port' = '8306'
);
CREATE TABLE IF NOT EXISTS `test_db`.`sink_tb` (
`id` STRING NOT NULL,
`score` STRING NULL
PRIMARY KEY(`id`)
NOT ENFORCED
) with (
'load-url' = 'sr_fe_host:8030',
'sink.properties.row_delimiter' = '\x02',
'username' = 'root',
'database-name' = 'test_db',
'sink.properties.column_separator' = '\x01',
'jdbc-url' = 'jdbc:mysql://sr_fe_host:9030',
'password' = '',
'sink.buffer-flush.interval-ms' = '15000',
'connector' = 'starrocks',
'table-name' = 'test_tb'
);
INSERT INTO `test`.`sink_tb` SELECT * FROM `test_db`.`source_tb`;
安装的Flink目录下执行下面语句进入flink-sql
bin/sql-client.sh
首先验证读取source表是否正常
#分别把上面的sql粘贴进来判断是查询源表的问题还是写入到starrocks的问题
CREATE DATABASE IF NOT EXISTS `test_db`;
CREATE TABLE IF NOT EXISTS `test_db`.`source` (
`id` STRING NOT NULL,
`score` STRING NULL,
PRIMARY KEY(`id`)
NOT ENFORCED
) with (
'username' = 'root',
'password' = 'xxx',
'database-name' = 'test',
'table-name' = 'test_source',
'connector' = 'mysql-cdc',
'hostname' = '172.26.92.139',
'port' = '8306'
);
#验证source是否正常
select * from `test_db`.`source_tb`;
再验证写入starrocks是否正常
CREATE TABLE IF NOT EXISTS `test_db`.`sink_tb` (
`id` STRING NOT NULL,
`score` STRING NULL
PRIMARY KEY(`id`)
NOT ENFORCED
) with (
'load-url' = 'sr_fe_host:8030',
'sink.properties.row_delimiter' = '\x02',
'username' = 'root',
'database-name' = 'test_db',
'sink.properties.column_separator' = '\x01',
'jdbc-url' = 'jdbc:mysql://sr_fe_host:9030',
'password' = '',
'sink.buffer-flush.interval-ms' = '15000',
'connector' = 'starrocks',
'table-name' = 'test_tb'
);
INSERT INTO `test`.`sink_tb` SELECT * FROM `test_db`.`source_tb`;
- Flink任务出错
第一步:确认flink集群是否有启动,可能有的同学本地下载的flink没有启动,需要./bin/start-cluster.sh启动下flink
第二步:根据具体的报错再具体分析
DataX
写入StarRocks是封装的stream load,内部流程可参考Stream Load导入
无法复制加载中的内容
由于DataX底层也是走的stream load方式,所以可以参考stream load排查方式进行。
- 首先从datax/log/YYYY-MM-DD/xxx.log日志中搜索"_stream_load"关键字,确认成功发起了stream load任务
A. 如果没有stream load生成,具体查看datax/log/YYYY-MM-DD/xxx.log日志,分析异常解决
B. 如有stream load生成,在datax/log/YYYY-MM-DD/xxx.log搜索对应stream load的label,搜索该label的导入返回结果,如下图
{
"Status":"Fail",
"BeginTxnTimeMs":1,
"Message":"too many filtered rows",
"NumberUnselectedRows":0,
"CommitAndPublishTimeMs":0,
"Label":"4682d766-0e53-4fce-b111-56a8d8bef390",
"LoadBytes":69238389,
"StreamLoadPutTimeMs":4,
"NumberTotalRows":7077604,
"WriteDataTimeMs":4350,
"TxnId":33,
"LoadTimeMs":4356,
"ErrorURL":"http://192.168.10.142:8040/api/_load_error_log?file=__shard_2/error_log_insert_stmt_e44ae406-32c7-6d5c-a807-b05607a57cbf_e44ae40632c76d5c_a807b05607a57cbf",
"ReadDataTimeMs":1961,
"NumberLoadedRows":0,
"NumberFilteredRows":7077604
}
- 接下来参考stream load排查流程即可
常见问题
- “Failed to commit txn 2271727. Tablet [159816] success replica num 1 is less then quorum replica num 2 while error backends 10012”,
这个问题具体原因需要按照上面排查流程在be.WARNING中查看具体异常
- close index channel failed/too many tablet versions
导入频率太快,compaction没能及时合并导致版本数过多,默认版本数1000
降低频率,调整compaction策略,加快合并(注意,该操作会对cpu,内存和磁盘io负载带来压力,调整完需要观察机器负载),在be.conf中修改以下内容
base_compaction_check_interval_seconds = 10
cumulative_compaction_num_threads_per_disk = 4
base_compaction_num_threads_per_disk = 2
cumulative_compaction_check_interval_seconds = 2
- Reason: invalid value ‘202123098432’.
导入文件某列和表中的类型不一致导致
- the length of input is too long than schema
导入文件某列长度不正确,比如定长字符串超过建表设置的长度、int类型的字段超过4个字节。
- actual column number is less than schema column number
导入文件某一行按照指定的分隔符切分后列数小于指定的列数,可能是分隔符不正确。
- actual column number is more than schema column number
导入文件某一行按照指定的分隔符切分后列数大于指定的列数,可能是分隔符不正确。
- the frac part length longer than schema scale
导入文件某decimal列的小数部分超过指定的长度。
- the int part length longer than schema precision
导入文件某decimal列的整数部分超过指定的长度。
- the length of decimal value is overflow
导入文件某decimal列的长度超过指定的长度。
- There is no corresponding partition for this key
导入文件某行的分区列的值不在分区范围内。
- Caused by: org.apache.http.ProtocolException: The server failed to respond with a valid HTTP response
Stream load端口配置错误,应该是http_port
- flink demo,按要求建立了测试库表,然后程序没有任何报错日志,数据也无法sink进去,请问有什么排查思路呢
可能是无法访问be导致,当前flink封装的stream load,fe接收到请求后会redirect $be:$http_port,一般本地调试的时候,能访问fe+http_port,但是无法访问be+http_port,需要开通访问be+http_port的防火墙
- Transaction commit successfully,But data will be visible later
该状态也表示导入已经完成,只是数据可能会延迟可见。原因是有部分publish超时,也可以调大fe配置publish_version_timeout_second
- get database write lock timeout
可能是fe的线程数超了,建议可以调整下be配置:thrift_rpc_timeout_ms=10000(默认5000ms)
- failed to send batch 或 TabletWriter add batch with unknown id
请参照章节导入总览/通用系统配置/BE配置,适当修改 query_timeout 和 streaming_load_rpc_max_alive_time_sec
- LOAD-RUN-FAIL; msg:Invalid Column Name:xxx
- 如果是Parquet或者ORC格式的数据,需要保持文件头的列名与StarRocks表中的列名一致,如 :
(tmp_c1,tmp_c2)
SET
(
id=tmp_c2,
name=tmp_c1
)
表示将Parquet或ORC文件中以(tmp_c1, tmp_c2)为列名的列,映射到StarRocks表中的(id, name)列。如果没有设置set, 则以column中的列作为映射。
注意:如果使用某些Hive版本直接生成的ORC文件,ORC文件中的表头并非Hive meta数据,而是
(_col0, _col1, _col2, ...) , 可能导致Invalid Column Name错误,那么则需要使用set进行映射。
Can't get Kerberos realm
A:首先检查是不是所有的broker所在机器是否都配置了
/etc/krb5.conf 文件。
如果配置了仍然报错,需要在broker的启动脚本中的
JAVA_OPTS 变量最后,加上
-Djava.security.krb5.conf:/etc/krb5.conf 。
- orc数据导入失败ErrorMsg: type:ETL_RUN_FAIL; msg:Cannot cast ‘<slot 6>’ from VARCHAR to
ARRAY<VARCHAR(30)>
导入源文件和starrocks两边列名称不一致,set的时候系统内部会有一个类型推断,然后cast的时候失败了,设置成两边字段名一样,不需要set,就不会cast,导入就可以成功了
- No source file in this table
表中没有文件
- cause by: SIMPLE authentication is not enabled. Available:[TOKEN, KERBEROS]
kerberos认证失败。klist检查下认证是否过期,并且该账号是否有权限访问源数据
- Reason: there is a row couldn’t find a partition. src line: [];
导入的数据在starrocks表中无指定分区
5赞
主键模型表,使用stream load导入数据,导入10条数据成功,导入1.5万条数据失败。
以下是fe.log , txn id 26089。
2022-03-21 01:01:58,852 INFO (thrift-server-pool-16|6450) [DatabaseTransactionMgr.beginTransaction():295] begin transaction: txn id 26089 with label 20220321_010158 from coordinator BE: 10.2.24.33, listner id: -1
2022-03-21 01:01:58,853 INFO (thrift-server-pool-12|2578) [FrontendServiceImpl.streamLoadPut():843] receive stream load put request. db:dsj_dwd, tbl: dws_md_user_log_total_test, txn id: 26089, load id: f44b923a-69d8-aacd-7828-f82f5ed2be90, backend: 10.2.24.33
2022-03-21 01:01:58,890 INFO (thrift-server-pool-6|162) [FrontendServiceImpl.loadTxnCommit():692] receive txn commit request. db: dsj_dwd, tbl: dws_md_user_log_total_test, txn id: 26089, backend: 10.2.24.33
2022-03-21 01:01:58,891 WARN (thrift-server-pool-6|162) [DatabaseTransactionMgr.commitTransaction():517] Failed to commit txn [26089]. Tablet [16568] success replica num is 0 < quorum replica num 2 while error backends 10085,10086,10061
2022-03-21 01:01:58,891 WARN (thrift-server-pool-6|162) [FrontendServiceImpl.loadTxnCommit():706] failed to commit txn: 26089: Failed to commit txn 26089. Tablet [16568] success replica num 0 is less then quorum replica num 2 while error backends 10085,10086,10061
2022-03-21 01:01:58,892 INFO (thrift-server-pool-17|6451) [FrontendServiceImpl.loadTxnRollback():794] receive txn rollback request. db: dsj_dwd, tbl: dws_md_user_log_total_test, txn id: 26089, reason: Failed to commit txn 26089. Tablet [16568] success replica num 0 is less then quorum replica num 2 while error backends 10085,10086,10061, backend: 10.2.24.33
以下为be.log:
grep ‘f44b923a-69d8-aacd-7828-f82f5ed2be90’ be.WARNING ,无内容。
grep ‘f44b923a-69d8-aacd-7828-f82f5ed2be90’ be.INFO
I0321 01:01:58.856958 26789 stream_load_executor.cpp:56] begin to execute job. label=20220321_010158, txn_id=26089, query_id=f44b923a-69d8-aacd-7828-f82f5ed2be90
I0321 01:01:58.857122 26789 plan_fragment_executor.cpp:70] Prepare(): query_id=f44b923a-69d8-aacd-7828-f82f5ed2be90 fragment_instance_id=f44b923a-69d8-aacd-7828-f82f5ed2be91 backend_num=0
I0321 01:01:58.889406 26622 tablet_sink.cpp:865] Closed olap table sink load_id=f44b923a-69d8-aacd-7828-f82f5ed2be90 txn_id=26089, node add batch time(ms)/wait lock time(ms)/num: {10085:(10)(0)(1)} {10086:(8)(0)(1)} {10061:(9)(0)(1)}
be节点状态均正常,查询正常。
发下这个be.INFO完整的日志
============================33==========================
I0321 10:30:57.710168 26708 tablet_manager.cpp:806] Found 0 expired tablet transactions
I0321 10:30:57.711711 26708 tablet_manager.cpp:831] Reported all 493 tablets info
I0321 10:31:12.169165 26658 load_channel_mgr.cpp:328] Cleaning timed out load channels
I0321 10:31:12.169199 26658 load_channel_mgr.cpp:361] Memory consumption(bytes) limit=4047532167 current=0 peak=437051176
W0321 10:31:16.946296 26758 tablets_channel.cpp:309] Fail to close tablet writer, tablet_id=16568 transaction_id=26114 err=Cancelled: primary key size exceed the limit.
主键模型的表很多吗?主键列多吗?另外请问下是用的哪个版本呢?
2.0.1 ,
字段1 varchar(8)
字段2 varchar(64)
字段3 varchar(64)
字段4 varchar(64)
字段5 varchar(400)
请问下您的be节点内存是多大的,可以curl http://be_host:http_port/metrics|grep be_update_primary_index_bytes_total看下主键索引所占内存。建议减少下主键的数量
Routine Load导入kafka数据时,kafka分区比较多但be节点少,所以需要拆成多个Routine Load任务,这种情况下能否指定消费kafka的分区?
你好,我想知道show load的数据存储在哪里?
我们通过shell执行show load命令,脚本是成功的,但是LOAD LABEL可能是失败的。
show load存储在fe的元数据中,目前除了stream load,其他的load都是支持show load查看
1赞
fe的元数据是在内存吗?还是在那个表?如果是在具体那个表,能否帮忙发一下。感谢
内存和bdb中,没办法指定表查