
【详述】问题详细描述
报错信息为"Label":"12f7f812-504f-4a12-912c-e1a75ac857d7"的按时间报错截图,见附件图片。开始报close index channel failed,后面自动重试了3次,最终失败时报timeout by txn manager。1、有什么解决方法么,timeout by txn manager报错比较频繁。
2、重试3次后还失败,这批数据就会丢失了么?
3、另外请问txn是什么意义,哪个单词缩写呀
【背景】做过哪些操作?
消费kafka,sink SR。flink-connector-starrocks版本为1.2.1_flink-1.13_2.11。
【业务影响】
【StarRocks版本】1.19.1
【集群规模】4fe(14follower)+8be
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【附件】


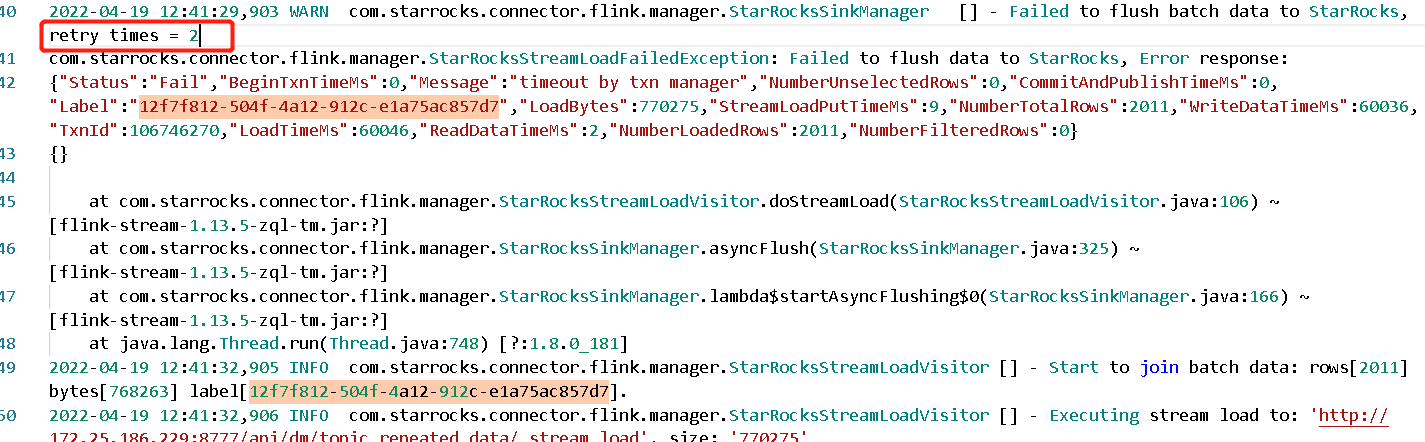
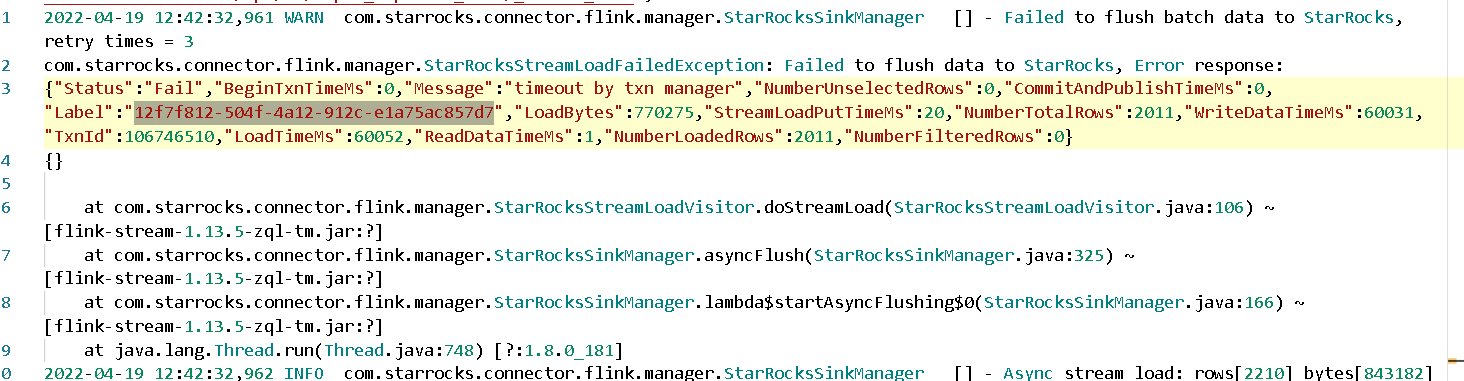
timeout by txn manager这个报错原因多为任务超时取消了,我们那边是不是有很多任务没有调度到,可以把超时时间调大些 — sink.buffer-flush.enqueue-timeout-ms调大,sink flush的间隔也可以调大 ,推荐是15s一次
好的,谢谢。可以帮忙第2个,和第3个小问 也帮忙回答下么