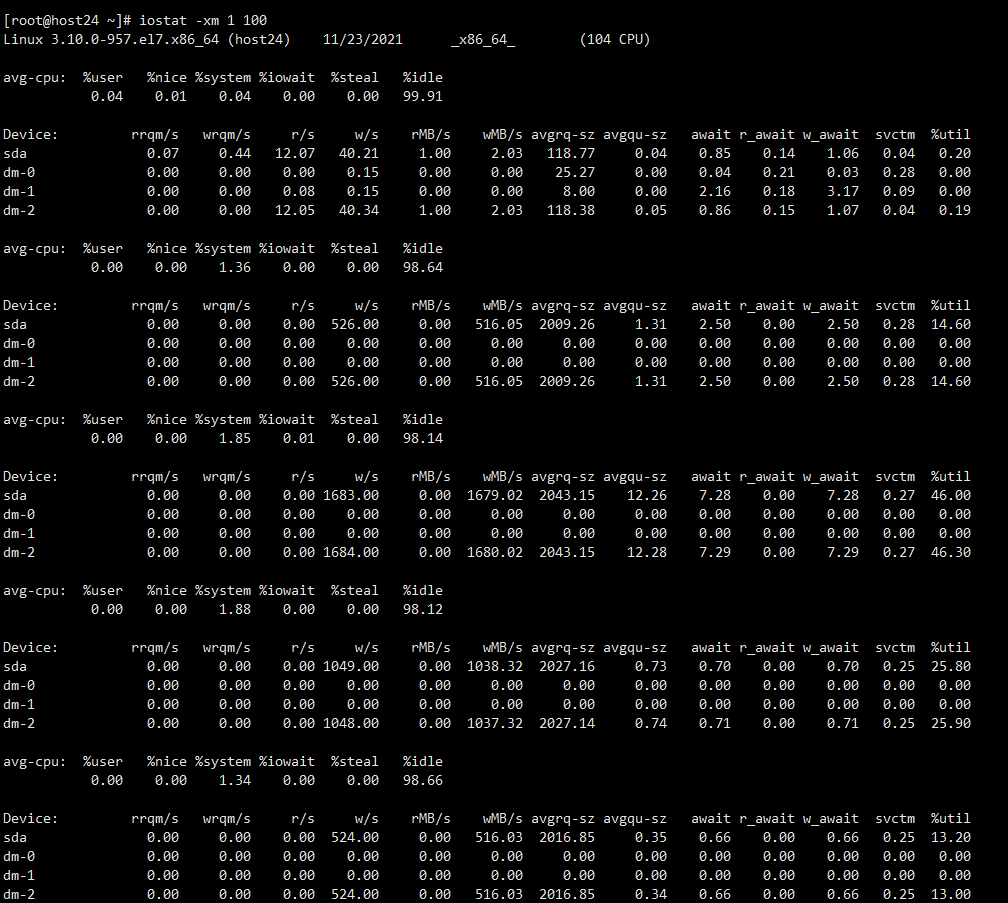
【详述】通过Stream Load的方式导数,表lineitem,数据量753G/5999989709行,本地csv文件,导入状态显示成功,但是数据并没有显示,在mysql中查看时,集群也挂了,具体情况:
第一次导入,nohup curl --location-trusted -u root: -H “label:lineitem1t” -H “column_separator:|” -H “timeout:259200” -T /home/starrocks/2.18.0_rc2/dbgen/1tdata/data/lineitem.tbl http://192.168.4.24:8040/api/tpch/lineitem/_stream_load > lineitem.log 2>&1 &,失败,日志记录最开始预估需要两个半小时,最后失败的时候时间预估为20分钟,不理解是什么原因造成的,反正最后失败了。


第二次导入,nohup curl --location-trusted -u root: -H “label:lineitem1t” -H “column_separator:|” -H “timeout:259200” -T /home/starrocks/2.18.0_rc2/dbgen/1tdata/data/lineitem.tbl http://192.168.4.24:8040/api/tpch/lineitem/_stream_load > lineitem_2.log 2>&1,失败,日志记录和第一次导入类似,刚开始预估时间近3个小时,最后失败时只有20多分钟,可能跟读写速度有关吧。


由于前面导数时,同样的导数操作多执行几遍有可能会成功的经验,执行了第三次导入,日志记录导入成功,如下,但是mysql查数时显示be挂了,具体操作步骤如下:
前一天晚执行导入操作nohup curl --location-trusted -u root: -H “label:lineitem1t” -H “column_separator:|” -H “timeout:259200” -T /home/starrocks/2.18.0_rc2/dbgen/1tdata/data/lineitem.tbl http://192.168.4.24:8040/api/tpch/lineitem/_stream_load > lineitem_3.log 2>&1 &
第二天早首先查看日志,显示导入成功(很惊喜),导入时常接近5个小时,如下图
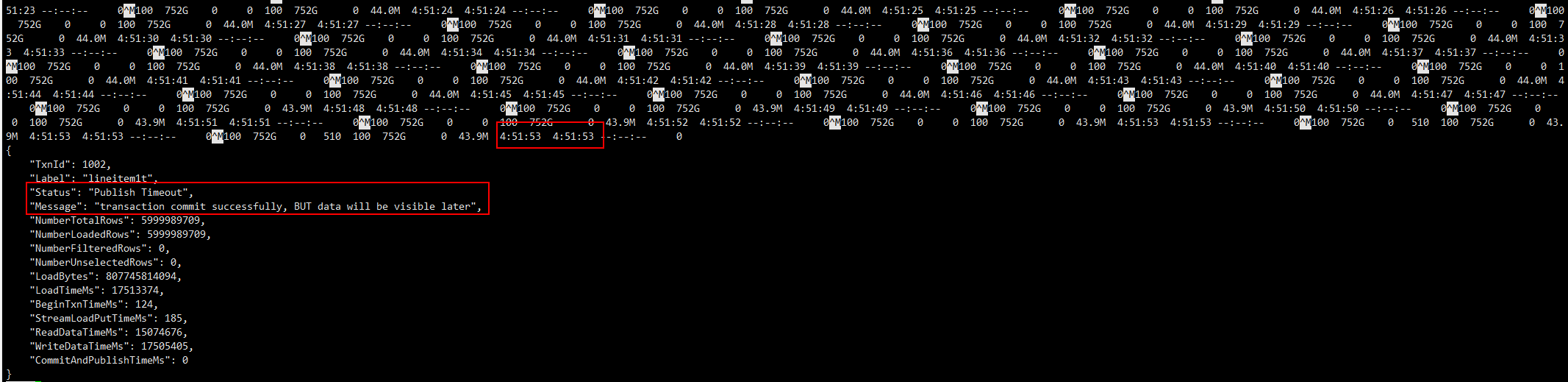
然后去mysql客户端查询,看看数据量,显示没有可用的BE
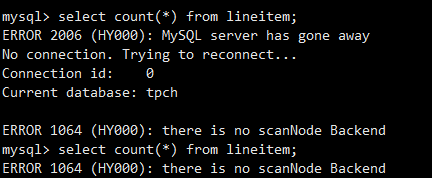
查看后台进程,没有BE,于是开启BE

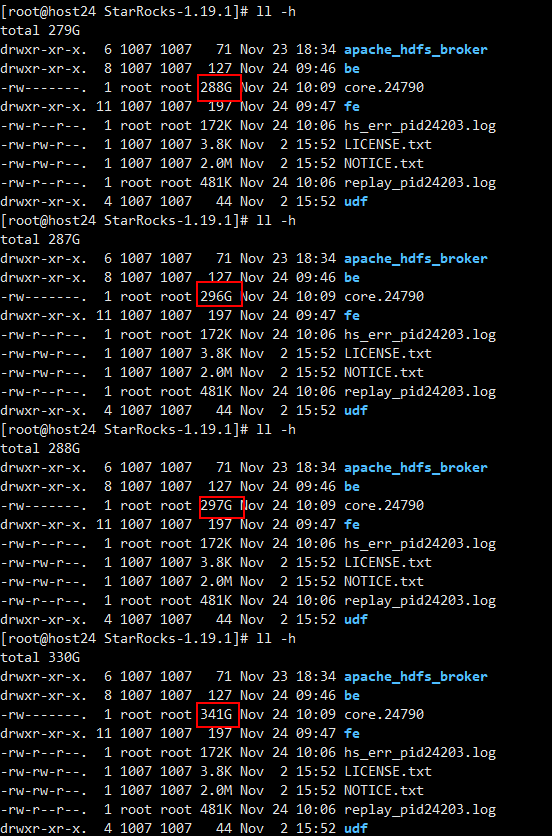
然后在mysql查询,数据量为0,接着我查看了be的状态,好家伙,直接给fe整挂了…(PS:执行了后面的操作之后,反过来看我怀疑不是因为我查询be状态整挂的。)
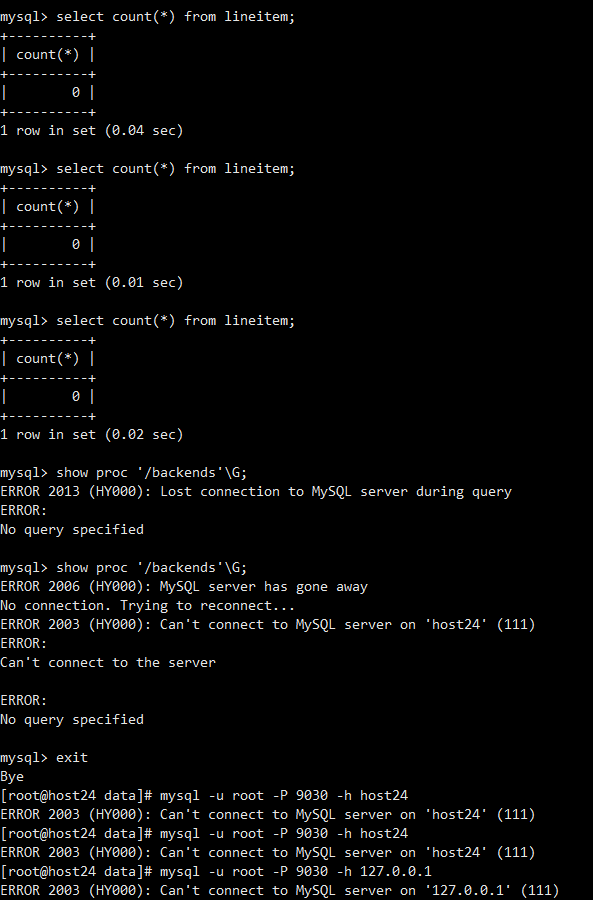
然后我去开启FE,FE就一直开不起来…
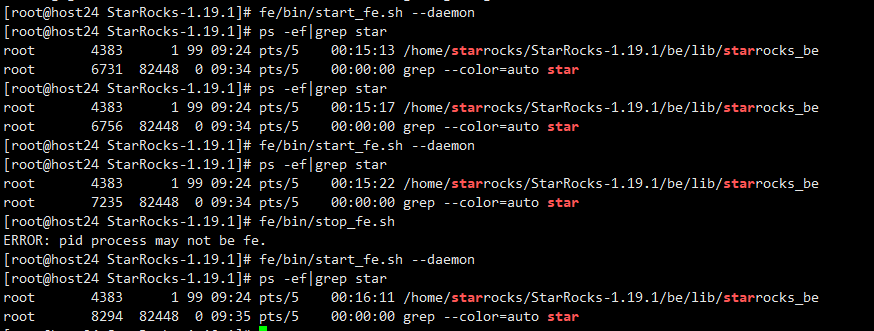
观察了一下,虽然FE没有起来,系统IO很高,内存也是从10几G飙升到100多G,猜测是不是BE在那写个已经commit但是没有显示在表中的数据…
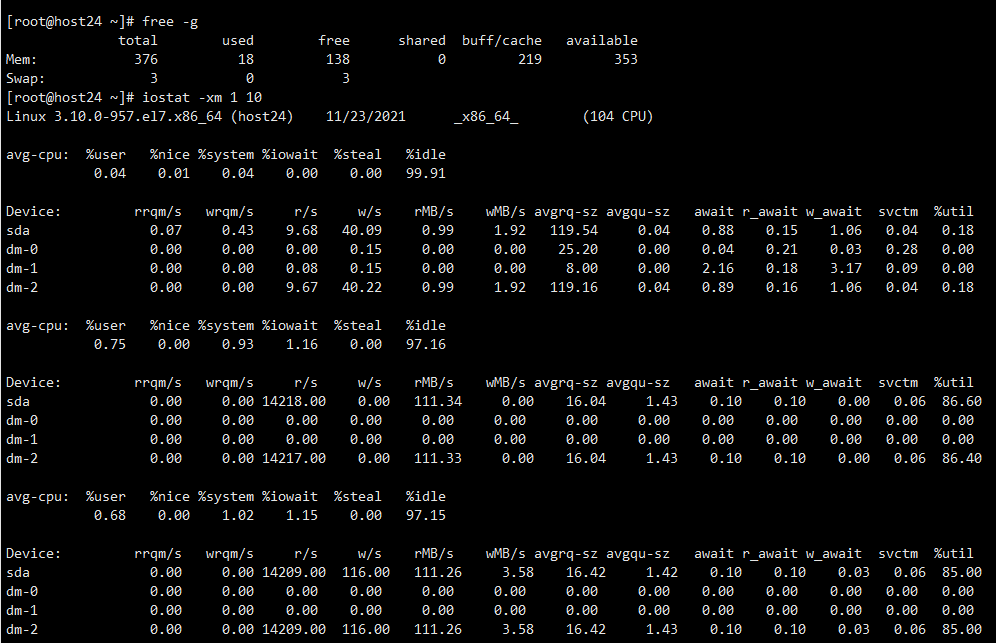
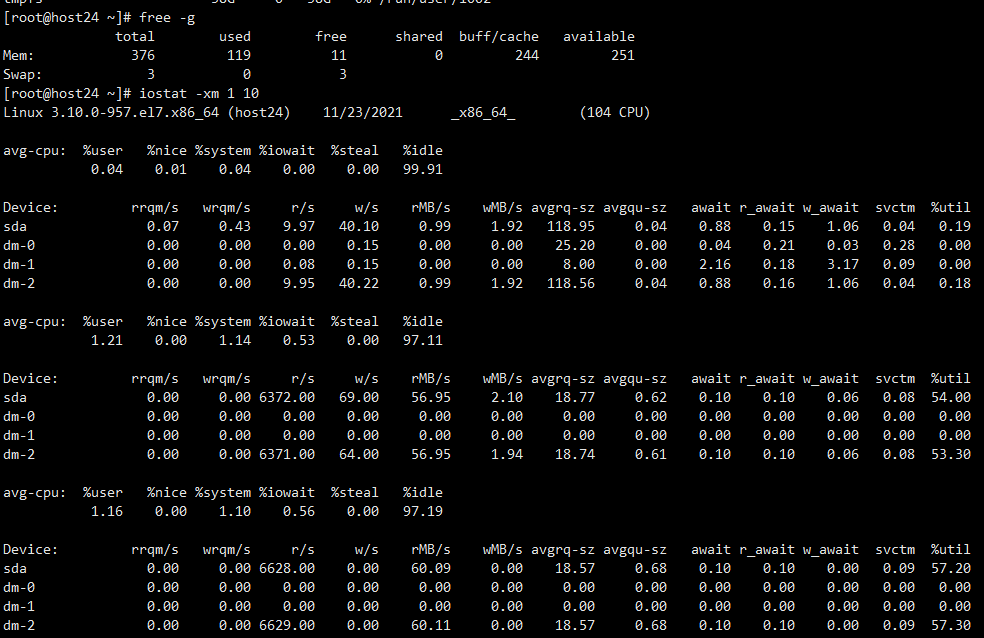
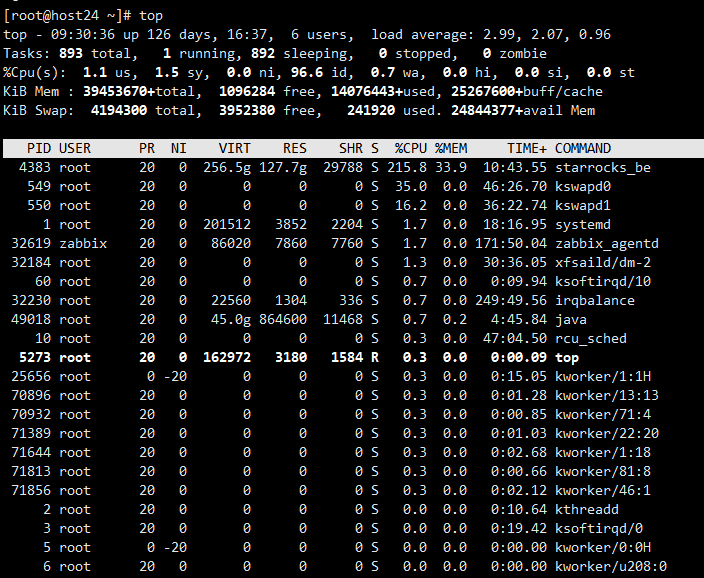
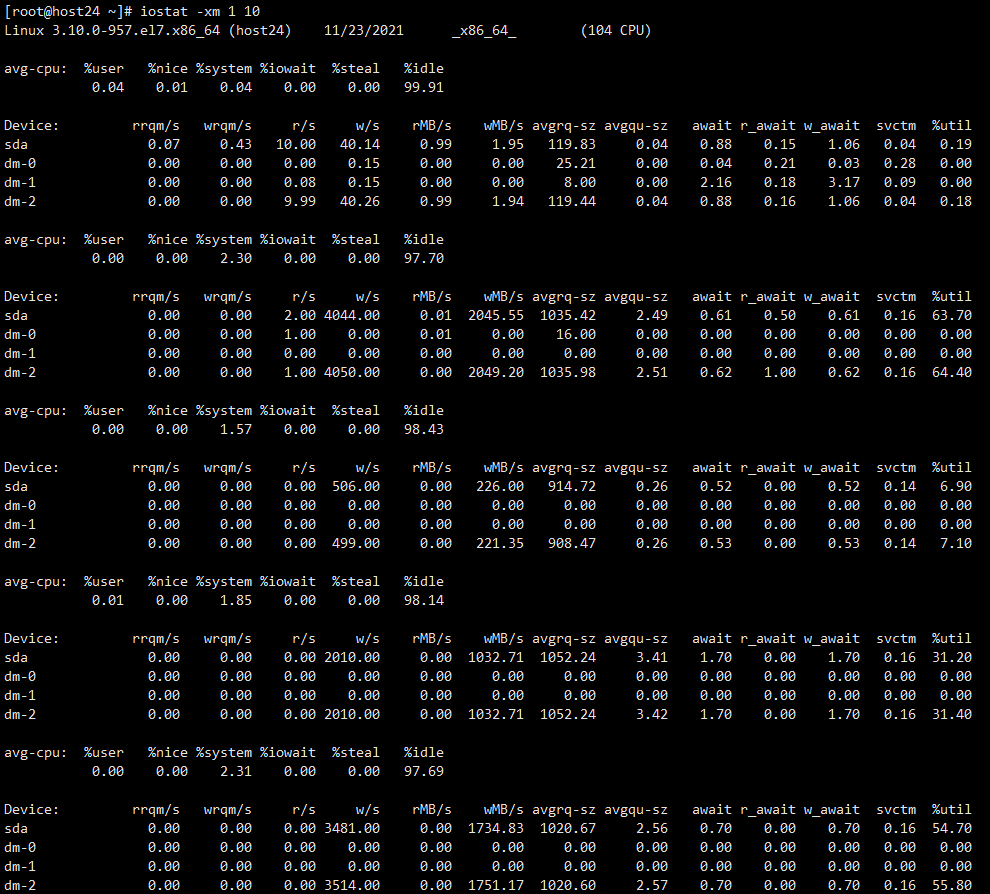
过了一段时间,观察IO已经降下去了,想着数据是不是写完了,就去试试开启fe,fe开启成功,结果发现be也没了,就把be也开启了

连接mysql,查看be alive是true,查询数据,还是为空,准备再等待一段时间后再观察数据是否写入。
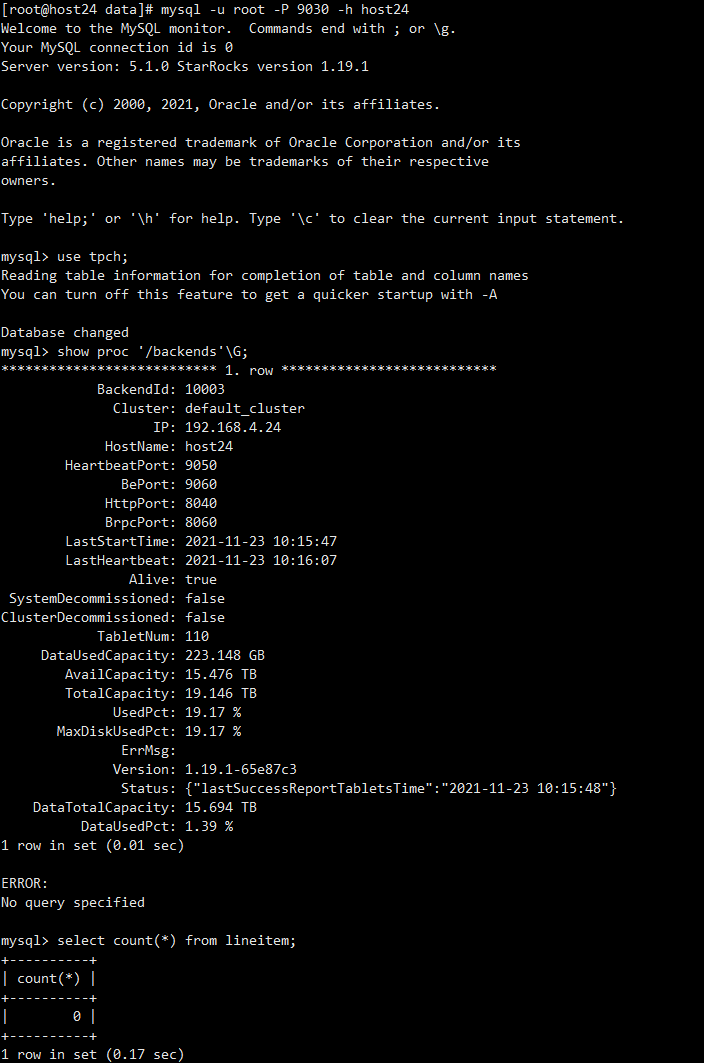
(一段时间过后…大概十来分钟吧)
去mysql查询数据,发现又连接不上了,看这报错就是估计就是FE挂了
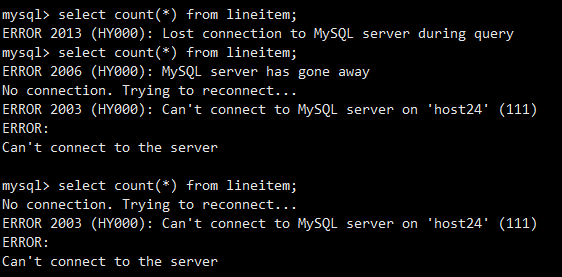
查看后台进程,FE果然没了

查看此时的IO,难道又开始写了???写的时候还给把fe隐藏不让操作,减少资源消耗???好吧,再等等,让它先写完,莫急(其实此时应该就跟我上个步骤中重启集群数据写入是一样的情况了)
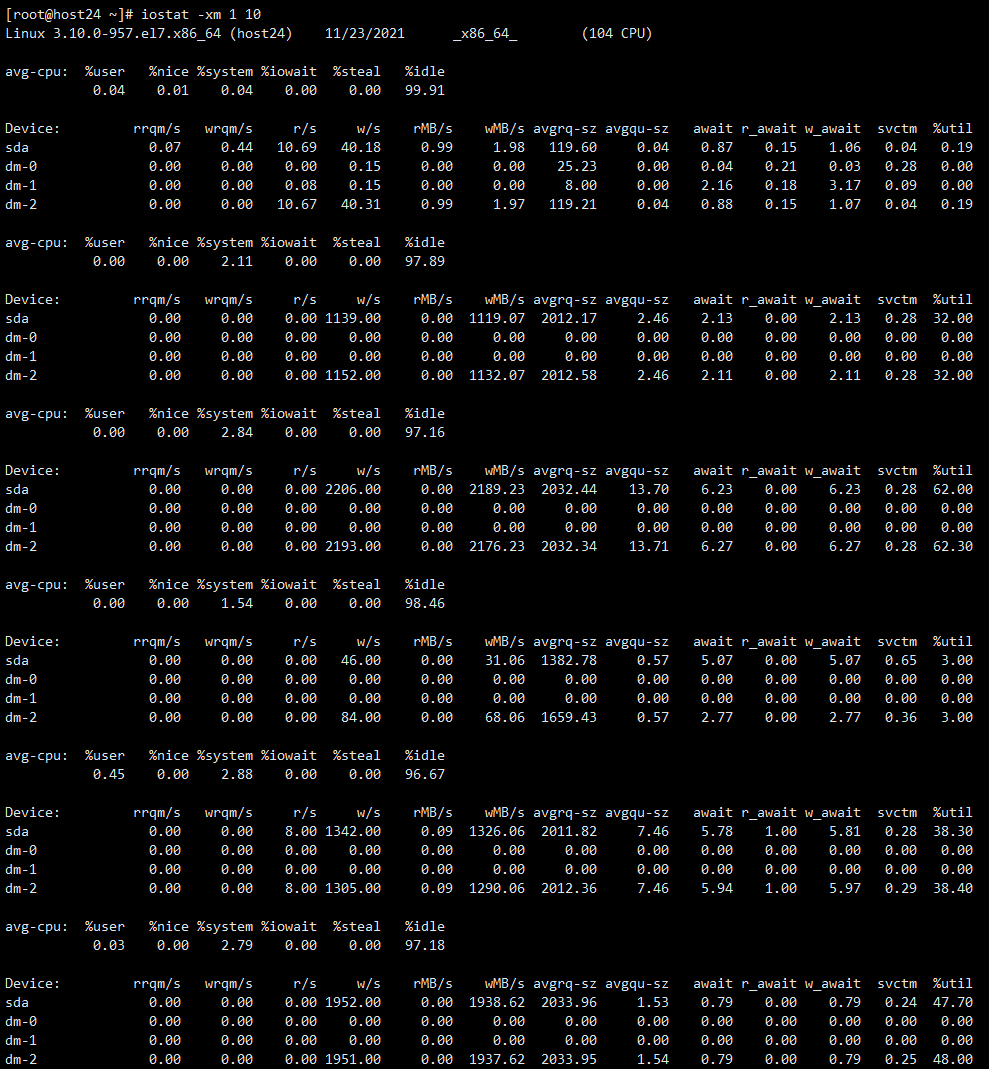
(又一段时间过后…)
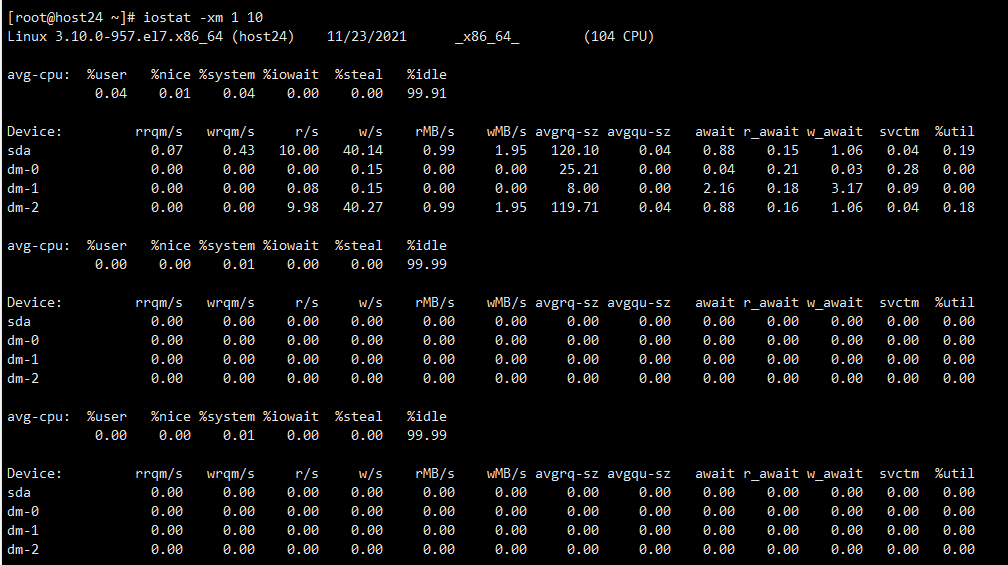
观察IO又降下去了
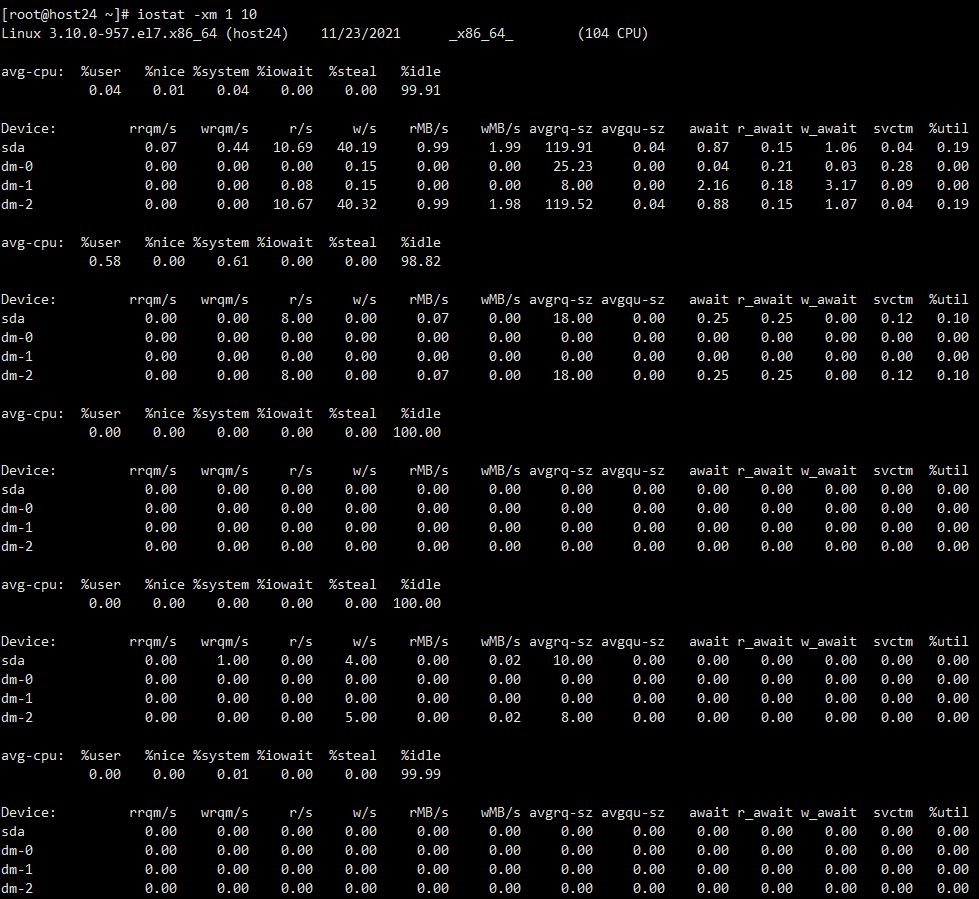
此时发现be也没了(不知道是因为写完了导致IO降下来,还是be先挂了,没得写了IO才降下来)
观察be.WARNING,不是特别明白…(此时有个想法,是因为之前load data虽然commit了,但是没有落盘,be就挂了?导致现在一起开be就开始恢复写入??然后又挂…循环???)

开启fe和be,再观察一下
已开启fe和be,观察IO,一下子就飙升上来,那就先等数据读写完,IO降下来,再连mysql去看结果吧,以防因为查看资源争用的原因导致集群挂了。
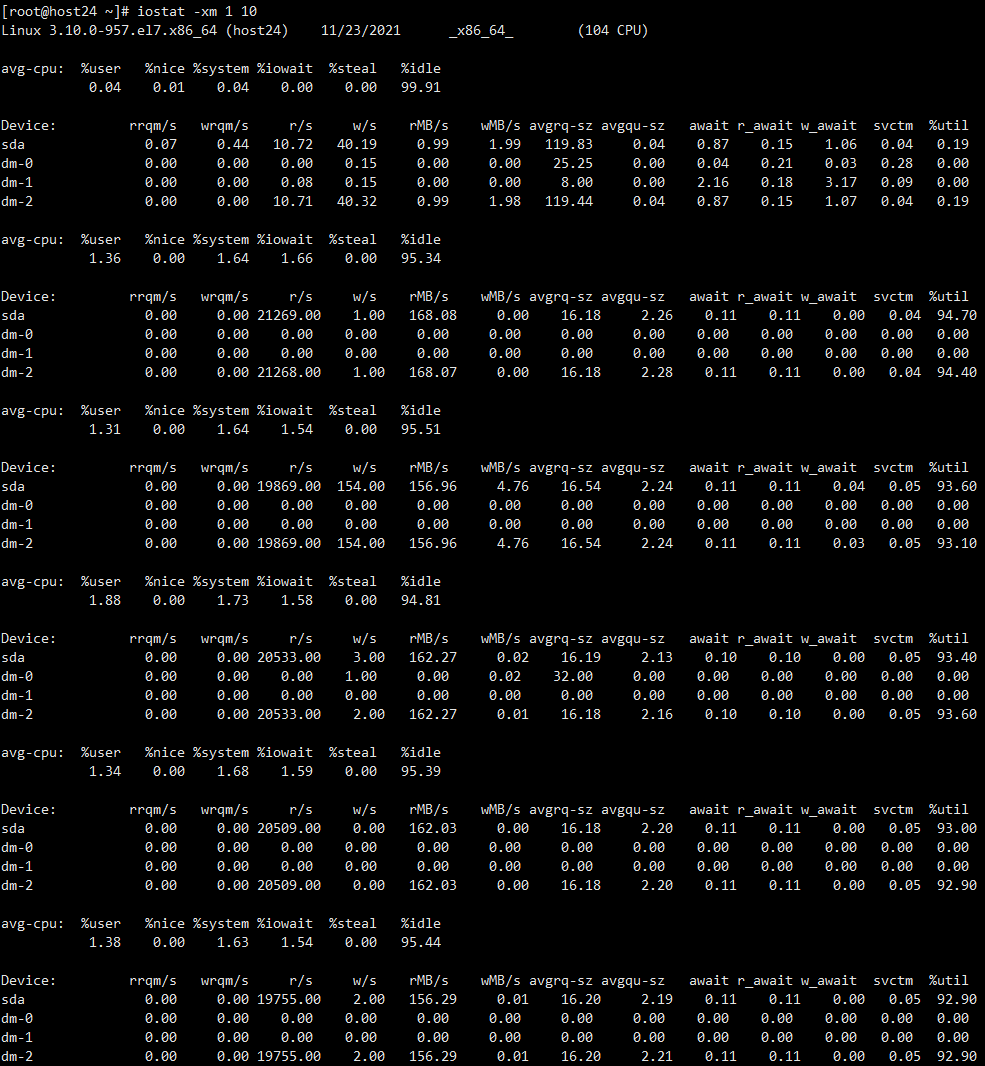
(3000 years later…)
观察IO已经降下去
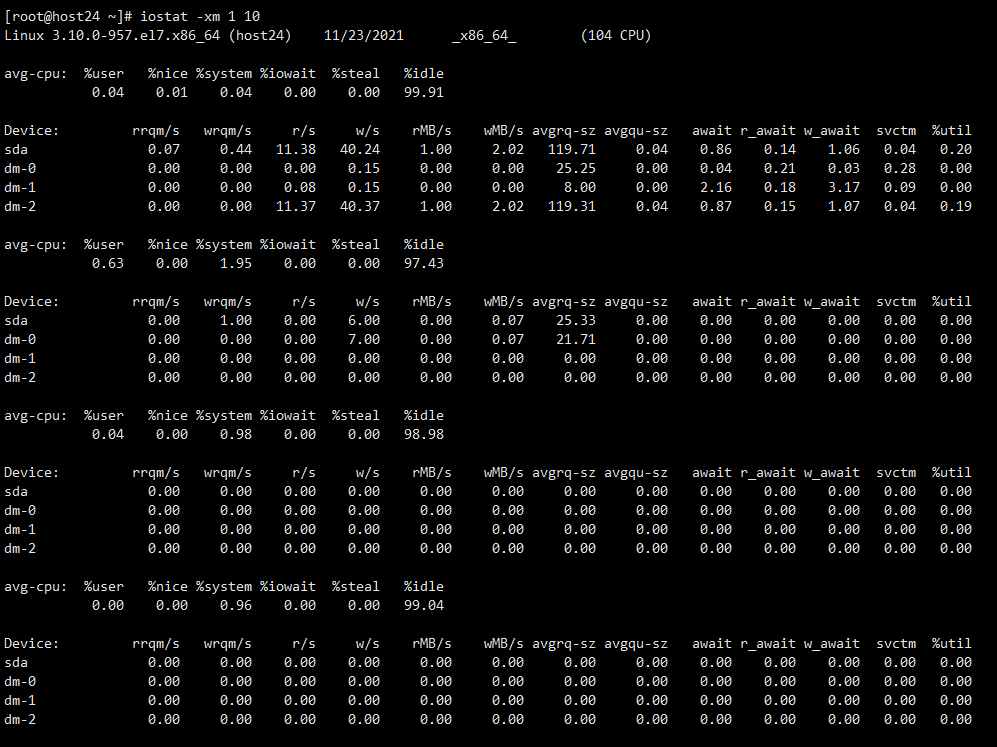
观察集群状态,这个怕[starrocks_be]不知道是个啥,fe和be进程没了…看样子是恢复的时候自己把自己给整挂了…

查看be.WARNING

fe.warn.log如下

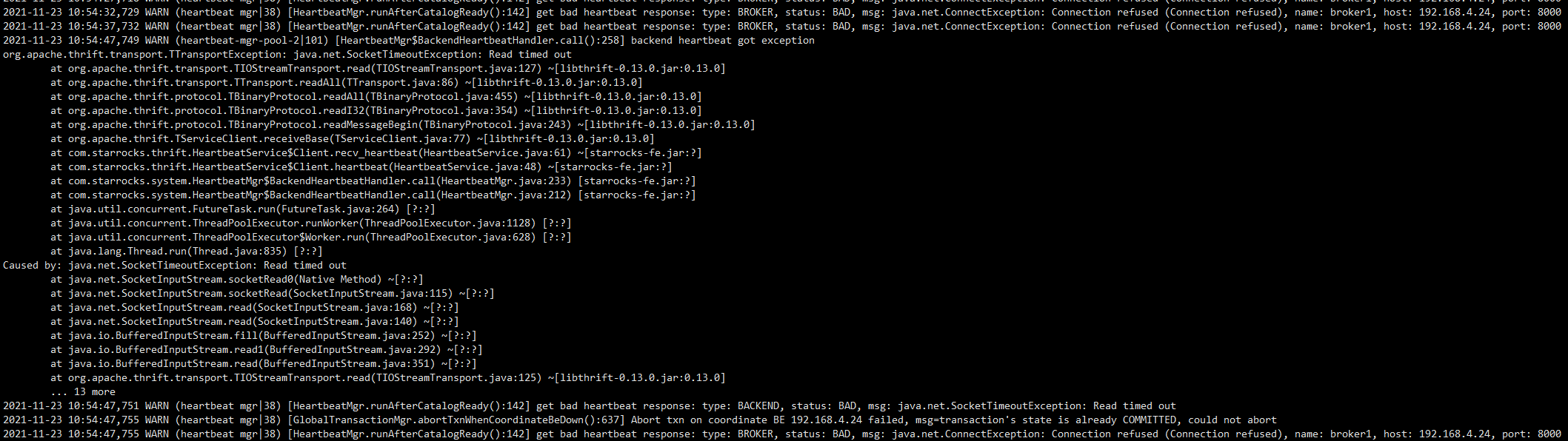
小结:目前看来一开起集群,就开始疯狂读写,然后把自己整挂,死循环,有没有方法可以解决这个问题?
【导入/导出方式】Stream Load
【StarRocks版本】1.19.1
【集群规模】1fe+1be+1broker
【机器信息】104C/376G/万兆