
如何手动做compaction
已经补充上compaction操作方法了
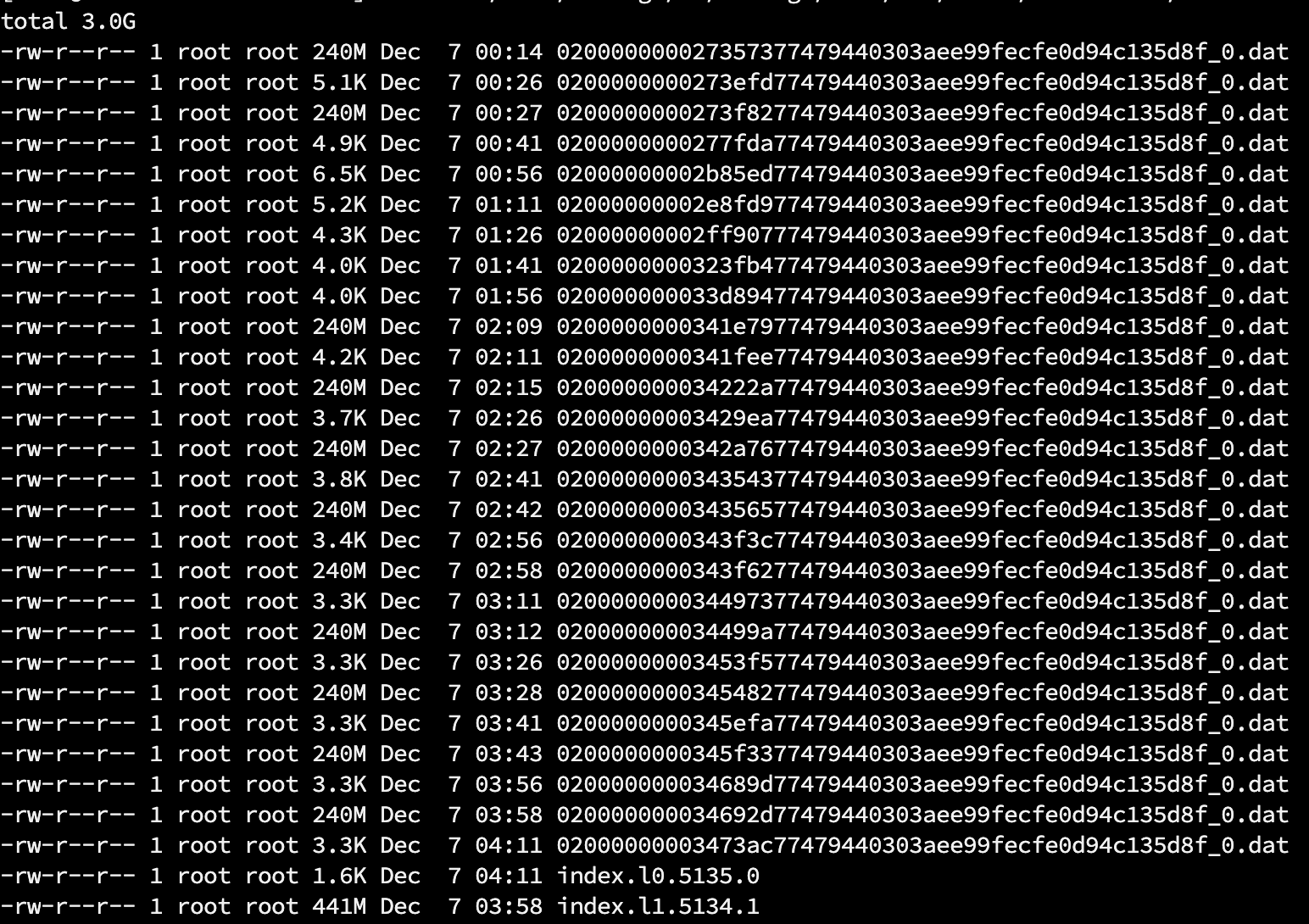
我这里出现的问题是tablet下的dat文件越来越多,也不删除,但上述compaction都是正常,只是经常报warning,wait_for_version slow
有什么机制可以删除这些文件吗?哪个配置是控制定时清理这些dat文件的。可以手动删除吗?就看着硬盘空间一路上涨

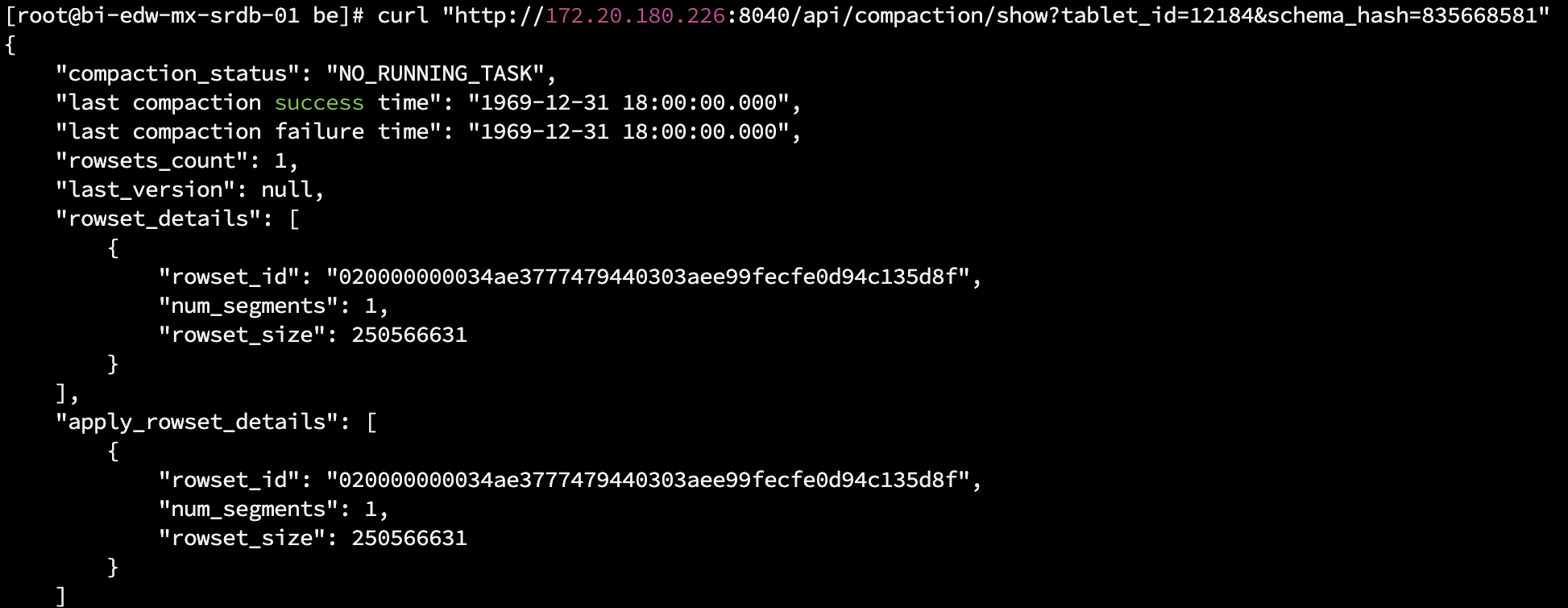
您确认下选的这个tablet 的 tabletid,show tablet tabletid;然后执行show proc ,然后执行 curl Compaction status 看下结果,图二是什么监控
compaction的结果显示如下,success time很奇怪,不过再之前是正常的,我刚才重启了整个starrocks
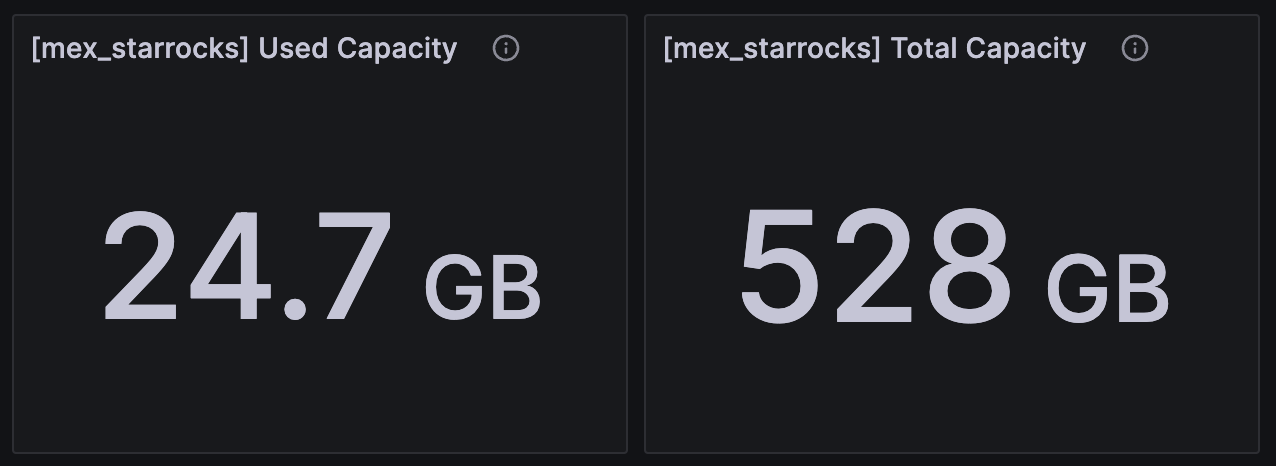
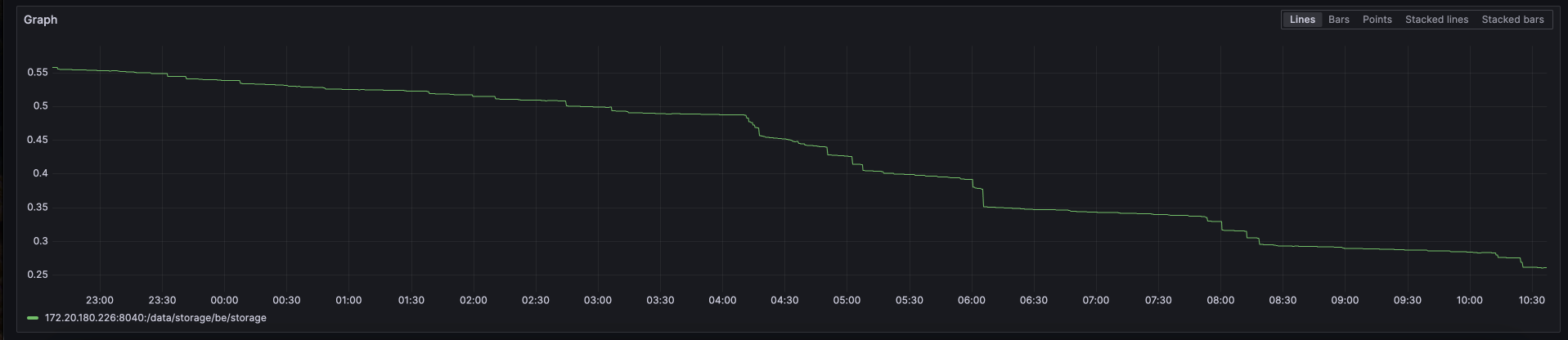
上面的第二个图是硬盘使用量,如下图。图上最后下降了一点是因为我把采集任务全停了,并且重启了starrocks
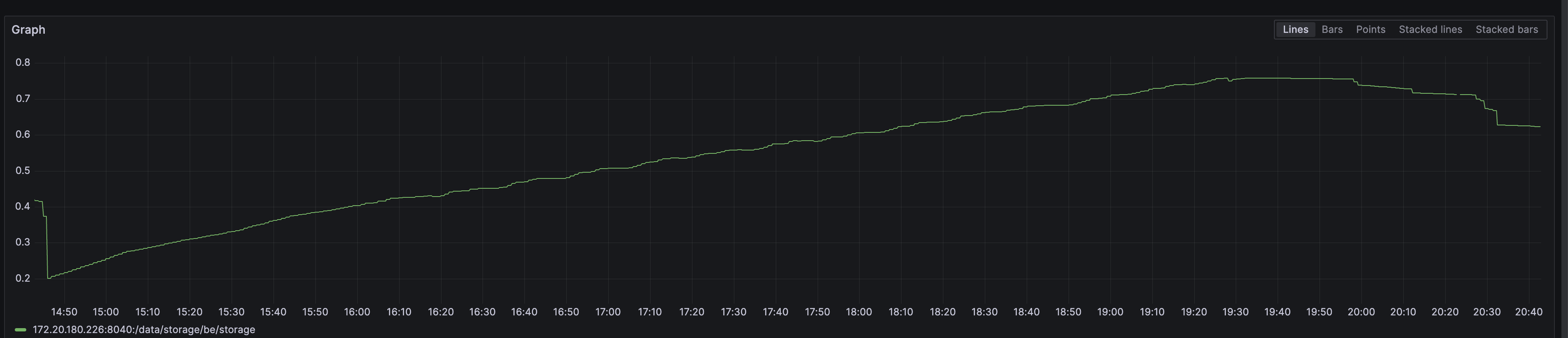
会和服务器所在的时区有关么?服务器是在北美的,时区设的当地的,差了13小时应该。
现在又在be.warning中发现大量的找不到文件无法删除的错误,到对应574/556523/354299382 目录下查看是正常的,只有两个文件
现在完全就不能用了。。估计采集程序一开硬盘就会爆掉了。
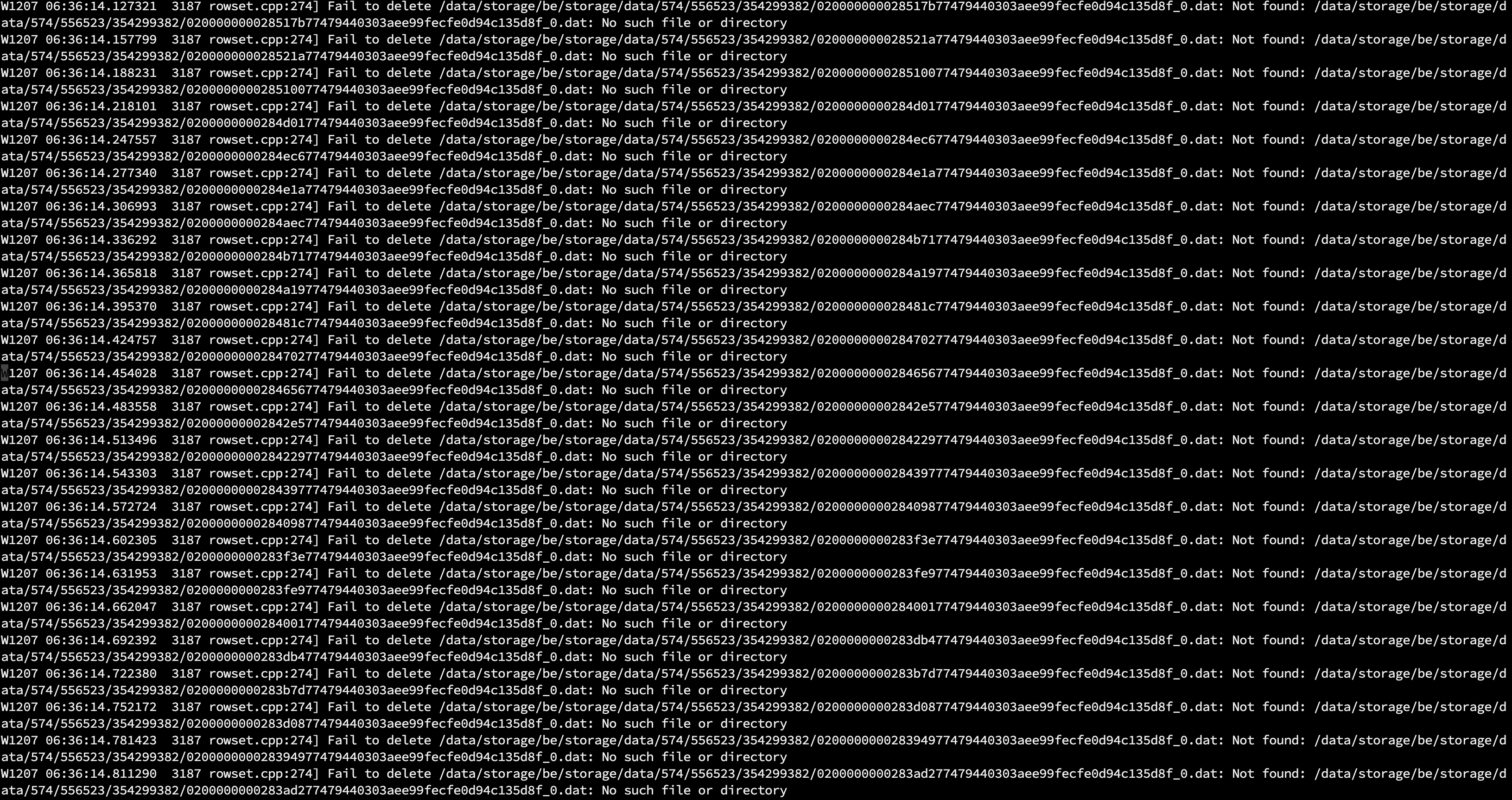
你这个是有问题的,compaction没有正常进行,compaction完整的文件发下,另外grep compaction be.INFO* 拿下compaction所有的日志看下
空放了一晚上服务器,没有跑采集任务,现在硬盘已经降到100G的使用量了,下降曲线很明显,不过数据实际是24G,还是有差距
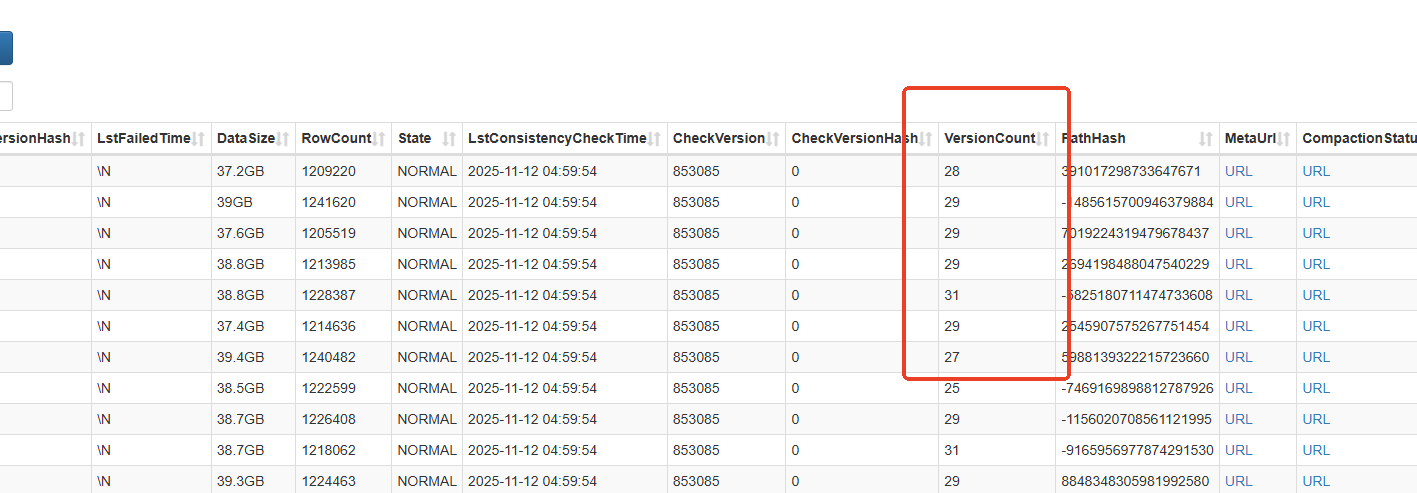
昨天截图的目录看起来已经正常了,只有三个文件了
然后be.INFO中关于compaction的日志如下,因为日志太多了,只拿了be.INFO的
compaction.log.tgz (5.1 MB)
关于compaction完整的文件是指什么,不知道是哪个,望大佬告知下。。
现在硬盘已经降到40G了,看起来已经基本正常,没有特别大的目录了。但这是没有运行数据采集的前提下,不知道开采集后是否会空间继续飙升。看起来就是compaction太慢造成?从晚上8点停止采集到中午12点,10几个小时才把compaction消化完?这块的优化有什么配置参数可以参考吗
大佬,请问下,后面是怎么解决的,也遇到了同样的问题。
du -sh data/*|sort -rh|head 这个命令执行后返回需要多久,可以拿du -h --max-depth=1 这个命令替代么老师
1赞
可以的
求问后续有再出现这个问题吗,我也遇到了
这个问题有解决吗,大佬,我现在也有这个问题用的是Starrocks3.3,使用streamLoad进行多线程批量导入
这是个bug,暂时只能通过脚本清理。
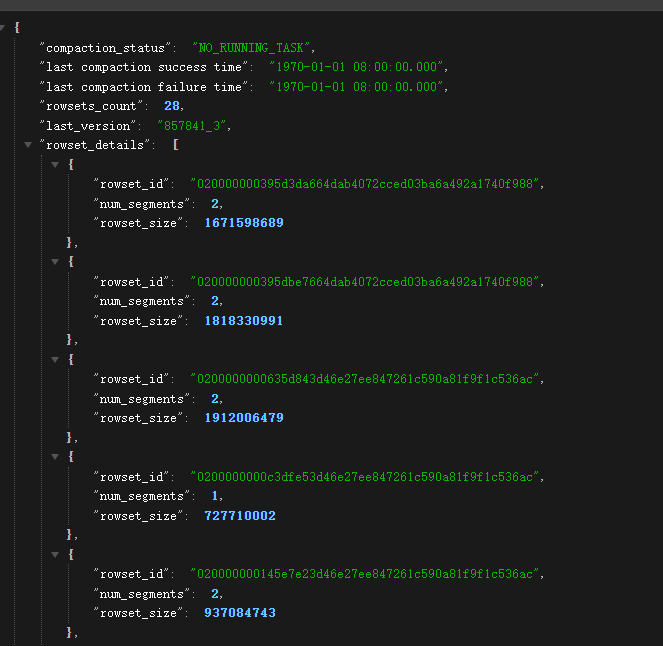
@jingdan 数据库专家您好, 我这个问题可能比较复杂;

占用空间最大的节点
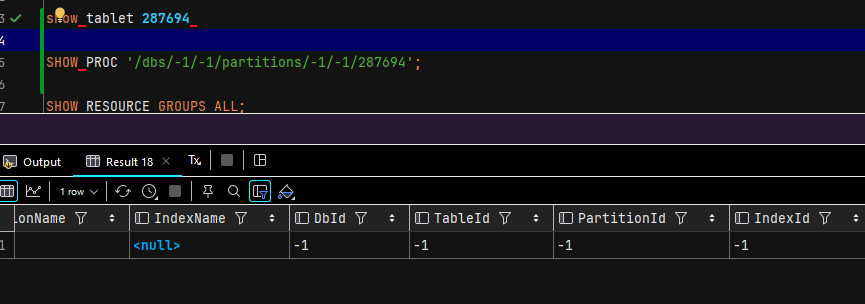
SHOW PROC '/dbs/-1/-1/partitions/-1/-1/287694';直接无效, 这种要怎么处理呢?
我的服务器存在直接断电的异常情况;
有很多异常的sql我会直接中断
是不是可以理解为, 只要
show tablet $tablet_id 找不到的, 我都可以rm -f
目前我使用下面的命令删除了,目前没发现啥问题
du -sh data/*/*|sort -rh|head -n 20
# 用下面的查
show tablet 836657
# 或者如果没有出现在下面的表中
select *
from information_schema.be_tablets
order by DATA_SIZE desc ;
# 准备删除
# 设置备份目录 (放在同一磁盘分区下移动速度最快)
export BACKUP_ROOT="/tmp/starrocks_zombie_backup"
# 定义待处理的文件列表
files=(
"~/project/strks/be/storage/data/49/287698"
"~/project/strks/be/storage/data/48/287696"
"~/project/strks/be/storage/data/47/287694"
"~/project/strks/be/storage/data/46/287692"
"~/project/strks/be/storage/data/45/287690"
"~/project/strks/be/storage/data/44/287688"
"~/project/strks/be/storage/data/43/287686"
"~/project/strks/be/storage/data/42/287684"
"~/project/strks/be/storage/data/41/287682"
"~/project/strks/be/storage/data/40/287680"
"~/project/strks/be/storage/data/39/287678"
"~/project/strks/be/storage/data/38/287674"
"~/project/strks/be/storage/data/37/287676"
"~/project/strks/be/storage/data/36/287672"
"~/project/strks/be/storage/data/35/287670"
"~/project/strks/be/storage/data/34/287668"
)
# 这里的 "删除" 实际上是移动到备份目录
echo "开始移动文件到备份目录: $BACKUP_ROOT ..."
for file in "${files[@]}"; do
# 展开波浪号 ~ (如果脚本直接运行,shell会自动展开,这里为了安全做个处理)
real_file=$(eval echo "$file")
if [ -e "$real_file" ]; then
# 构建备份目标路径,保留原始目录结构
# 比如源文件是 /a/b/c,备份目录就是 $BACKUP_ROOT/a/b/
rel_dir=$(dirname "$real_file")
dest_dir="$BACKUP_ROOT$rel_dir"
# 创建目标文件夹
mkdir -p "$dest_dir"
# 移动文件
mv "$real_file" "$dest_dir/"
echo "已移动: $real_file -> $dest_dir/"
else
echo "跳过 (文件不存在): $real_file"
fi
done
echo "操作完成。文件已安全移至 $BACKUP_ROOT"
# 逆操作:从备份目录恢复回原位
echo "开始恢复文件..."
# 注意:这里需要重新遍历备份目录中的文件,或者利用上面的 files 列表反向操作
# 为简单起见,利用 files 列表逻辑反向查找
for file in "${files[@]}"; do
real_file=$(eval echo "$file")
# 计算刚才备份时的路径
rel_dir=$(dirname "$real_file")
backup_path="$BACKUP_ROOT$real_file"
if [ -e "$backup_path" ]; then
# 确保原始目录存在 (以防万一父目录也被删了)
mkdir -p "$rel_dir"
# 移回原位
mv "$backup_path" "$real_file"
echo "已恢复: $real_file"
else
echo "警告: 在备份中未找到文件 $backup_path"
fi
done
echo "恢复完成。"
### 彻底删除文件,释放空间
# ⚠️ 警告:此操作不可逆
rm -rf "$BACKUP_ROOT"