
【详述】问题详细描述
【背景】使用datax抽取pg数据导入到starrocks
【业务影响】
【StarRocks版本】例如:2.3.0rc
【集群规模】例如:3fe(1 follower+2observer)+5be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,12C/32G/千兆
【表模型】聚合模型
【导入或者导出方式】datax
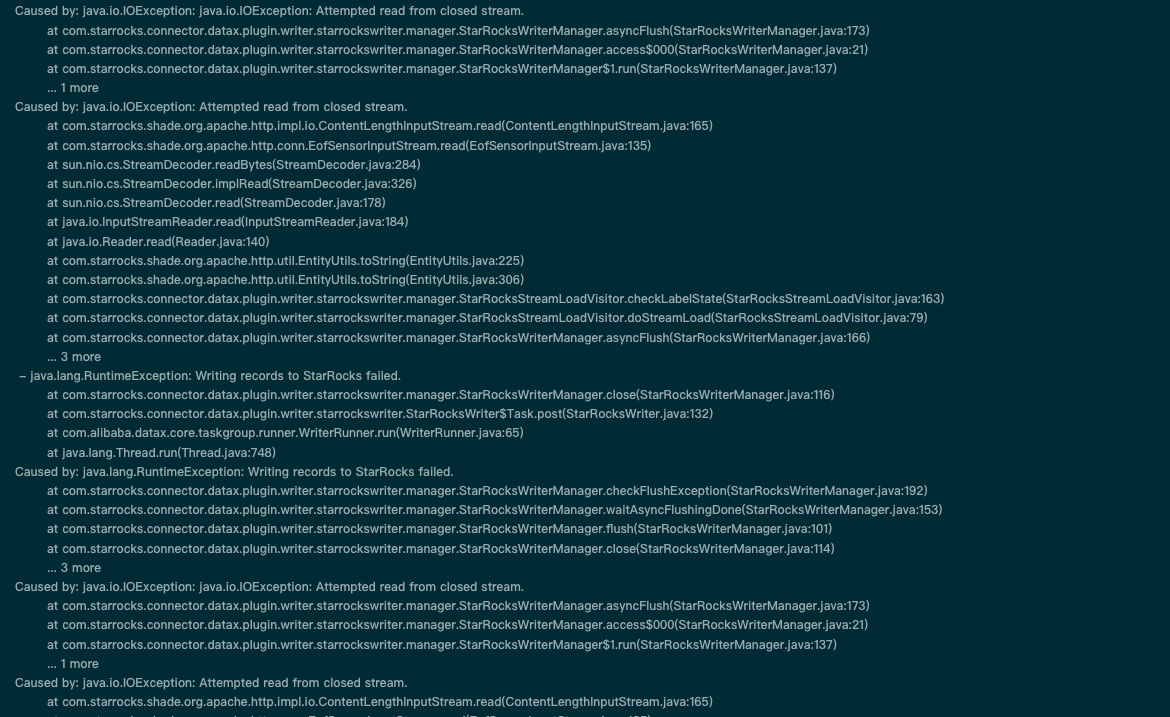
【附件】导入多个表,用海豚调度执行,10个channel左右,随机出现一张表连接超时,提示超时timeoutMillis=7500,查找了官网相关配置,修改了admin set frontend config (‘max_running_txn_num_per_db’ = ‘5000’),admin set frontend config (‘stream_load_default_timeout_second’ = ‘9000’);
admin set frontend config (‘export_task_default_timeout_second’ = ‘75000’);
curl -XPOST http://10.151.217.1:8043/api/update_config?thrift_rpc_timeout_ms=10000;(这个最高好像只能配置到10000);
更改了fe.conf的配置文件添加了qe_max_connection = 5000,mysql_service_io_threads_num=500,都没有用,想请教下是什么导致的?是否是starrocks内部把这部分源码写死了?如何解决这个问题呢
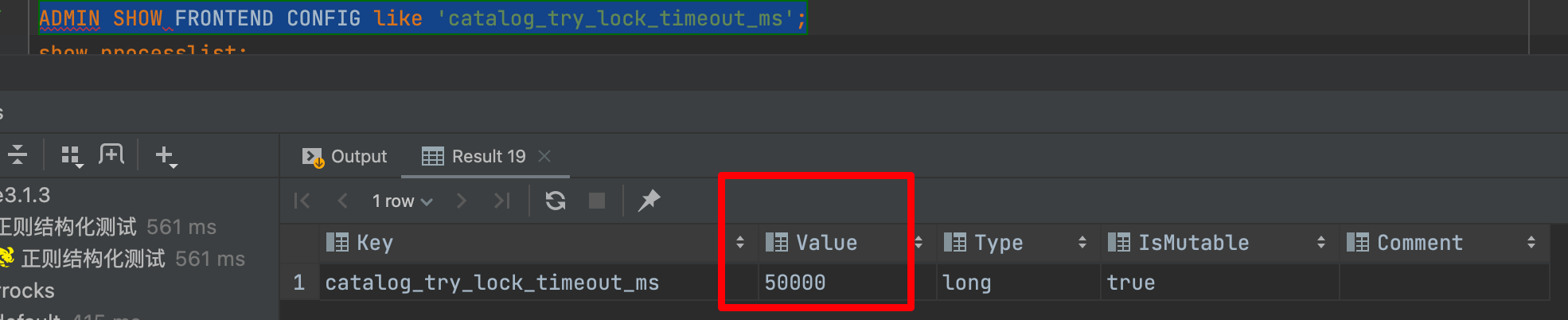
catalog_try_lock_timeout_ms 增大下这个参数观察下。

请问咱们集群现在能够正常查询么?
没有问题的,只是导入有问题,方便加个v?
请问还有其他参数可以调整吗?
这个数据库是不是有很多导入任务呢?
是的,十几张表同时抽取pg的导入sr,datax最大channel10,基本都是5,最大表数据量6千万,其他的都是几百万左右,也尝试过分出千万级抽取完了再抽取五百万再抽取百万,也就是十几个任务并行或者把这十几个任务分成三段,都会报这个错
您好,可以手动设置下datax任务单独跑下么?
我测试过,中间也会出现这个报错,只不过它datax和海豚内部会有重试机制,单表的话成功概率高很多,但是重试几次之后还不行也会挂掉,就是那个io异常,我猜想是sr的问题
中间也会出现这个报错,您指的是跑了多个datax任务么?
只单独跑一两个和跑十几个,都有,你可以找个库试试,不难的
咱们核心需求是什么呢?做一次大规模的数据迁移么?
这个问题并没有复现出来呢。
是的没错,做数据同步用,您这边sr用的是什么版本?我是2.3.0rc,这个问题要用海豚调度的时候看日志能发现,任务不一定挂,挂的概率大概百分之二十的样子。
如果是只使用一次的话,建议串行执行比较好。
这个跟版本应该没啥关系。看起来是争抢写锁超时了。
t+1场景。。。这个确实会经常用
这部分能否建议一个feature呢,希望能增加自定义设置项
可以把channel调整成为1来观察下么?