
为了更快的定位您的问题,请提供以下信息,谢谢
【详述】全表查询 hive catalog 中存储于 hdfs 上的外表时(量级为六千万),设置pipeline_dop=1时会明显加快查询速度,pipeline_dop=0时查看profile也只用到一个pipeline实例,这种性能优化是如何实现的
【背景】创建hive catalog时使用的为默认参数,只更改hms url,未开启data cache与query cache,只更改了pipeline_dop参数
【业务影响】
【StarRocks版本】例如:3.1.0
【集群规模】例如:3fe+3be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【联系方式】为了在解决问题过程中能及时联系到您获取一些日志信息,请补充下您的联系方式,例如:社区群4-小李或者邮箱,谢谢
【附件】
pipeline_dop=0.txt|attachment (28.1 KB)
pipeline_dop=1.txt|attachment (23.0 KB)
show variables like “%pipeline%”; 麻烦执行下这个 获取下pipeline的参数 然后重新修改dop=0 重启一个连接 生成下profile
1、
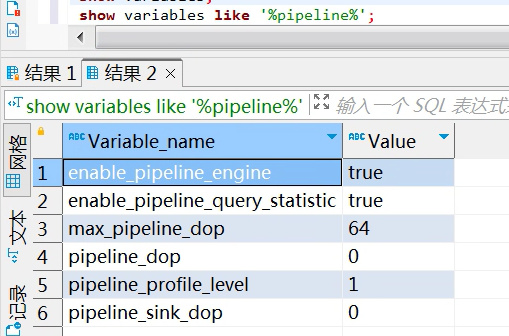
2、set pipeline_dop=0;
3、select * from hive_metastore_catalog.tpch_hive_parquet.lineitem limit 100;
pipeline_dop=0 (2).txt|attachment (28.1 KB)
Hi,大佬,这个有进展吗