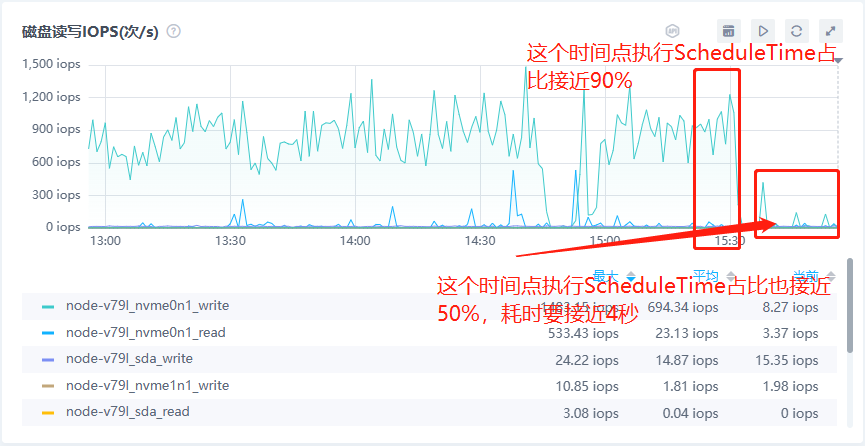
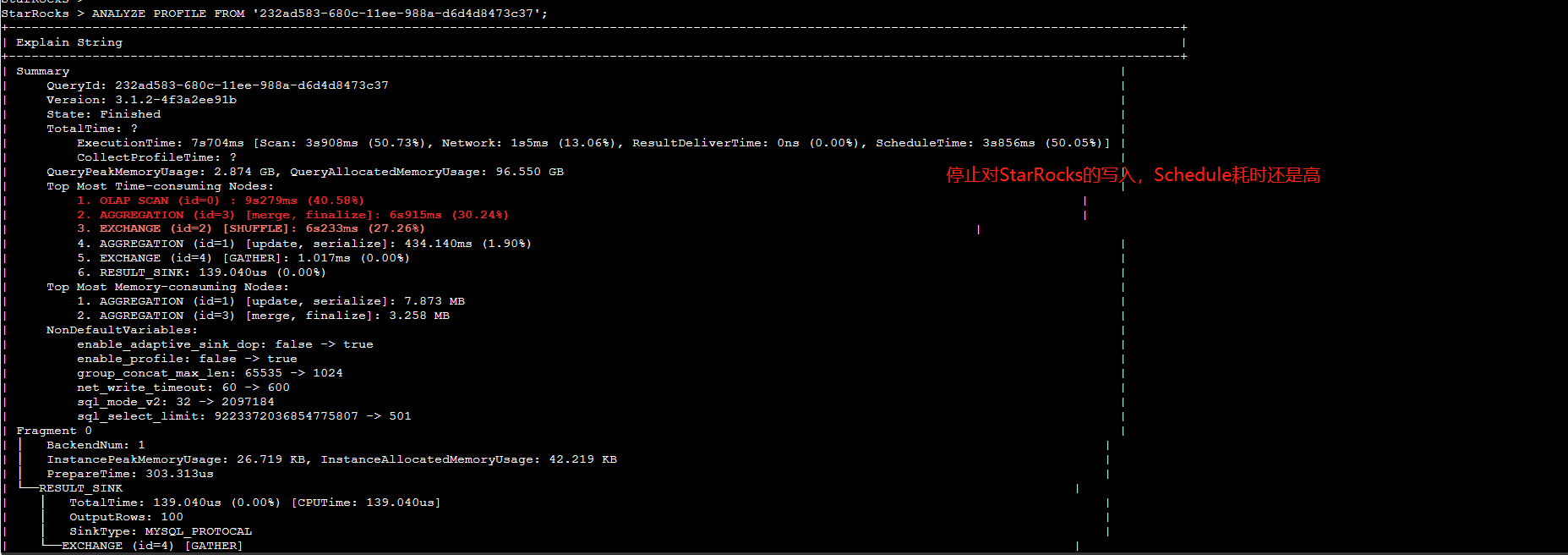
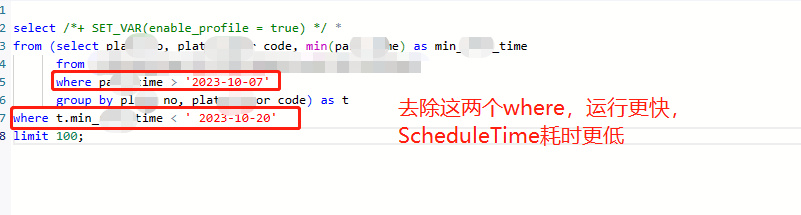
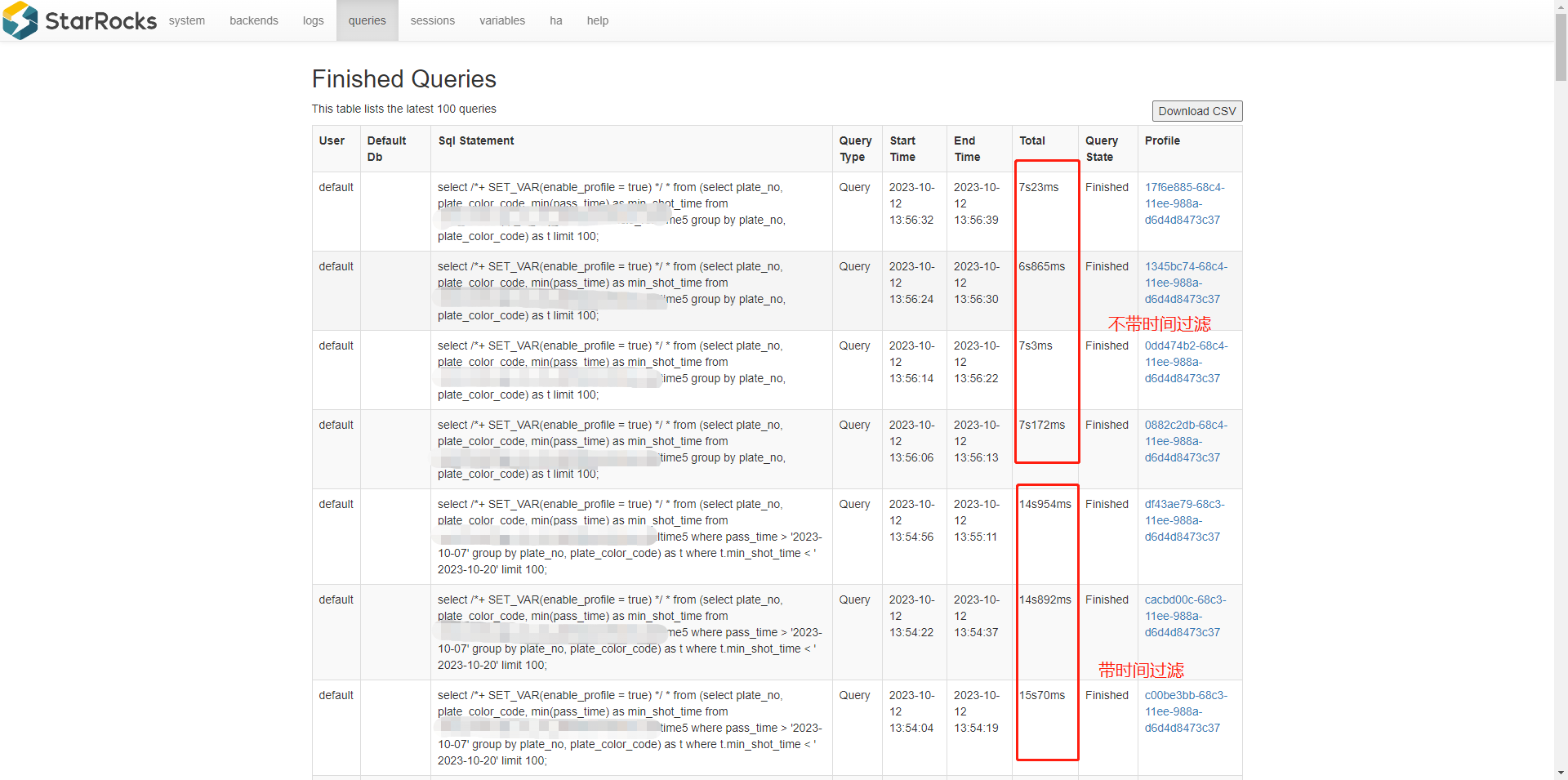
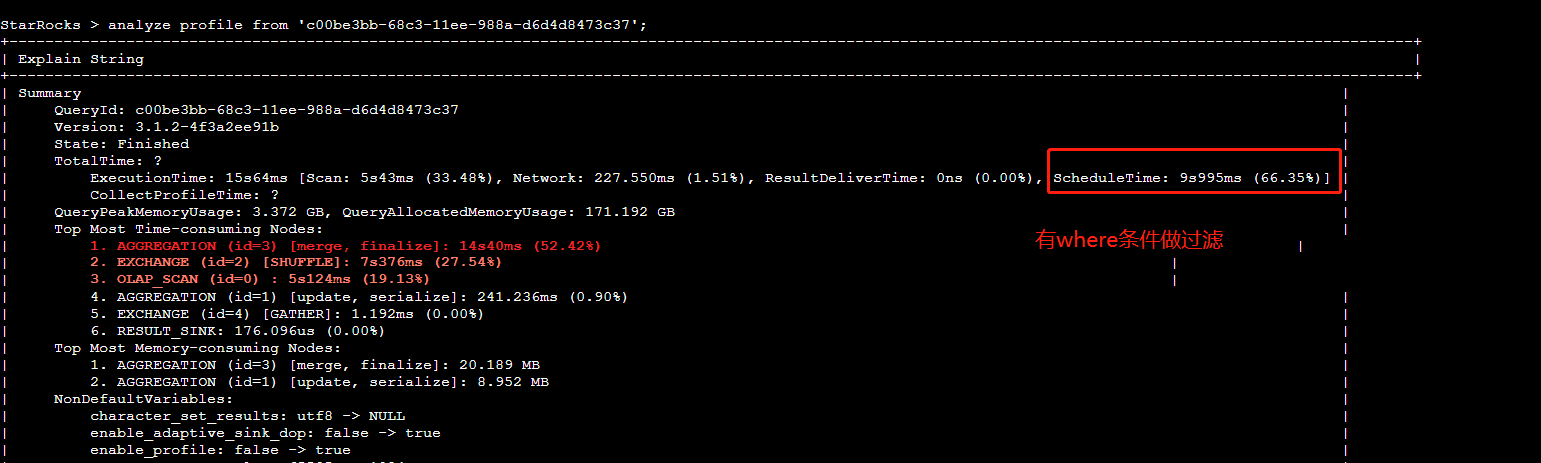
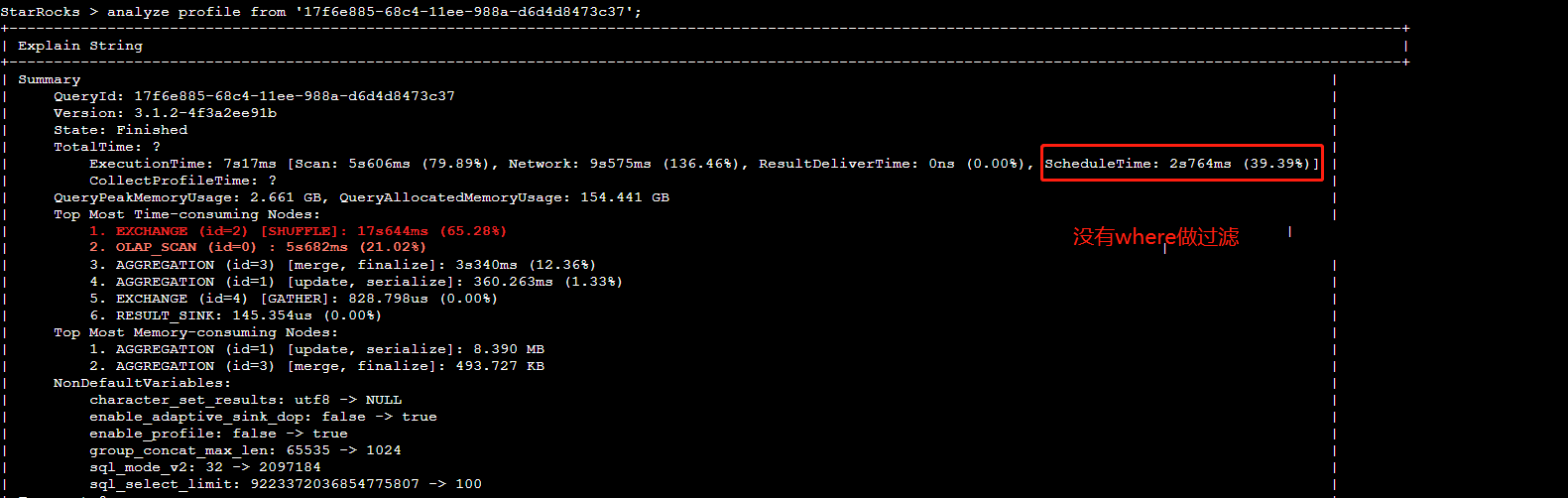
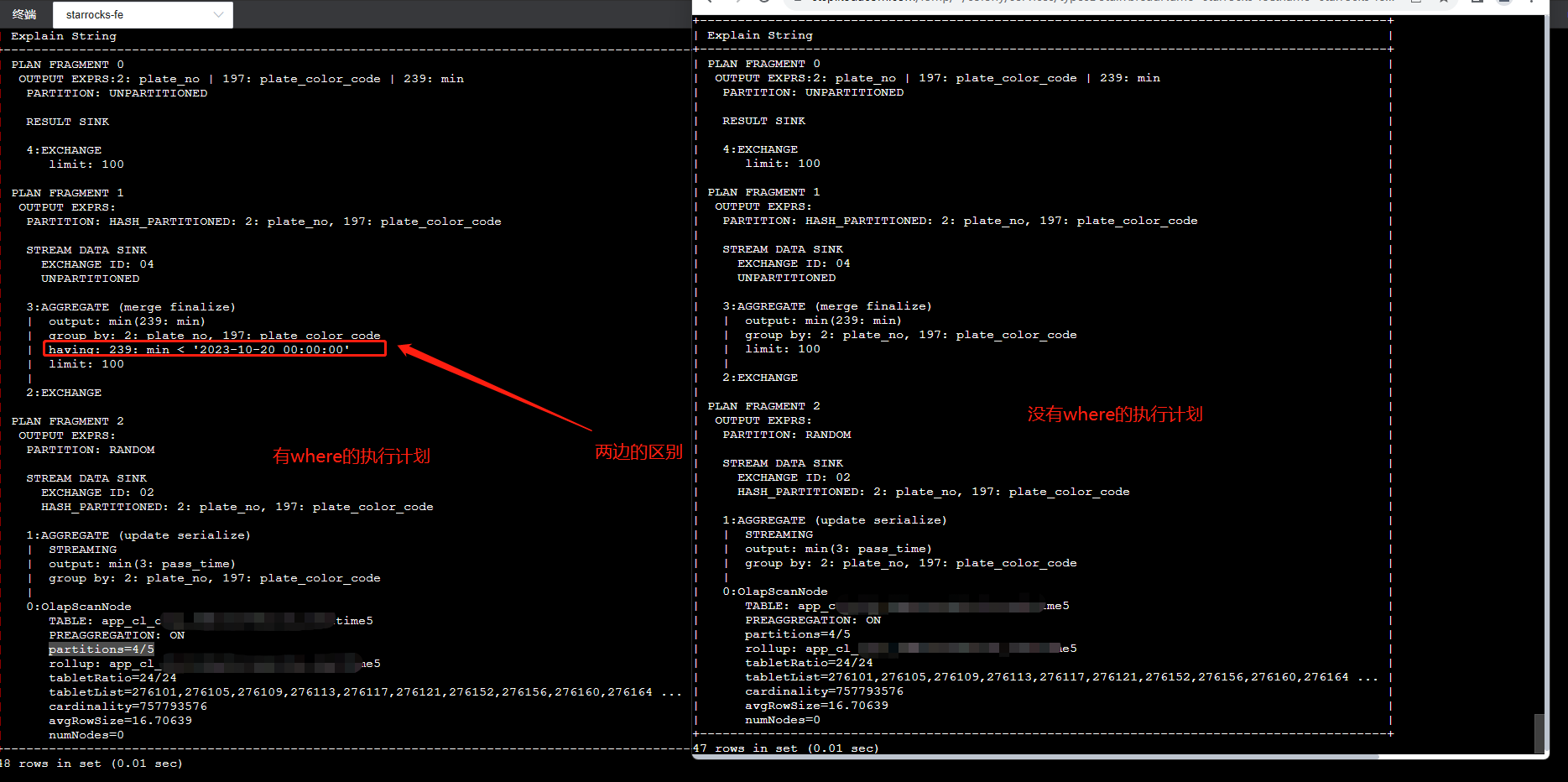
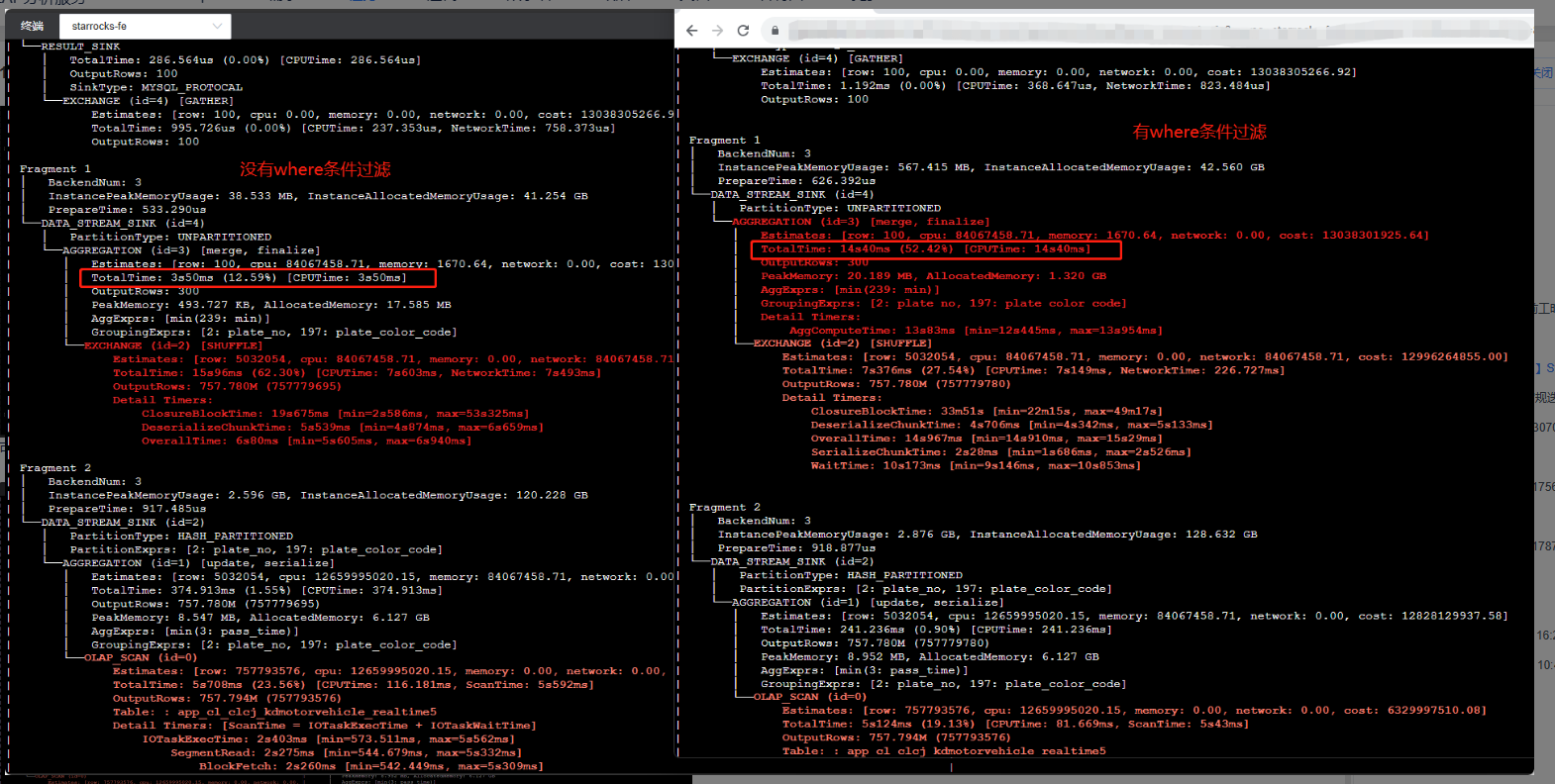
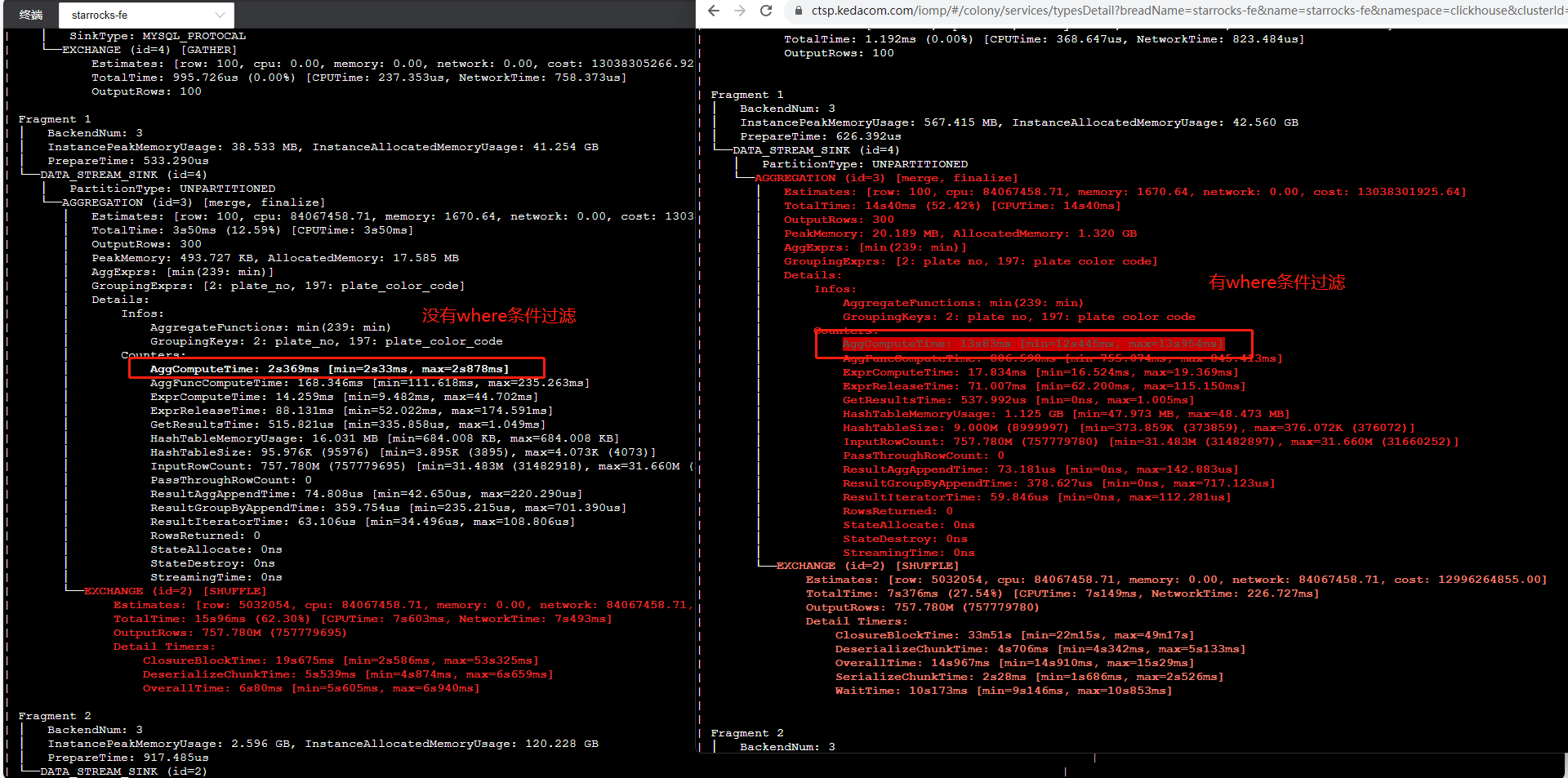
【详述】SQL执行耗时要10秒左右,一共不到5亿数据,使用analyze分析,发现ScheduleTime耗时最高占据90%,多次执行SQL发现,ScheduleTime耗时要占据50%左右,平均耗时要接近4秒
【背景】先往StarRocks集群中写数据,发现执行太慢,然后停止了写,再执行SQL,发现执行还是较慢,且ScheduleTime耗时占比高
【业务影响】
【StarRocks版本】3.1.2-4f3a2ee91b
【集群规模】1fe(1 follower)+3be(fe与be混部)
【机器信息】FE配置 2C 4G,BE 配置 16C 64G,SSD盘
【联系方式】hongweijin1993@gmail.com
【附件】
-
fe.log/beINFO/相应截图
-
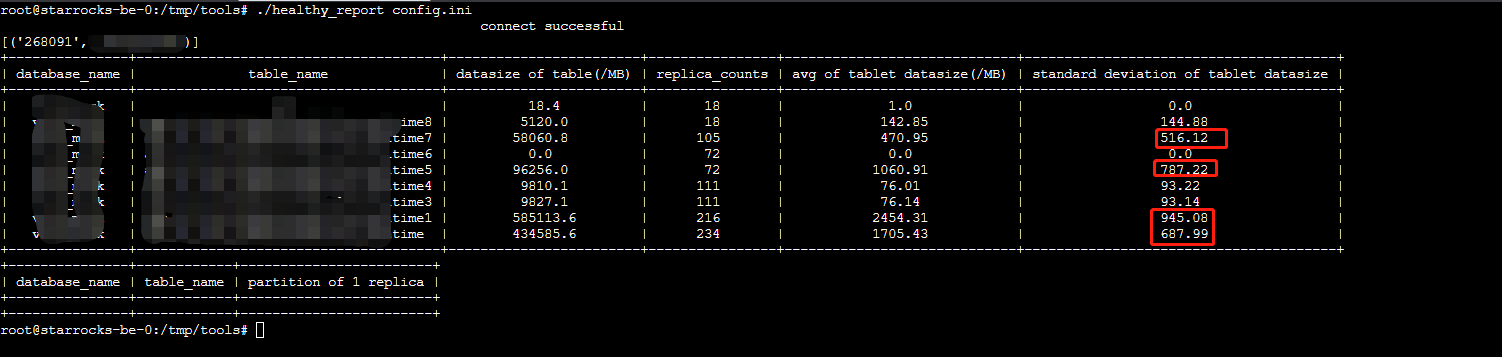
内存及cpu使用情况截图
-
磁盘io情况
-
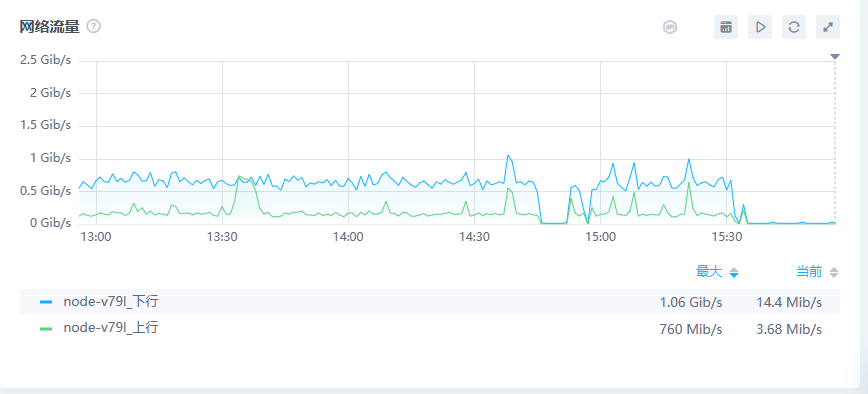
网络情况
-
慢查询:
- Profile信息
profile.yml (81.7 KB) - Analyze信息
analyze.txt (12.6 KB) - fe配置
fe.conf (13.4 KB) - fe系统变量
fe-variable.conf (7.1 KB) - be配置
be.conf (14.1 KB)
- Profile信息