你是什么方式导入的啊?
我用的是stream_load,通过httpput的方式持续导入数据。16个线程,每个线程到达90M就提交一次。
FE也是单机,规格是16U64G。
这些配置是一点点测出来的,之前遇到过导入版本数过高,或者导入时间越来越大等问题,都是通过这些参数解决的。
这些配置太恐怖了。。。
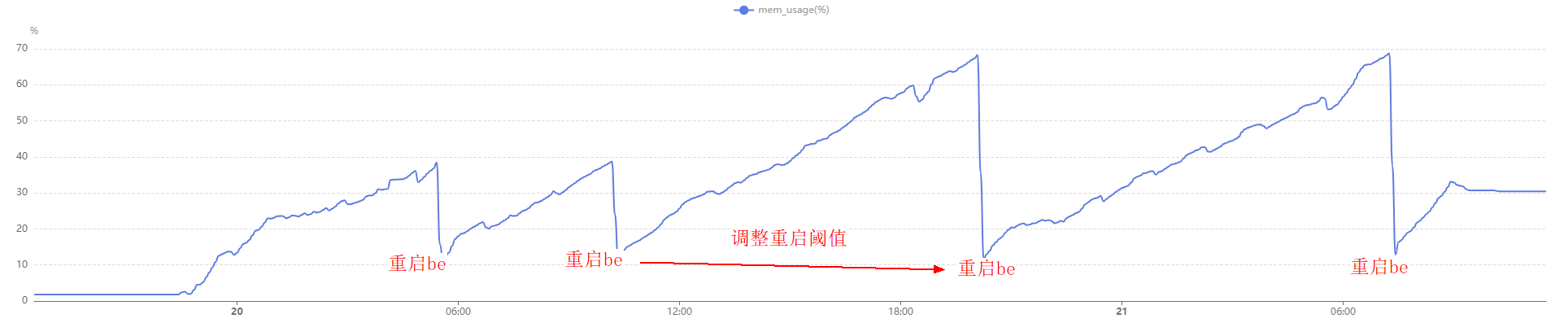
您好,之前的测试大概导入10T左右的数据之后,256G的内存就使用了80%。
经过这几天的测试,发现metadata会保存很多必要的信息在内存中,并且不卸载掉,目前看只能通过重启才能卸载掉metadata占用的内存。
因此:对于大宽表 高速率的数据导入,我们采取了尽量减少在导入过程中metadata中不必要的信息生成,所以
- 把enable_pk_value_column_zonemap=false参数关闭了,这样内存中metadata会小很多;
- 把buckets的数量降低了,以前1t需要130个buckets,现在改成了75个,这个也显著降低了metadata在内存中的占用;
- 然后经过上面两个调整之后,内存的消耗比以前好了非常多,但是30T的数据导入,256G还是不够,因此我们又通过脚本在适当的时候重启be,然后再fe侧提高数据导入的重试时间。
经过上面的调整:现在30T的数据,已经导入完成。
还有两个问题,想请教您:
-
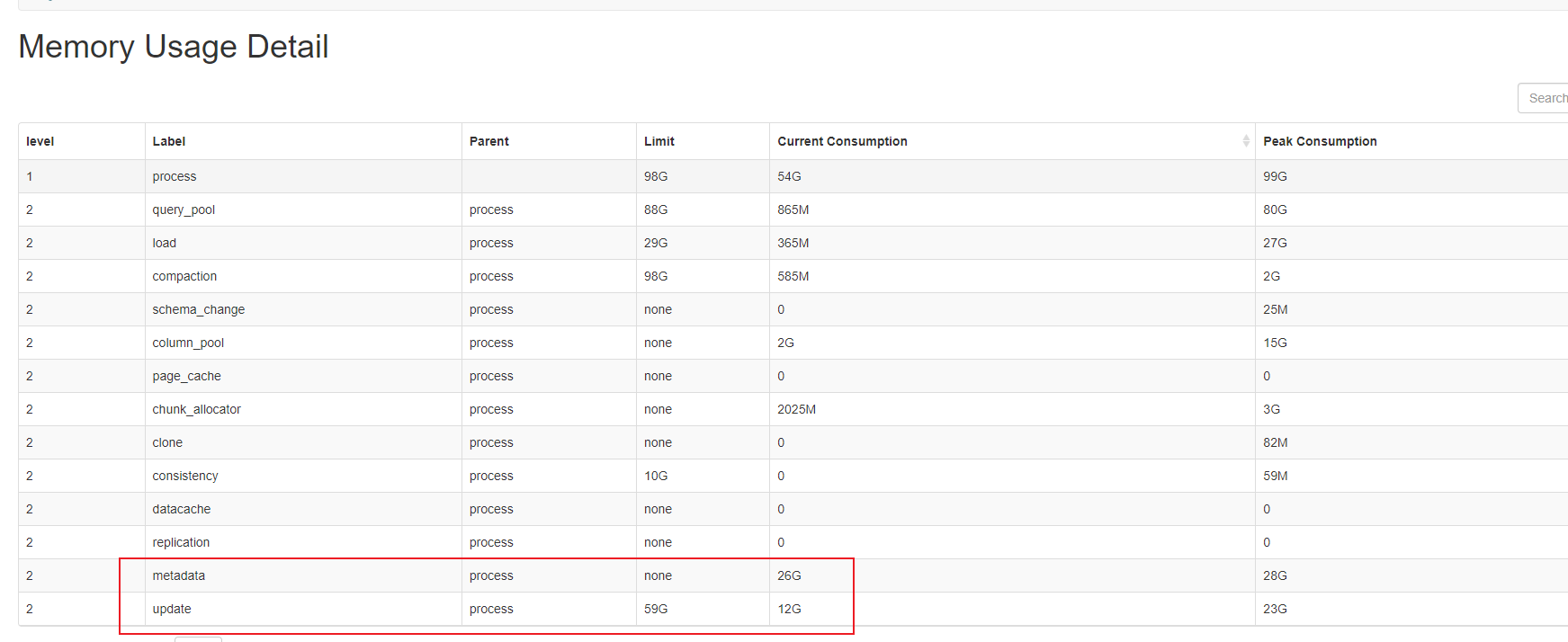
经过分析metadata的内存占用,目前发现starrocks_be_column_metadata_mem_bytes为metadata的主要内存消耗,并且在内存中一直卸载不掉。所以请问您:这个指标的计算逻辑是什么,以便可以继续分析下去,然后就是是否有参数能让这块内存卸载掉。

-
通过这几天的研究,在网上找了很多关于主键模型的介绍,但是对主键模型的存储结构的介绍,基于已有的资料,没办法做全局的了解。partition,tablet,rowset,segment之间的关系,segment里面的细节,没有找到更为详细的介绍。您能提供一下相关的更为详细的介绍吗?发我邮箱也行感谢。
我能找到的比较好的材料:
StarRocks 技术内幕 | 基于全局字典的极速字符串查询_starrocks字典抽取工具-CSDN博客
【已结束】 StarRocks x RisingWave 构建简单高效的实时数据分析 - StarRocks 社区活动 - StarRocks中文社区论坛 (mirrorship.cn)
StarRocks 社区活动 - StarRocks中文社区论坛 (mirrorship.cn)
inc_rowset_expired_sec=1800 ->180
tablet_rowset_stale_sweep_time_sec=1800 -> 180
be.conf这两个调小试试,
你们怎么规避的这个问题?
老师,这个metadata的问题有解决方案了吗?
有,你是哪个版本
3.1.13
show backends; 看下单个BE有多少个Tablet
select * from information_schema.be_metrics where name like “%_mem_bytes%”;
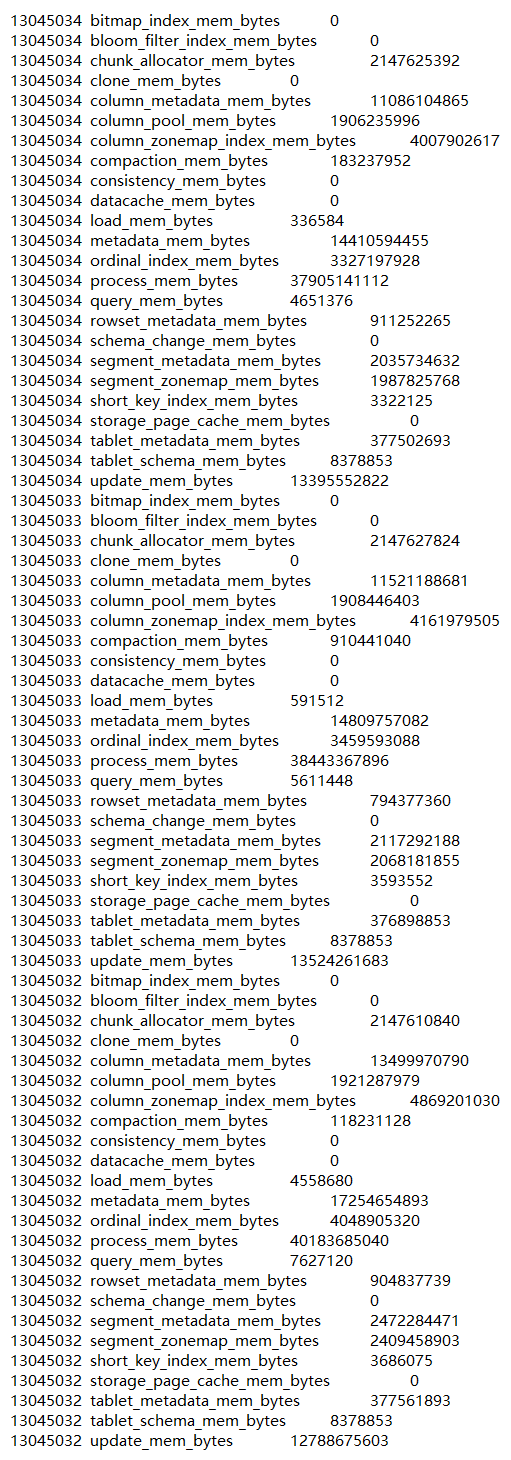
单机多大数据量啊,有几T?
就几百G
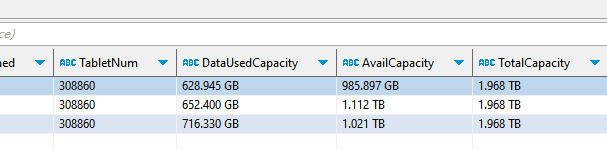
30万Tablet,才几百G数据啊,Tablet太多了吧
那是什么原因呢?