2月8日第一期 “部署&导入” 篇开播后,我们收到了社区小伙伴们的众多好评,为了不辜负大家的学习热情,社区决定将后面3期的内容一并放出,大家可以提前预留好时间,与我们一起直播打卡。

没有赶上第一期直播的小伙伴,在这里自行补课哦~ https://www.bilibili.com/video/BV1JM4y1Q7c2/?vd_source=1cb452610138142d1300dd37a6162a88
经过第一期的学习,相信大家对不同导入方式,以及实际业务场景具体选择哪种导入已经心中有数,但实际操作中:
-
每种导入方式,在大规模数据量的导入情况下,怎样合理去配置参数和针对性地调优?
-
发生数据质量错误 “ETL_QUALITY_UNSATISFIED; msg:quality not good enough to cancel” 应该如何处理?
-
导入过程中,发生远程过程调用(Remote Procedure Call,简称 RPC)超时问题应该如何处理?
-
等等一系列导入中会遇到的问题。
2月22日(下周三)19:00-20:00,“StarRocks 实战系列第二期–导入优化&问题排查”开播,镜舟科技技术支持工程师 Eddie,将在线为大家梳理不同导入方式的优化方案,将常见的导入问题一网打尽。
干货满满,不要错过!马上扫码预约直播,加入我们,一起玩转 StarRocks!

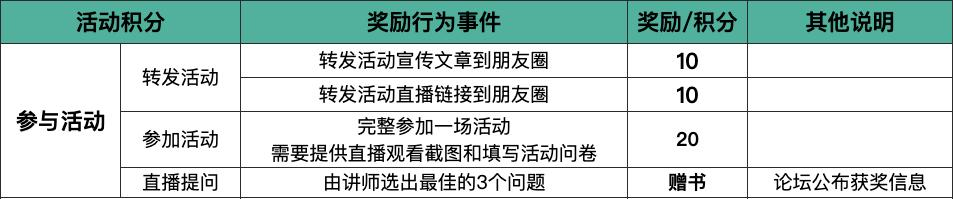
StarRocks 实战系列直播活动积分规则:
-
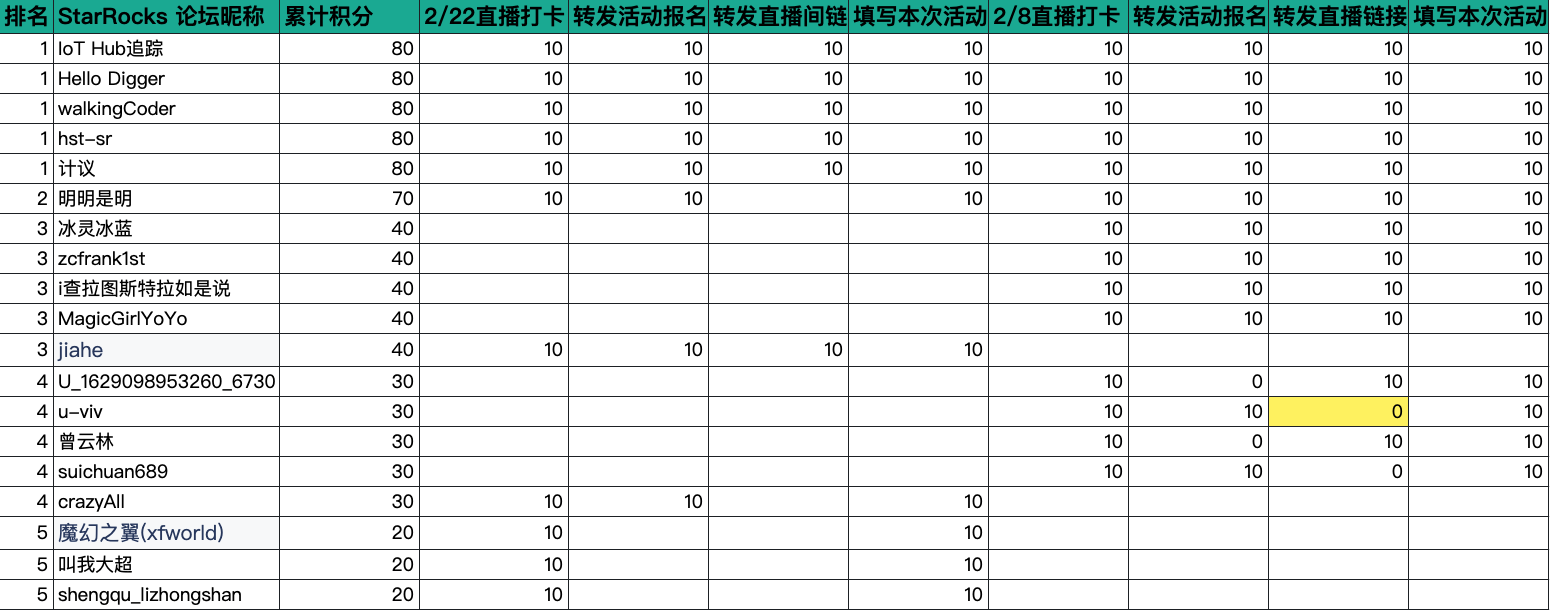
【重要】积分记录、中奖名单、直播 QA 和回放等,请至论坛查看: 2/22 19:00 直播 | StarRocks 实战系列 Ep.2—导入优化&问题排查(转发、打卡还可以获得积分奖品!)
-
转发朋友圈截图及直播间观看截图均在本次活动问卷中进行填写 (问卷填写截止时间为: 2023年2月23日21:00 前,过期将不可再填写) 活动问卷请填写:https://tl-tx.dustess.com/aTpuvg9W5W

-
该系列直播积分可累积,如:
-
打卡“部署&导入”篇, 完成上述所有奖励行为事件,获得 40 积分
-
打卡本次直播,完成上述所有奖励行为事件,获得 40 积分,加上累积的 40 积分,此时总和为 80 积分
-
依此类推,当累计积分达到50分及以上,即可参与积分兑奖
-
-
可以选择立即兑换相应奖品,或者等完成上述全部打卡后,根据自己的积分总和在积分商城选择想要的奖品进行兑换,未兑换完的积分将在本系列直播结束后(2023年3月底)自动清零。
-
成功打卡 全部直播 的小伙伴,将会额外获得 StarRocks 社区纪念徽章。
-
兑换奖品时请填写:https://tl-tx.dustess.com/4kTjGagl6W

StarRocks 实战系列直播奖品及兑换方式

注: 如果对活动规则有疑问,可在评论区留言交流~