背景
我们经常会遇到show backends中看到的已用空间跟磁盘空间占用不一致的问题,本文主要分享下这类问题的排查思路
排查思路
1.可能做过drop database或者drop table的操作,这些操作会在内存中保留1天(一天之内可以通过recover恢复数据,避免误操作),这个时候可能会出现,磁盘占用大于show backends中显示的已用空间,内存中保留1天可通过fe的参数 catalog_trash_expire_second调整,调整方式
admin set frontend config ("catalog_trash_expire_second"="xxxx") #如果需要持久化,记得加到fe.conf中
2.可能是上面内存中的数据过了1天后进入到trash目录(${storage_root_path}/trash),该数据默认会在trash目录保留3天,这个时候也会出现磁盘占用大于show backends中显示的已用空间,trash保留时间由be的配置 trash_file_expire_time_sec(默认259200,3天),调整方式
curl http://be_ip:be_http_port/api/update_config?trash_file_expire_time_sec=xxx #如果需要持久化,记得在be.conf中配置
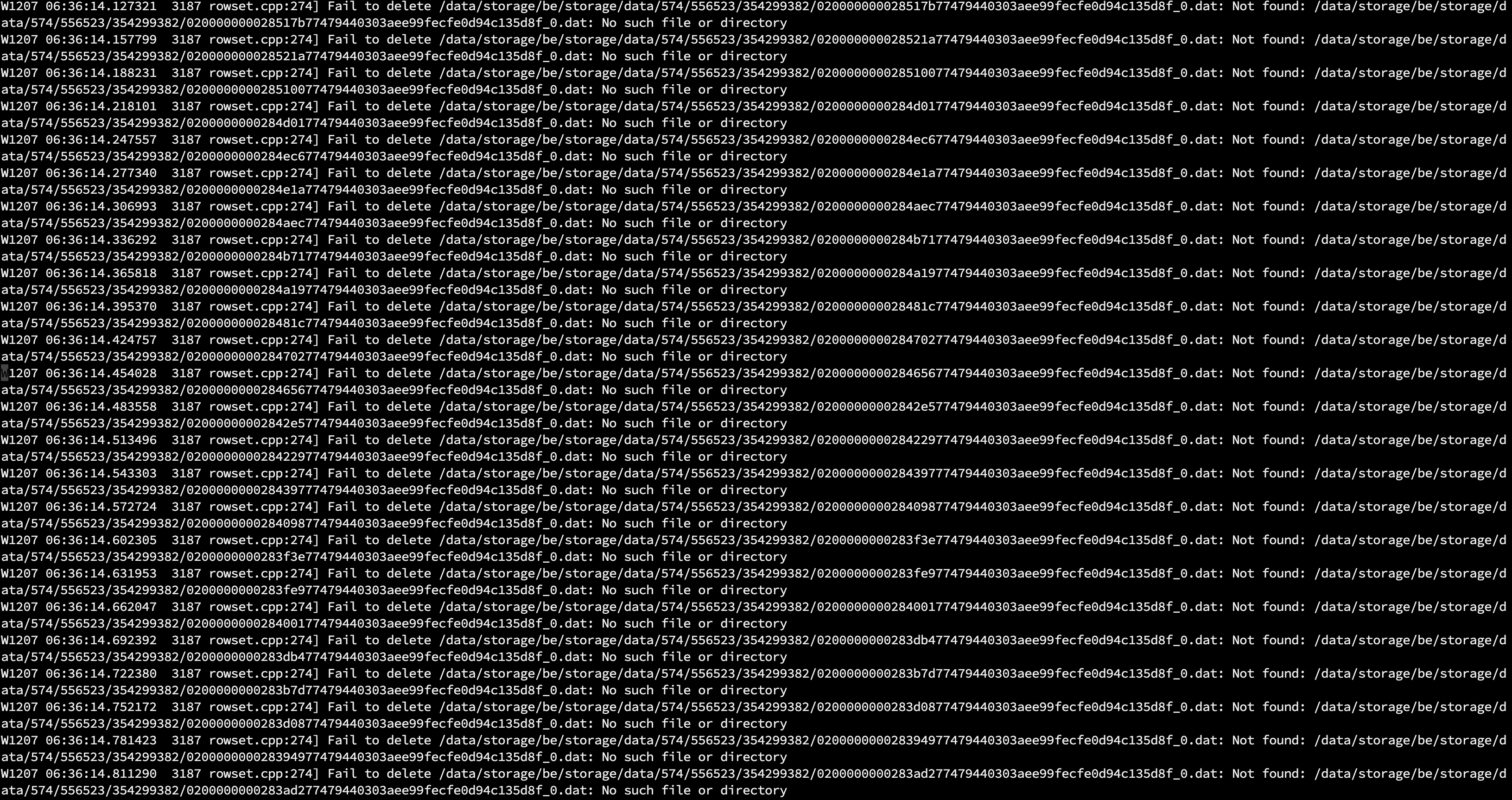
3.可能还存在一些bug的情况下会导致data目录占用比show backends看到的大,这个时候需要逐级目录检查是哪个tablet
starrocks的数据存储路径组成如下
storage_root_path/data/${slot_id}/${tablet_id}/${schema_hash}/${rowset_id}_${segment_id}.dat
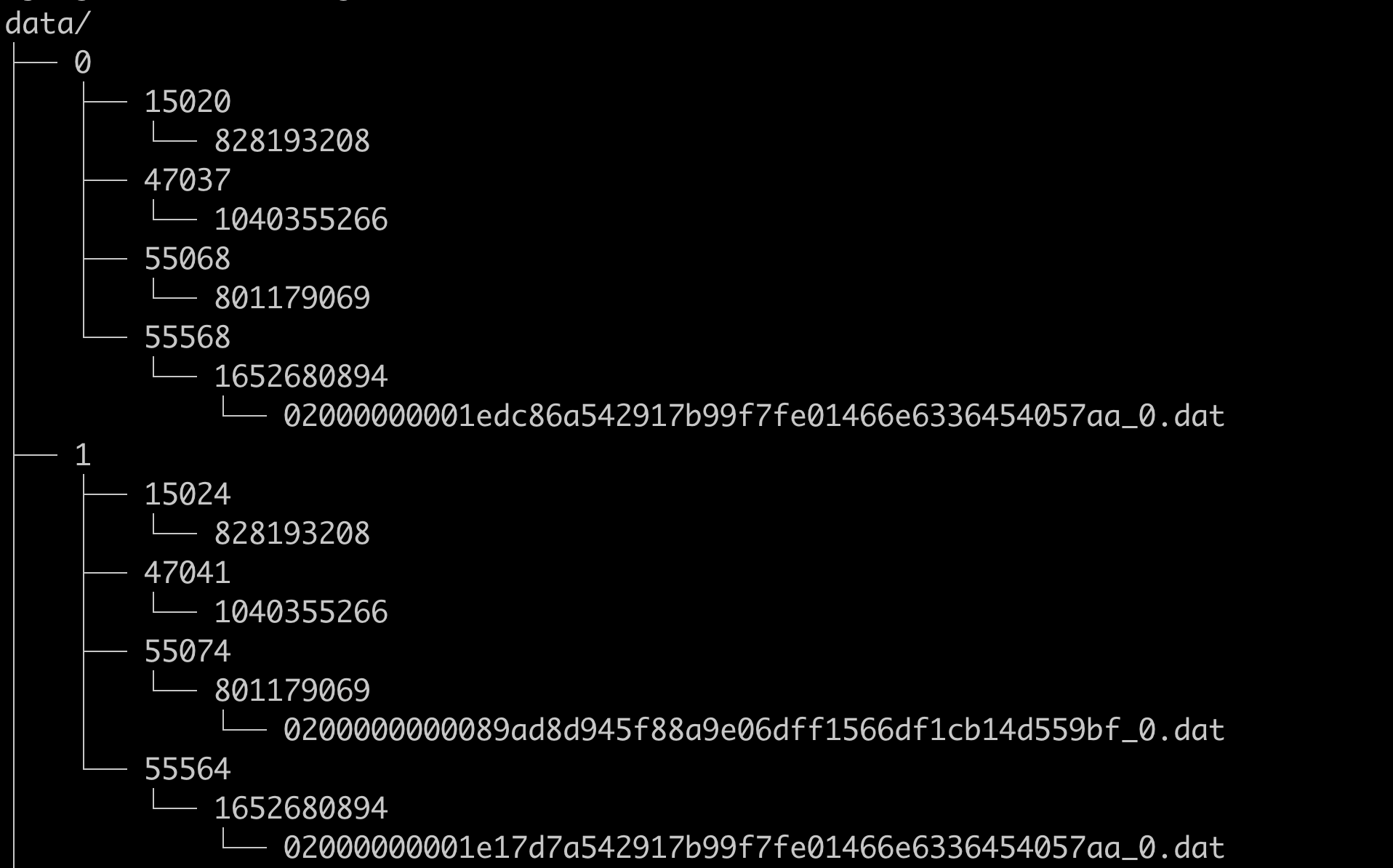
通过如下指令一级一级定位到tablet id粒度就可以
du -sh data/* --max-depth=1|sort -rh|head
上一步查出来的slot目录,进一步查看是哪个tablet
du -sh data/${slot_id}/* --max-depth=1|sort -rh|head
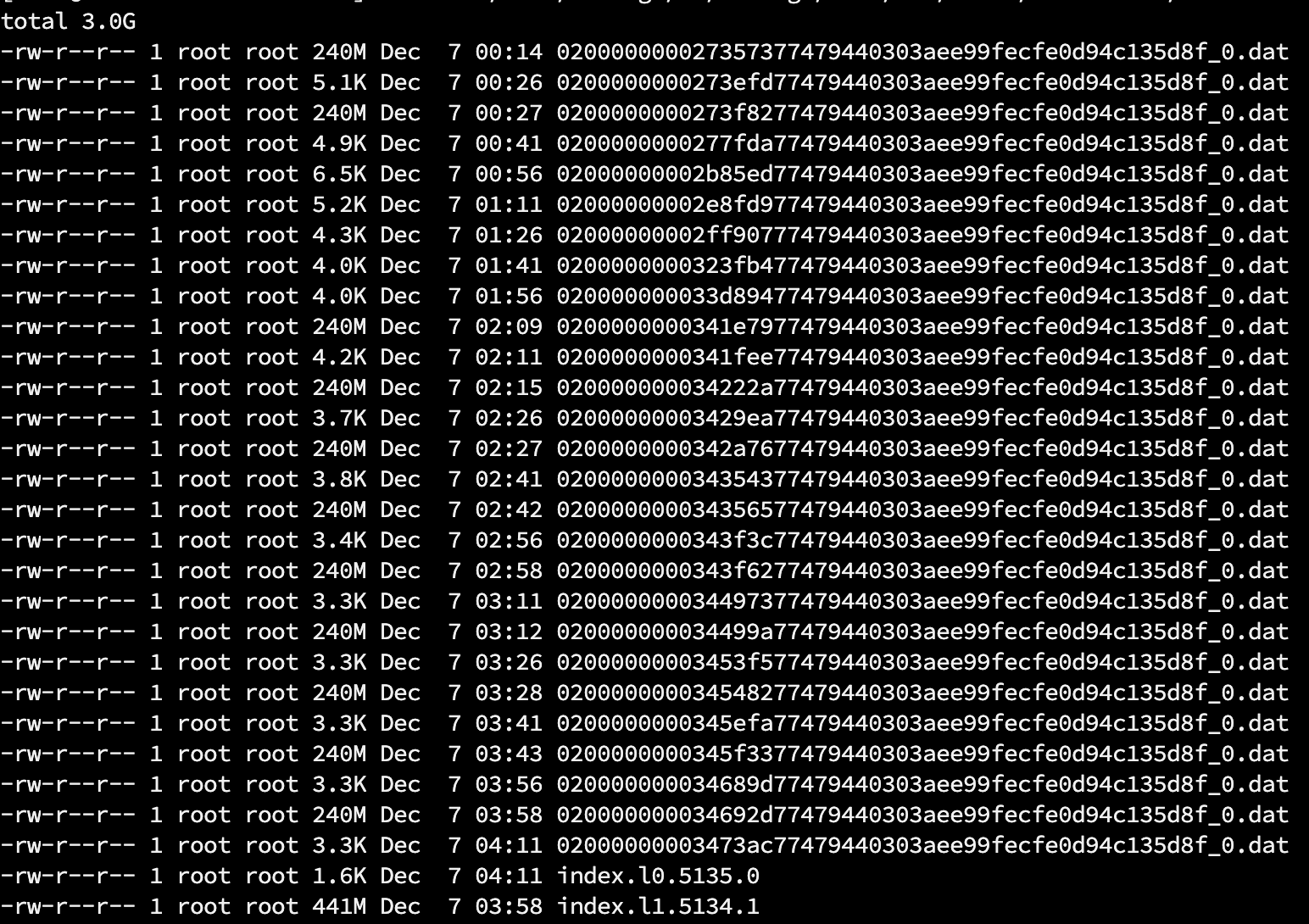
 主键模型除了关注.dat以外,还需要关注下 pk下可能有.dat,.col,.upt和index.x.x大小
主键模型除了关注.dat以外,还需要关注下 pk下可能有.dat,.col,.upt和index.x.x大小
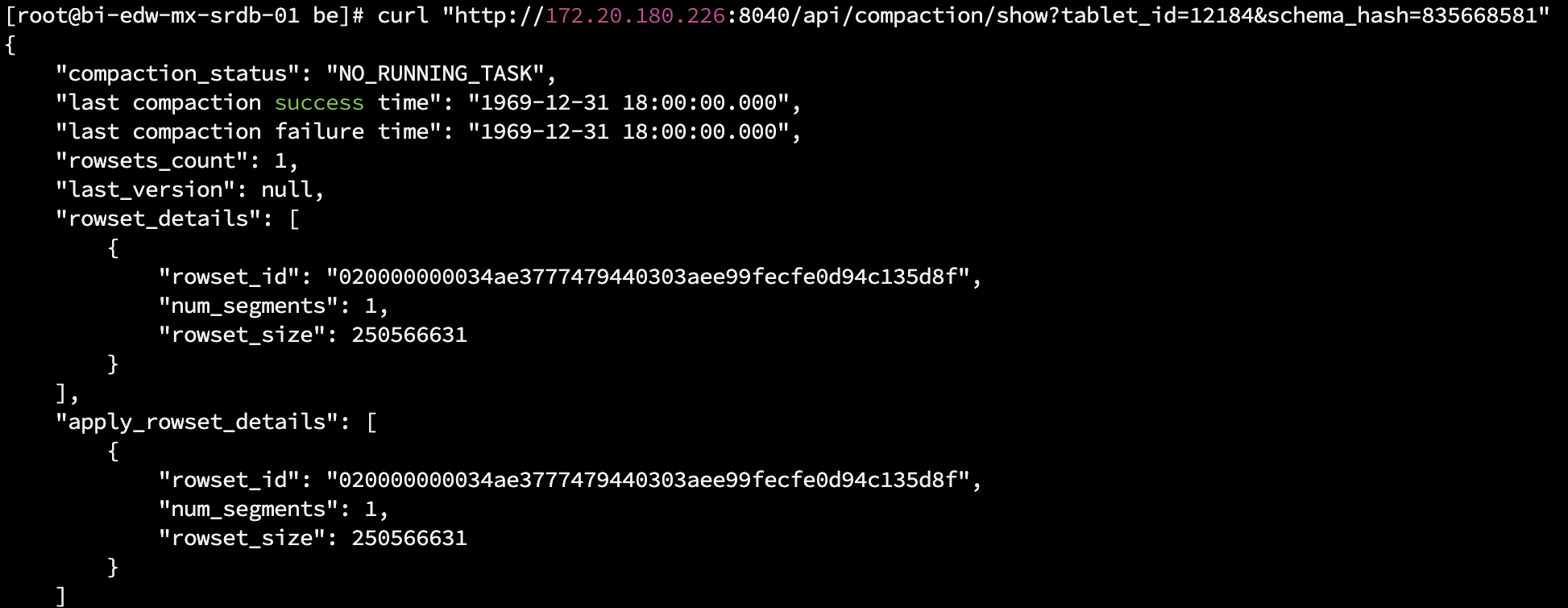
然后连接leader fe(:一定是leader fe),查看tablet的compaction是否正常
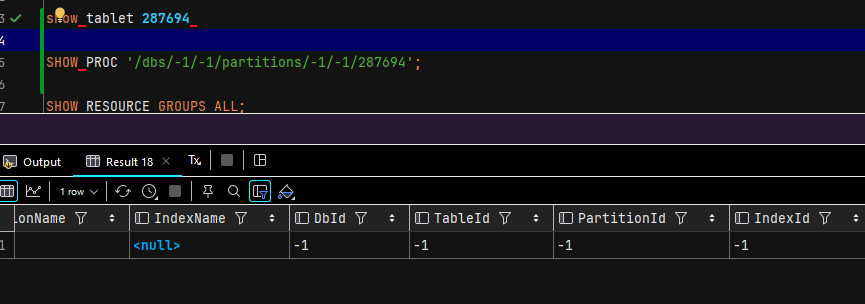
show tablet $tablet_id; #获取最后一列Detailcmd的值
show PROC '/xxx';
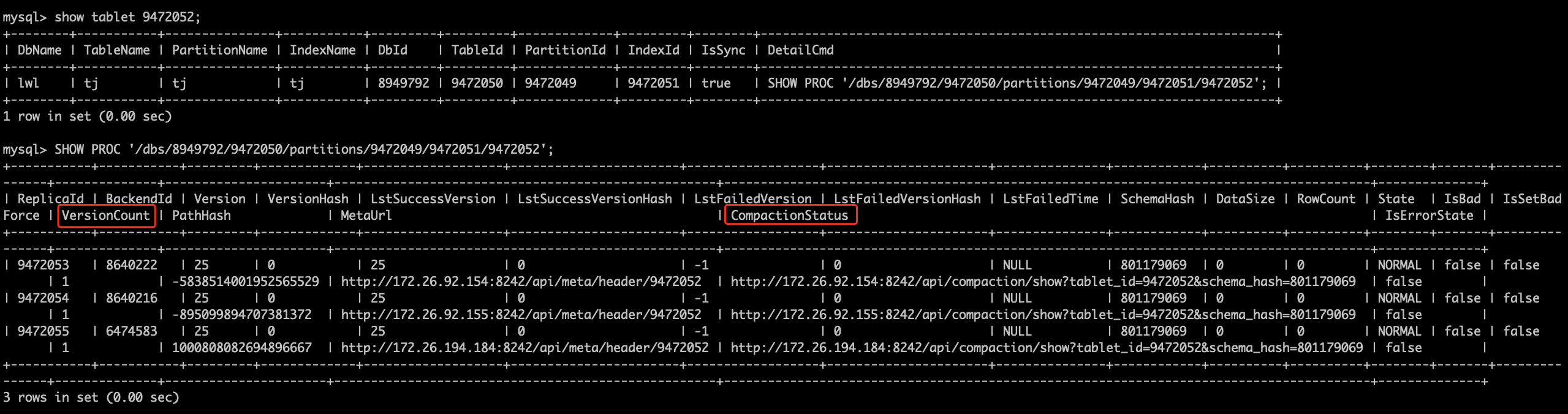
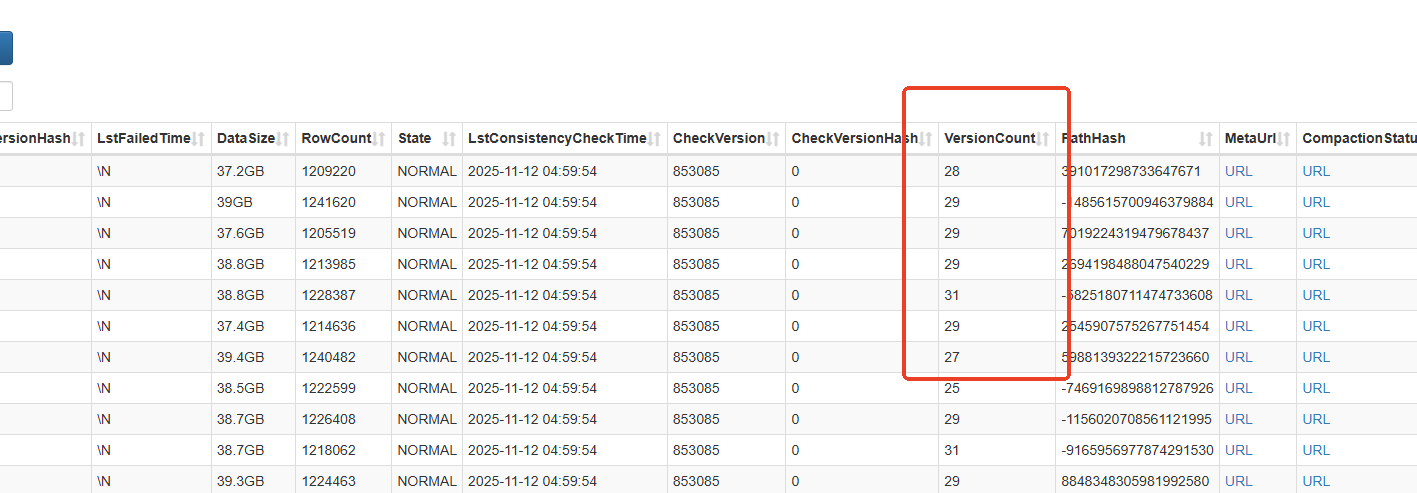
如果只有一个副本的 VersionCount 异常高(超过1000),可以考虑临时set bad恢复
ADMIN SET REPLICA STATUS PROPERTIES("tablet_id" = "xxx", "backend_id" = "xxx", "status" = "bad");
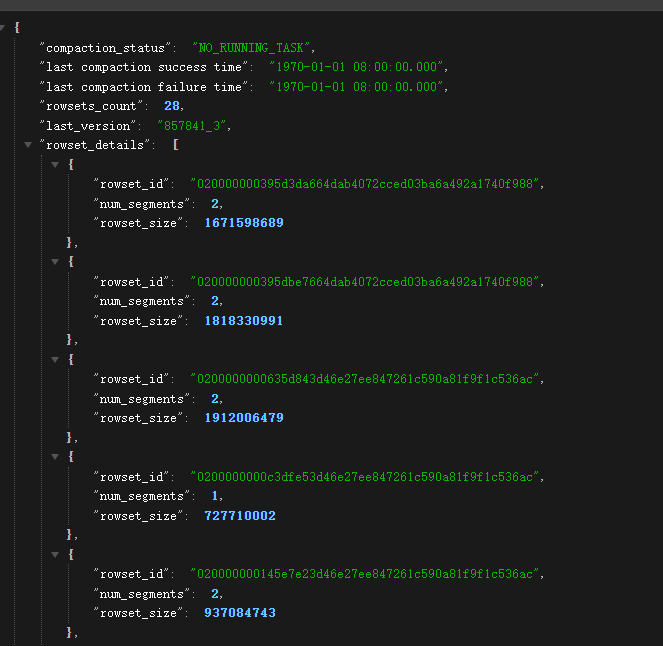
如果都比较高,需要看下compaction状态如何,打开CompactionStatus字段对应的compaction url,返回结果集如下
非主键模型
{
"cumulative point": 2,
"last cumulative failure time": "1970-01-01 08:00:00.000",
"last base failure time": "1970-01-01 08:00:00.000",
"last cumulative success time": "1970-01-01 08:00:00.000",
"last base success time": "2023-11-03 00:45:25.272",
"rowsets": [
"[0-25] 0 DATA NONOVERLAPPING"
],
"stale version path": []
}
一般需要关注last cumulative failure time、last base failure time和rowsets
last cumulative failure time:最近一次增量合并失败的时间
last base failure time:最近一次base合并失败的时间
rowsets:当前待合并的rowset,[0-xx]表示的已经完成base 合并的,[123-123]表示的未完成任何合并的,[110-123]表示完成增量合并的,如果有大量的[123-123]前后连续的rowset,说明导入频率非常高或者增量合并没有正常进行或者合并太慢了。
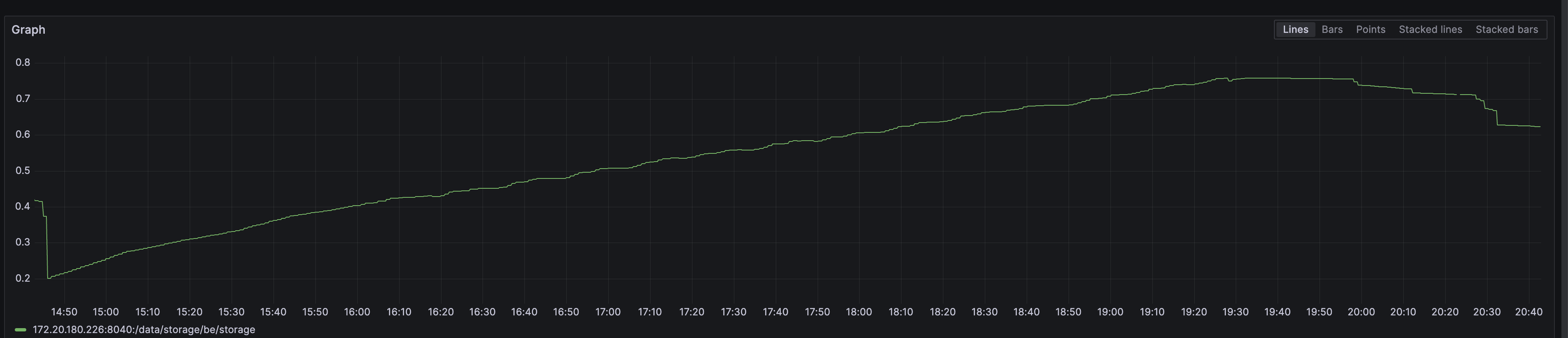
如果这个分区一直有数据写入,并且最近一次的合并时间是几天前,需要查看对应be的日志,看下compaction失败的原因,通过在be.INFO中过滤对应的tablet id即可看到上下文
增量合并
grep -E 'tablet_id:${tablet_id}(.*)compaction_type:cumulative' be.INFO #需要把:${tablet_id}替换为上文检查出来失败的tablet id

base合并
grep -E 'tablet_id:${tablet_id}(.*)compaction_type:base' be.INFO #需要把:${tablet_id}替换为上文检查出来失败的tablet id

主键模型
{
"last compaction success time": "2023-11-22 16:54:43.139",
"last compaction failure time": "1970-01-01 08:00:00.000",
"rowset_version": "tablet:9456211 #version:[6_0] rowsets:3",
"rowsets": [
"id:6 #seg:1",
"id:7 #seg:0",
"id:8 #seg:0"
]
}
last compaction failure time:最近一次合并失败的时间
rowsets:待合并的版本个数
也可以尝试手动compaction
非主键表
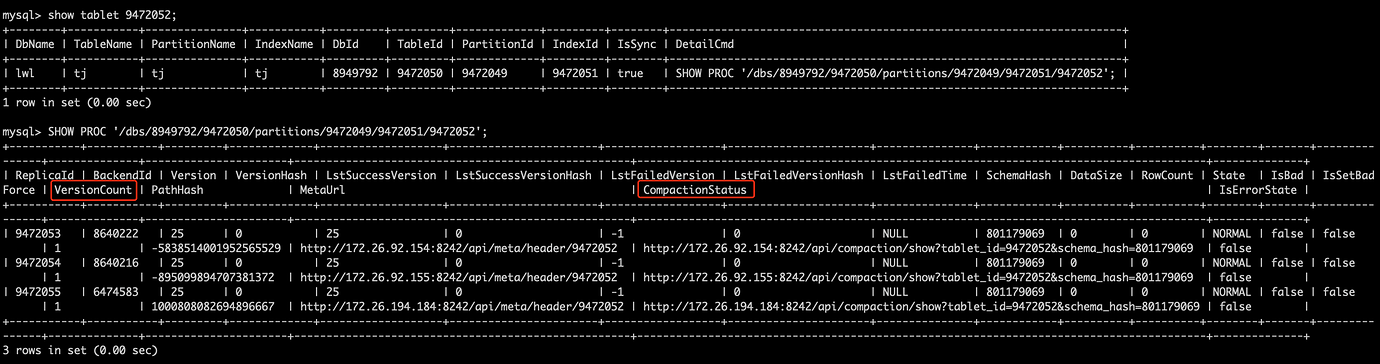
下文中的schema_hash为上图中CompactionStatus中对应的schema_hash
增量合并
curl -XPOST 'http://<be_ip>:<be_port>/api/compact?tablet_id=xxx&schema_hash=xxx&compaction_type=cumulative'
base合并
请谨慎操作,如果版本较多,会占用比较多的CPU、内存和磁盘资源
curl -XPOST 'http://<be_ip>:<be_port>/api/compact?tablet_id=xxx&schema_hash=xxx&compaction_type=base'
主键表
rowset_ids 为上文compactionstatus url结果中的rowsets id,例如上文中的6,7,8
curl -XPOST 'http://<be_ip>:<be_port>/api/compact?compaction_type=update&tablet_id=<tablet_id>&rowset_ids=xxx,xxx,xxx'

也可以不指定rowset id,直接指定到tablet id即可
curl -XPOST 'http://<be_ip>:<be_port>/api/compact?compaction_type=update&tablet_id=<tablet_id>'
2.5 版本支持按照分区粒度触发主键模型合并
10002 为backend id,通过show backends可以看到,10089为partition id,通过show partitions from $table 可以看到,1000000为需要合并的数据条数
admin execute on 10002 'StorageEngine.submit_manual_compaction_task_for_partition(10089, 1000000)
System.print(StorageEngine.get_manual_compaction_status())';
admin execute on 10002 'System.print(StorageEngine.get_manual_compaction_status())';