sr集群是 3台fe 和 5台be 混部的,就是又3台的服务器既有fe也有be
服务器配置都一样如下
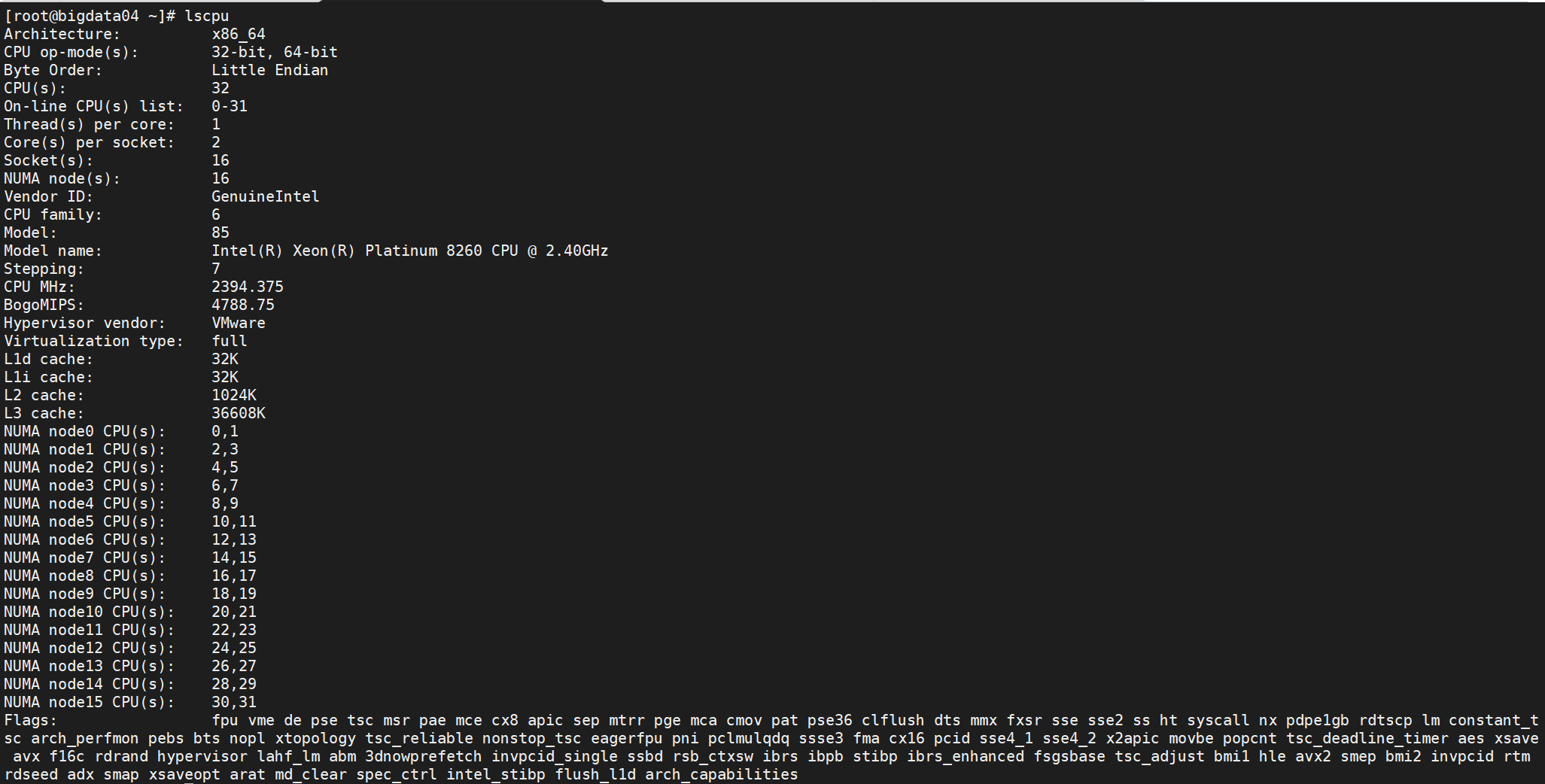

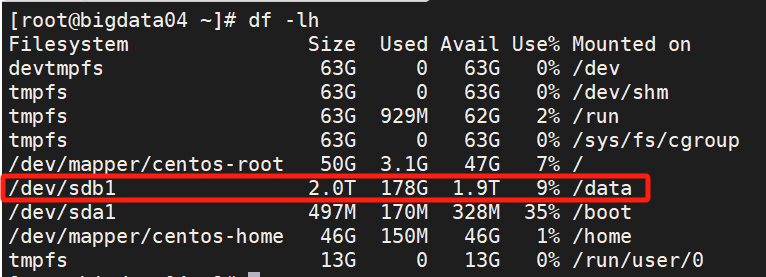
sr 完全安装再数据盘 /data下
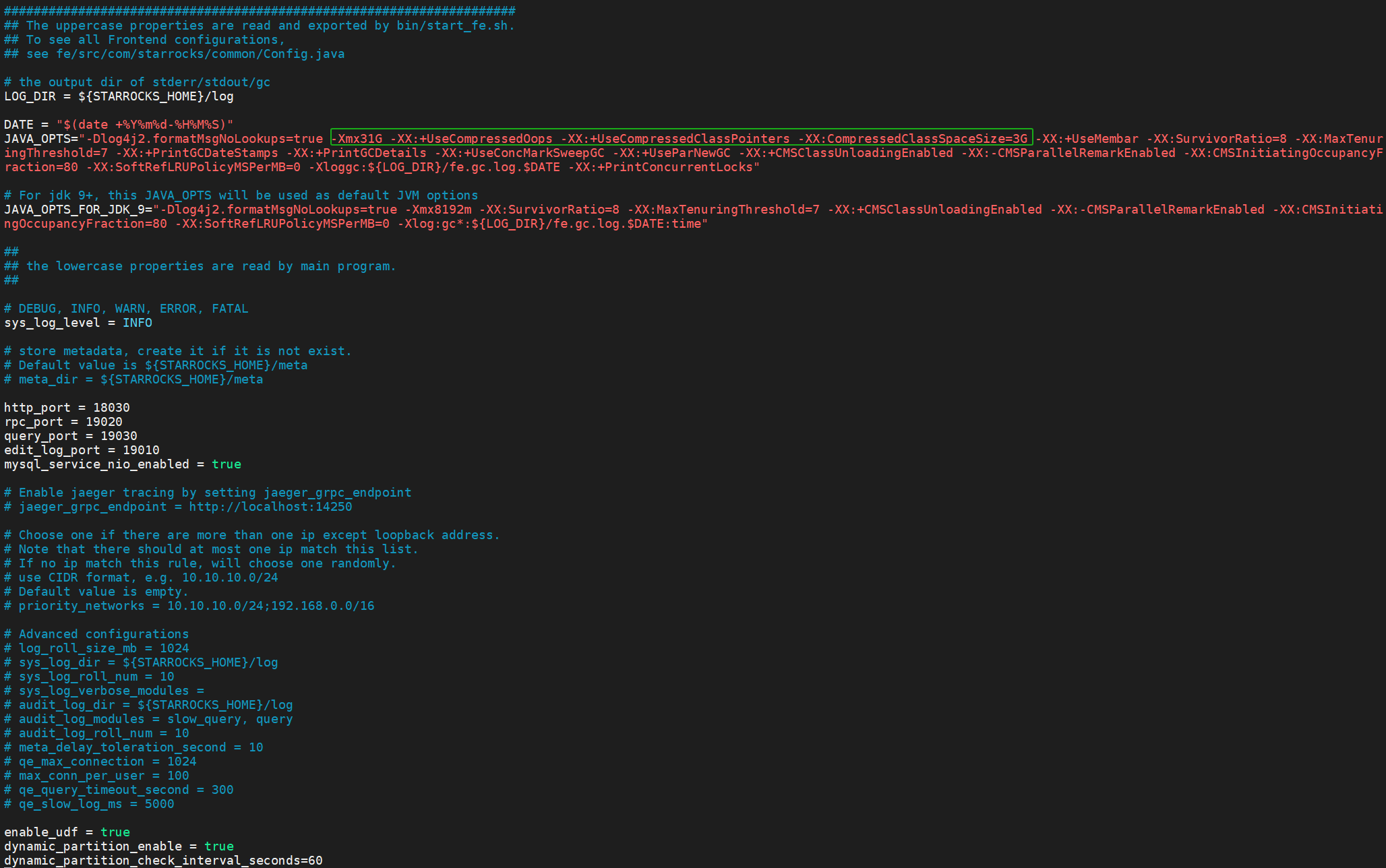
fe最新的配置
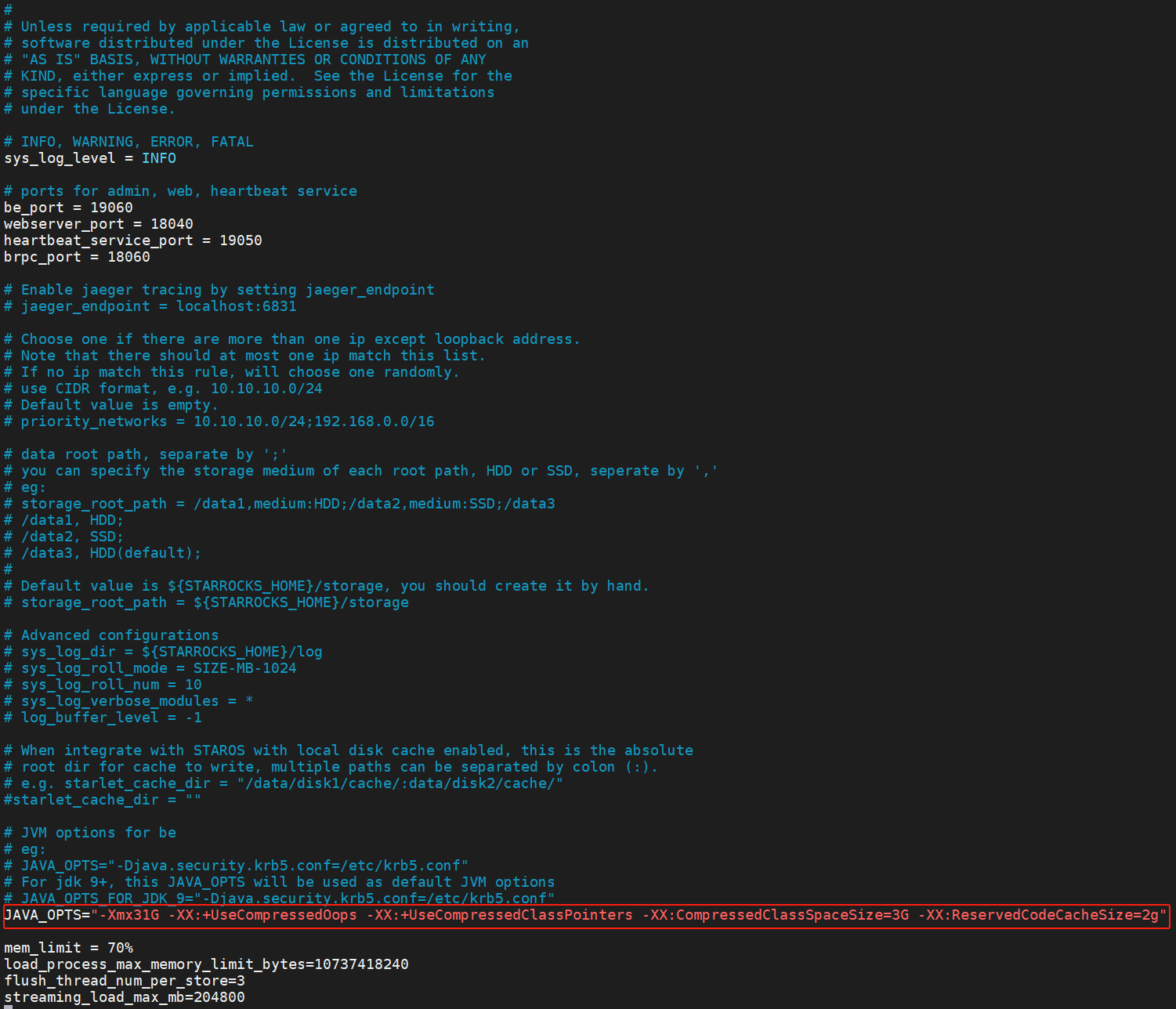
be最新的配置
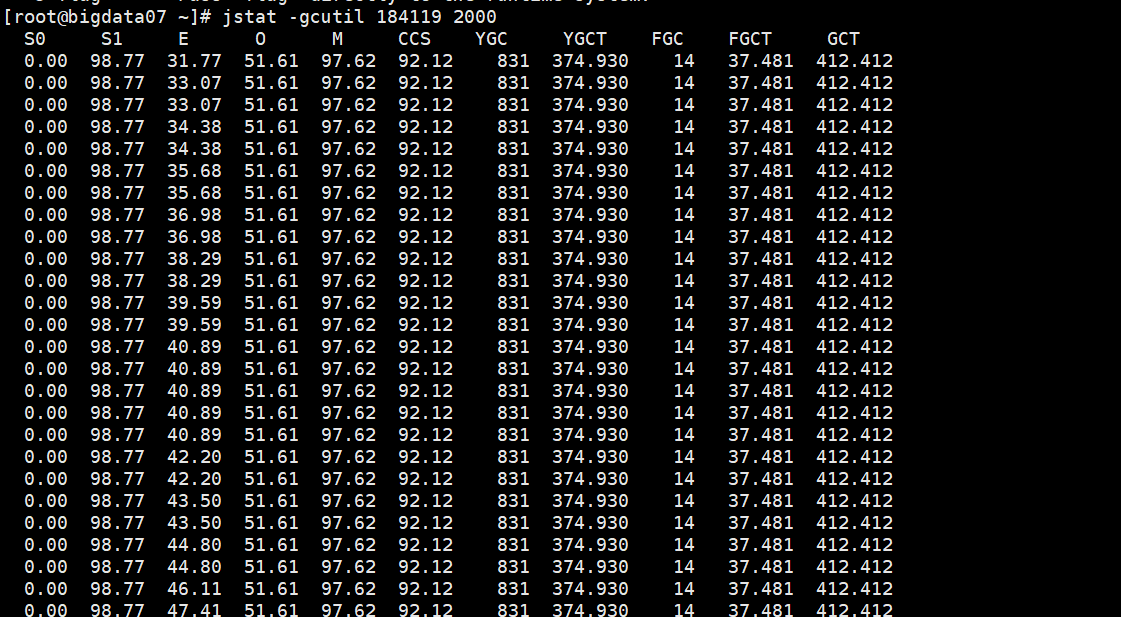
下面介绍怎么一点点修改集群jvm配置的
同事编写的java udf函数 功能是某个市的车辆经纬度数据,匹配行政区域的操作
数据来源表的ddl大致如下
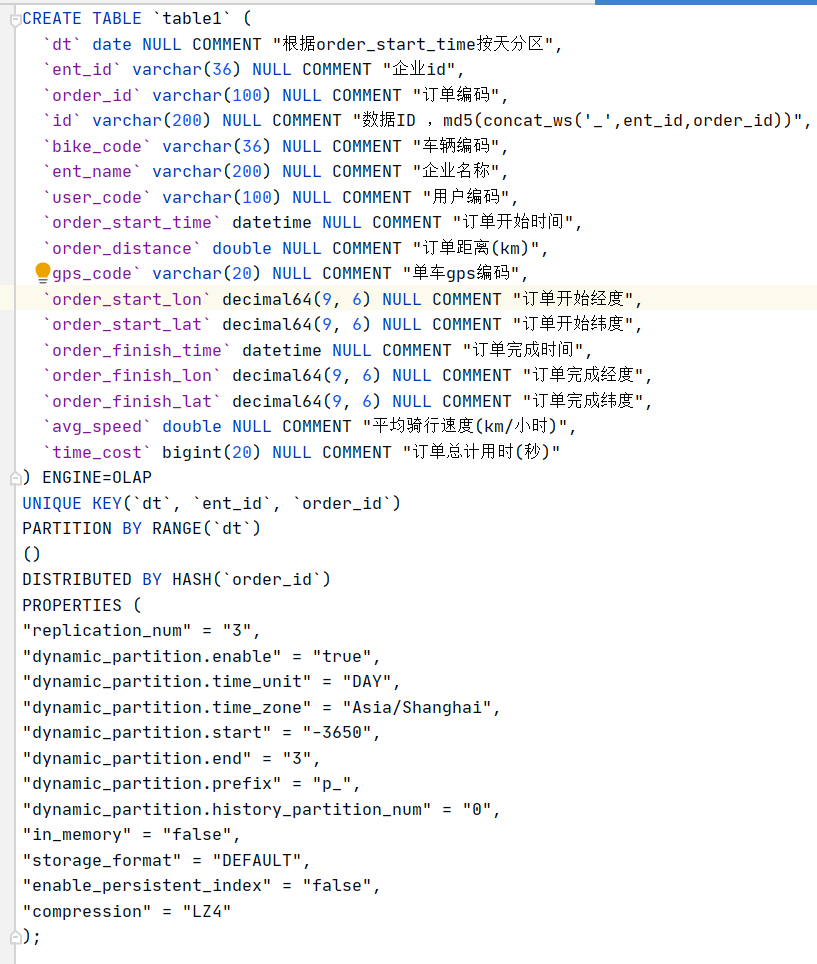
每天的数据量大概如下
我们只对天的数据进行统计 有每5分钟统计从0点到当前全天的 和t+1 统计前一天的数据
主要就是利用经纬度数据传入此udf函数中反馈匹配的居于结果
最开始的时候配置fe 的jvm参数 从原始的 -Xmx8192m 变成了16384M
be没有添加任务jvm参数
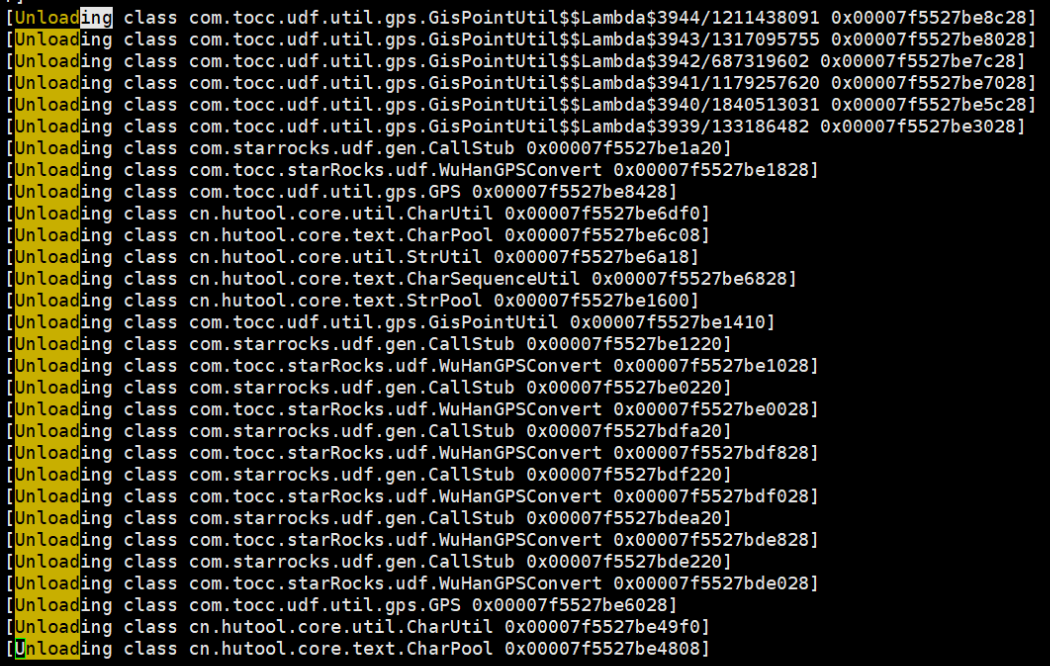
当发现执行了一些此udf函数的sql的时候 会报错
exception happened when get class: java.lang.OutOfMemoryError: Compressed class space[] backend:172.28.203.232
和
rpc failed, host: 172.28.203.232
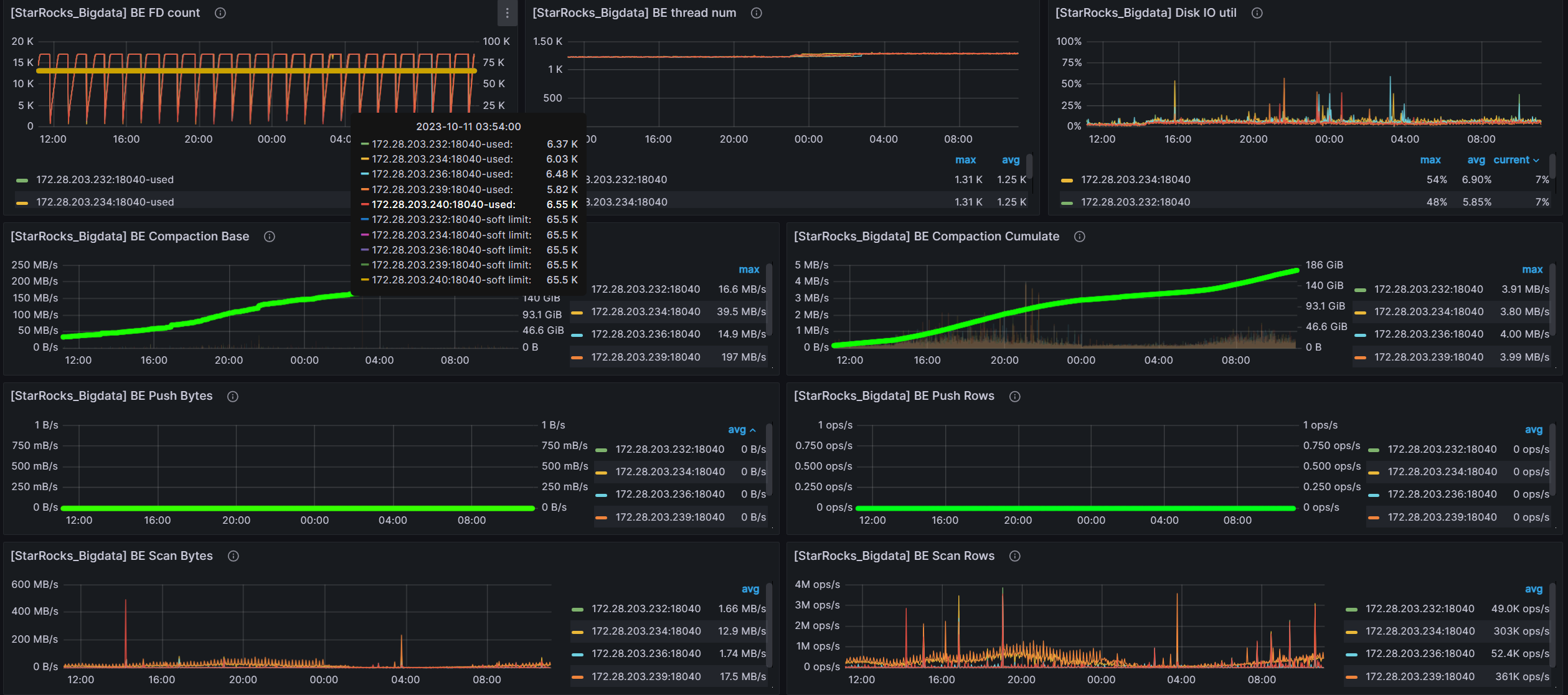
fe 和 be 会挂掉一两个
经过参考文章
(https://www.cnblogs.com/happyflyingpig/p/8886952.html)
(https://www.zhihu.com/question/268392125)
(https://www.jianshu.com/p/3e3903b5ca29)
当jvm的堆内存设置为 32G的时候,虚拟机就不用这个东西了Compressed class space
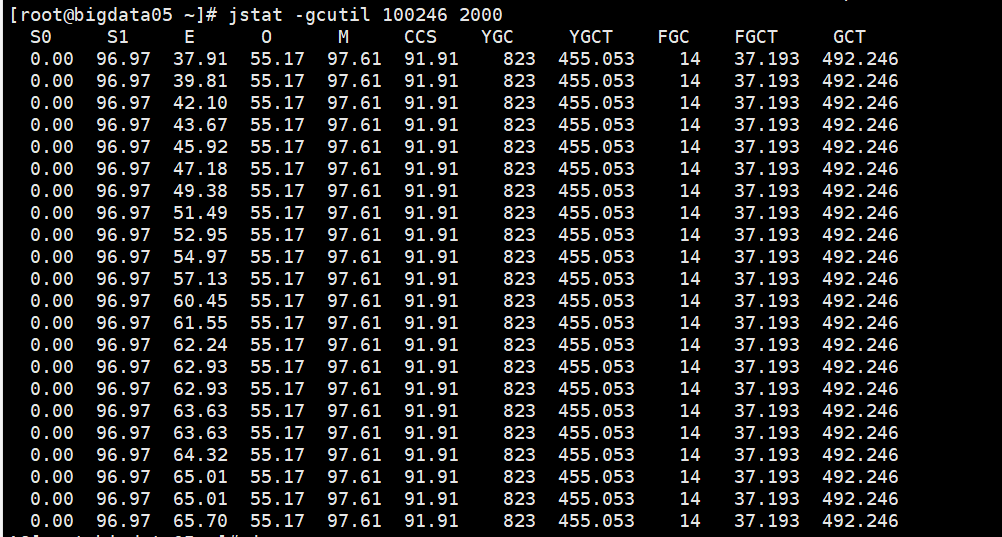
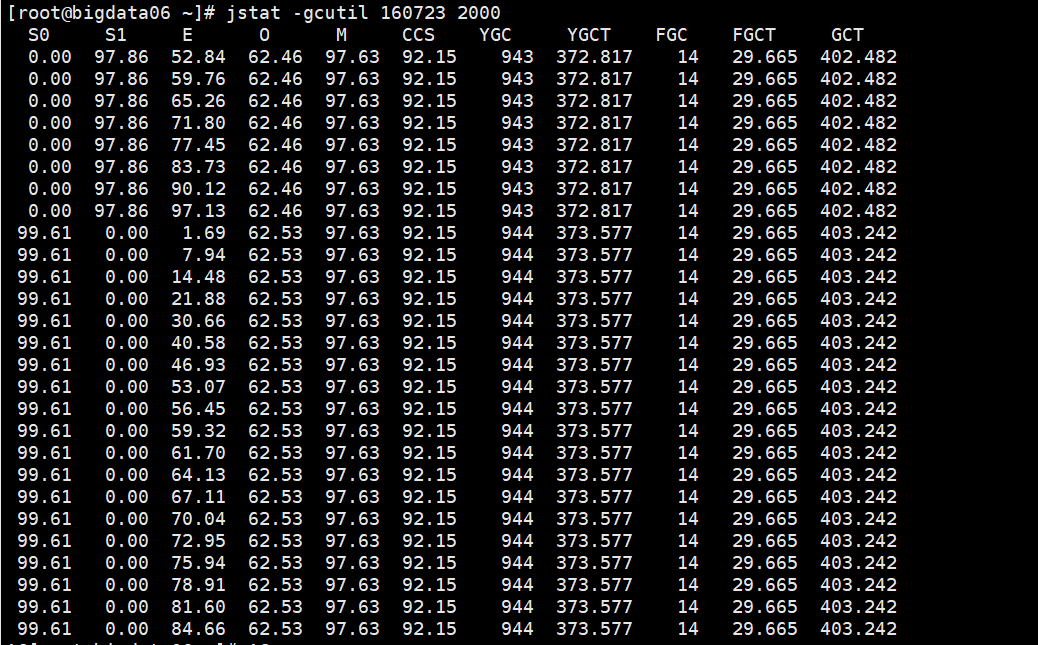
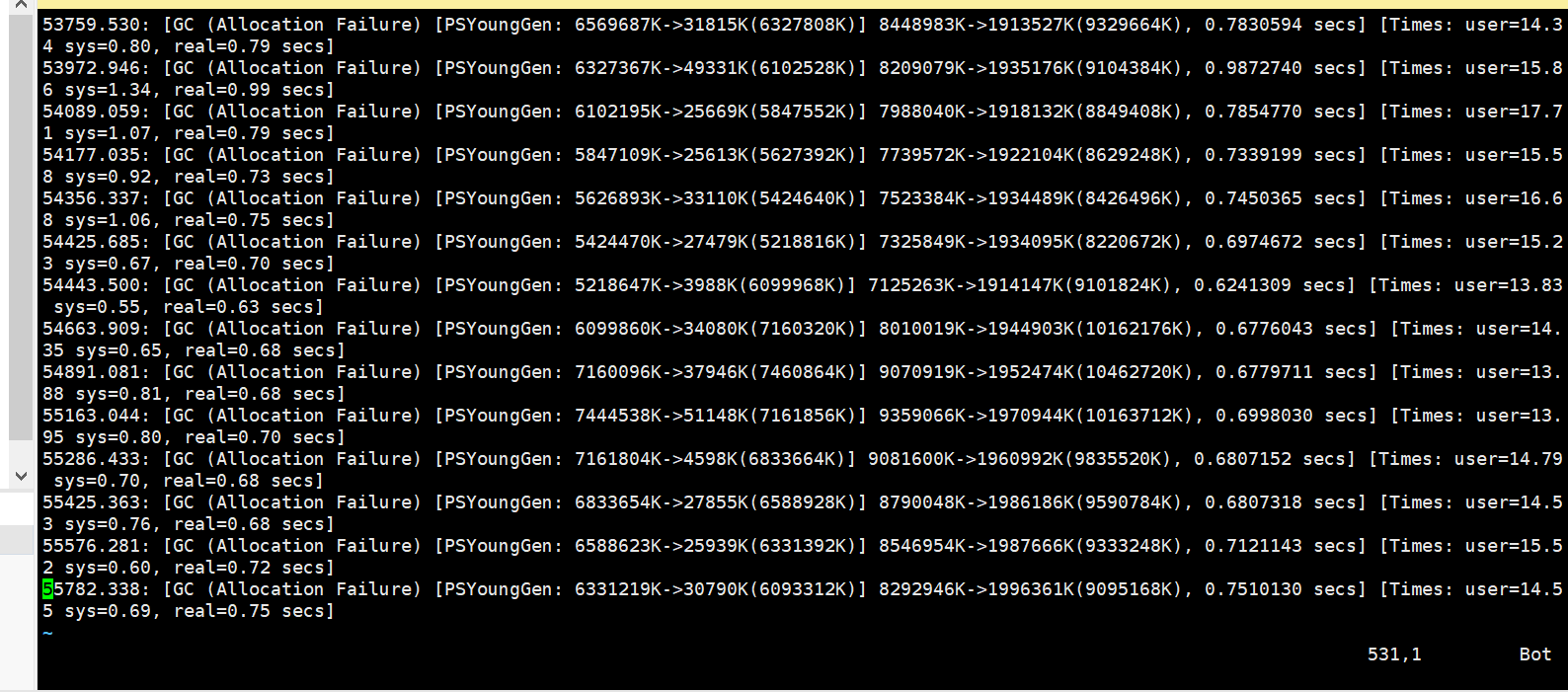
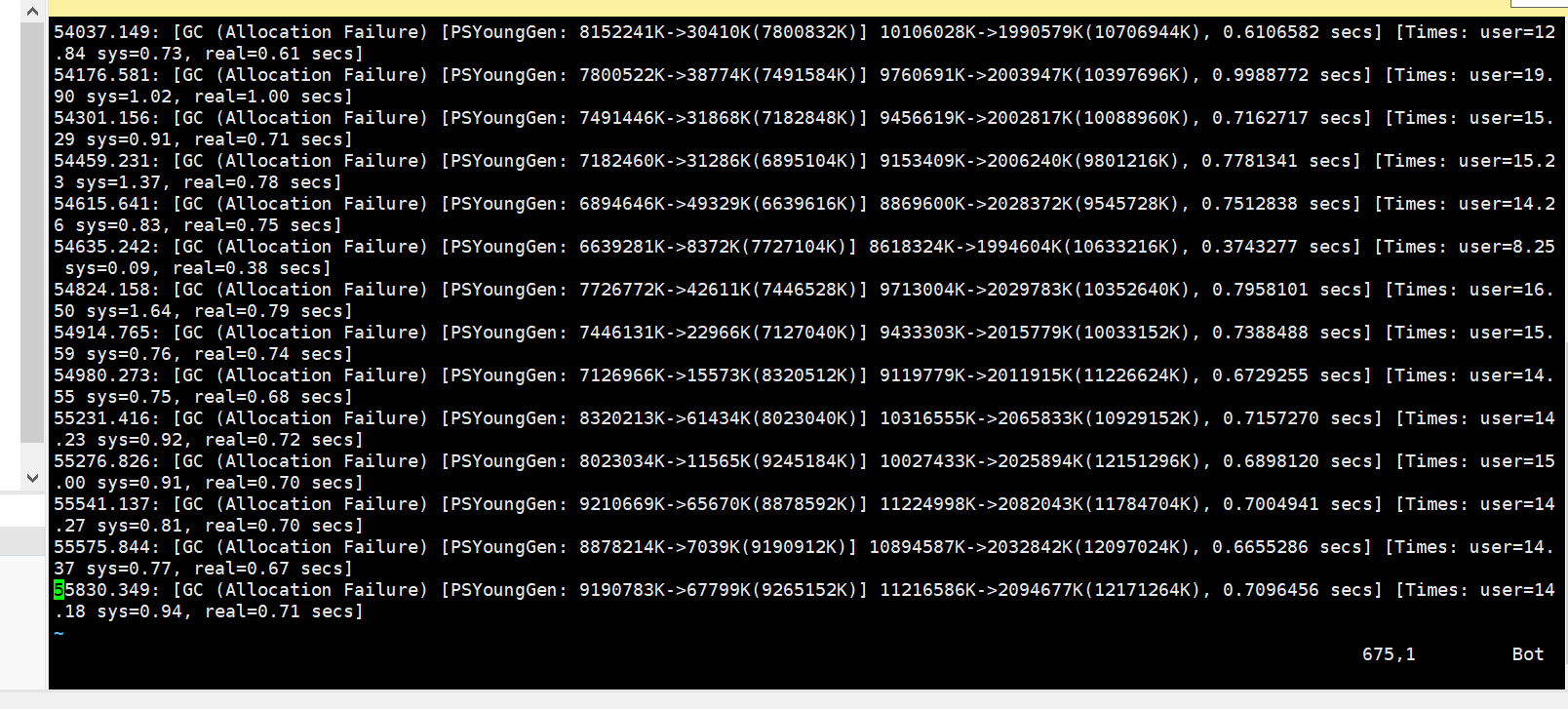
把 be 和 fe的jvm都调整为-Xmx32G 发现刚开始很不错,但是运行一段时间发现,内存累计增大,cpu和内存不释放导致 be和fe挂掉
继续调整参数发现
UseCompressedClassPointers
压缩类指针。对象的类指针(_klass)被压缩至32bit,使用类指针压缩空间的基地址
64bit服务器上设置-Xmx32g时,-XX:+UseCompressedOops和-XX:+UseCompressedClassPointers会失效,所以最大的堆设置为31g
-XX:CompressedClassSpaceSize 大小的设置也是有限制,因为压缩开关是受制于 32G,所以这个自然也是不能大于 32G,不过 hotspot 规定了这个参数不准大于 3G,所以这个参数其实是不能大于 3G。
因此既能享受64bit带来的好处,又避免了64bit带来的性能损耗
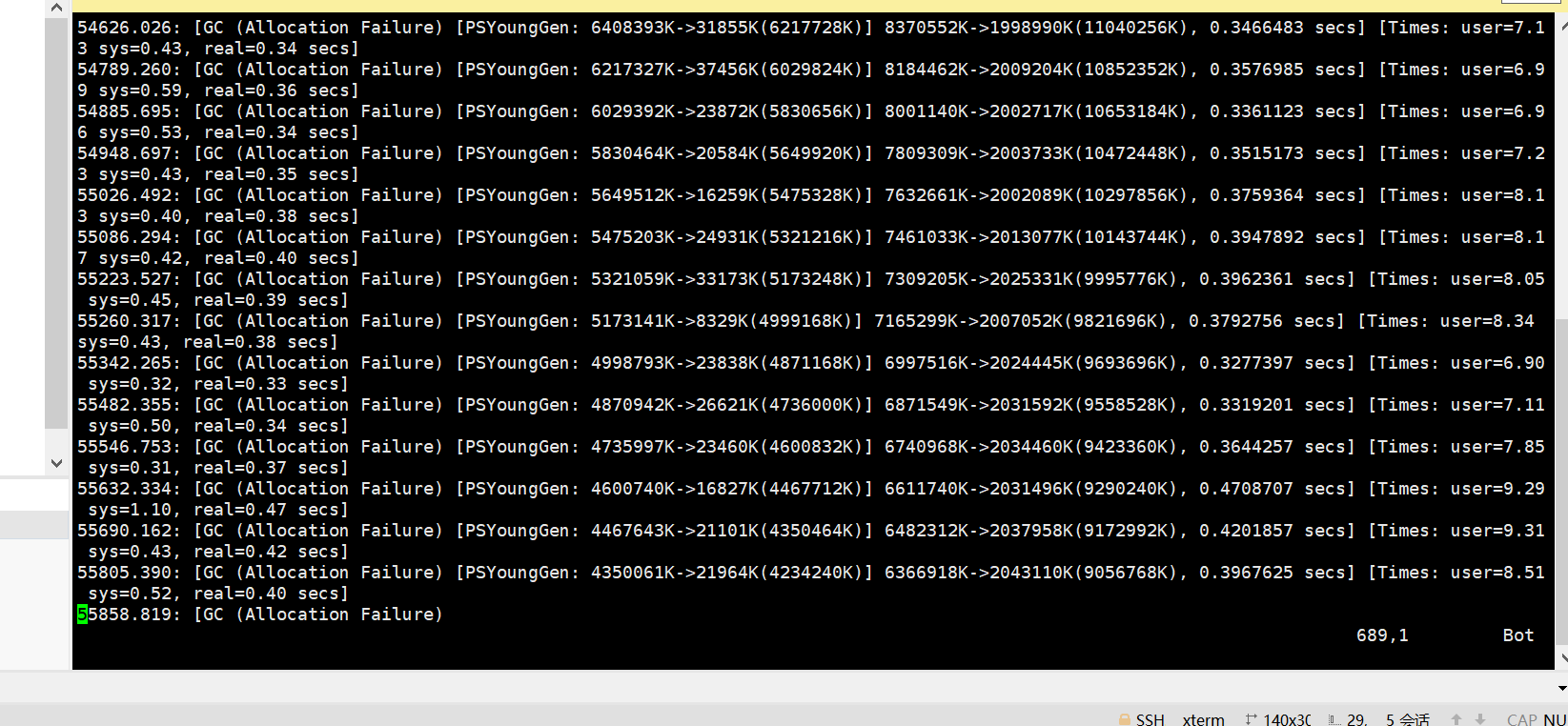
最终把 be 和 fe的jvm都加上
-Xmx31G -XX:+UseCompressedOops -XX:+UseCompressedClassPointers -XX:CompressedClassSpaceSize=3G
发现 集群运行非常良好和正常 cpu和内存 都会得到释放,fe 和 be 再也没有挂掉的现象
但是早上起来发现 执行udf函数的sql 还是会有挂掉的情况
sql执行结果还是rpc failed, host: 172.28.203.232
fe.warn.log的日志
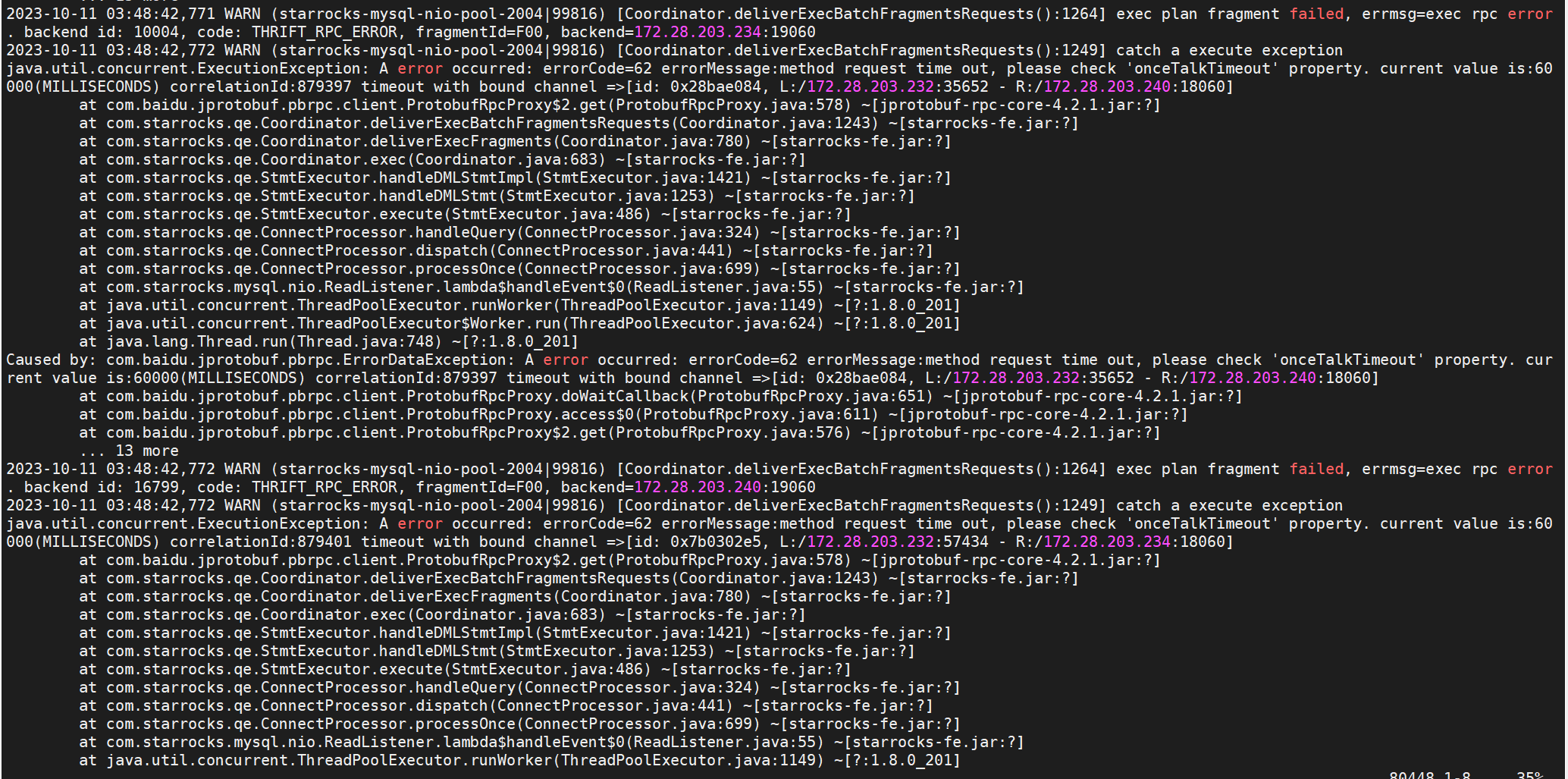
fe.out日志
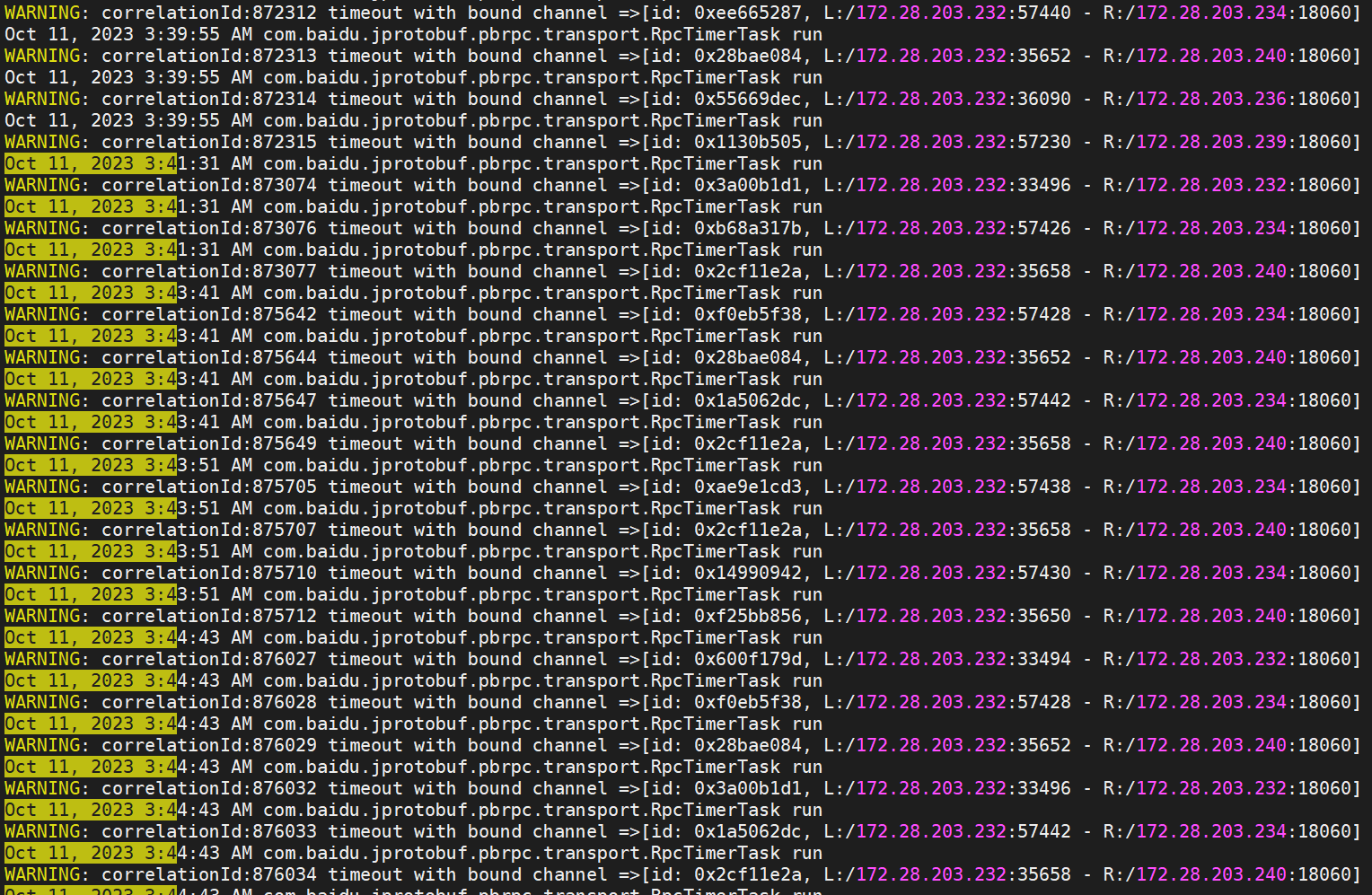
be.WARNING
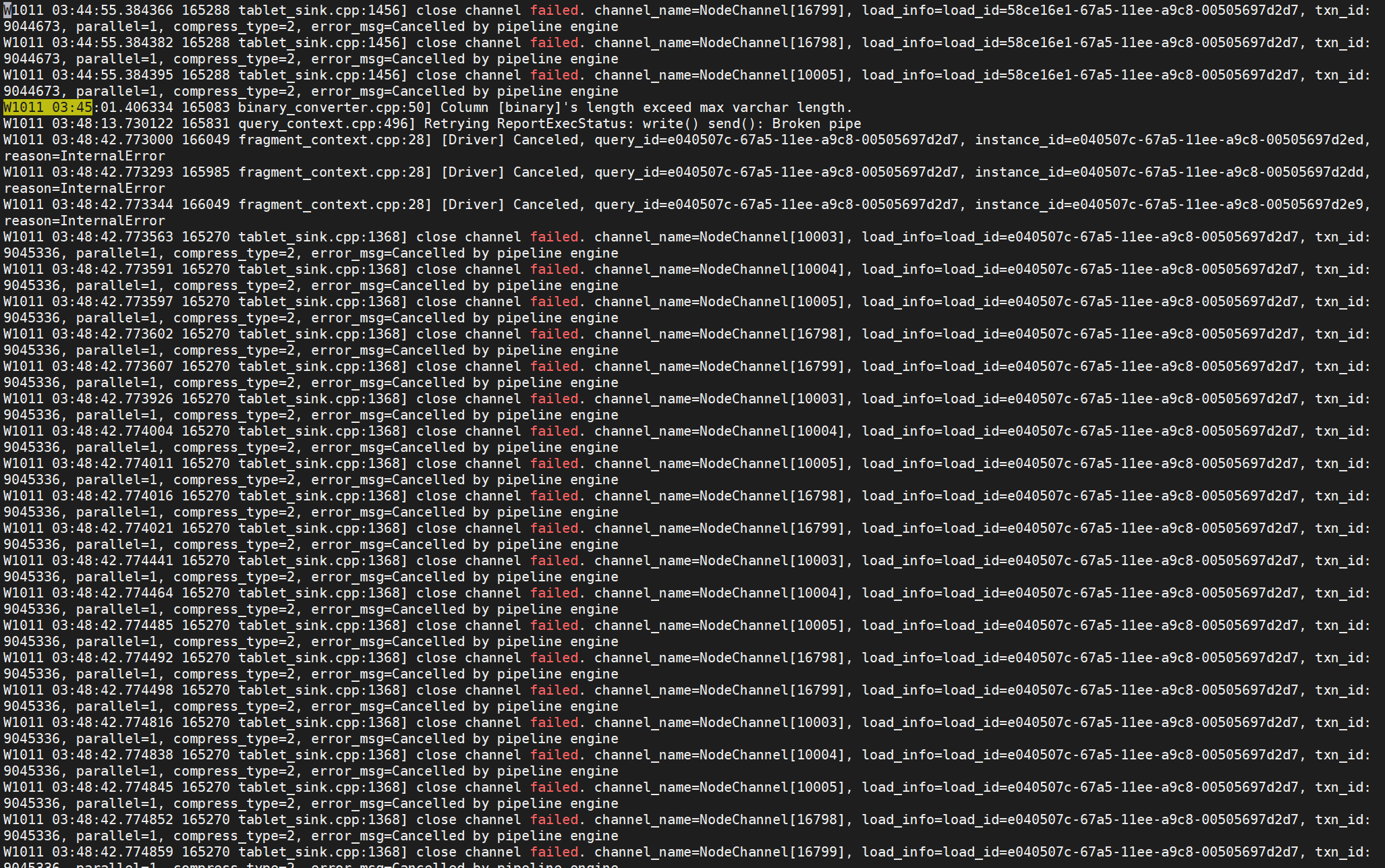
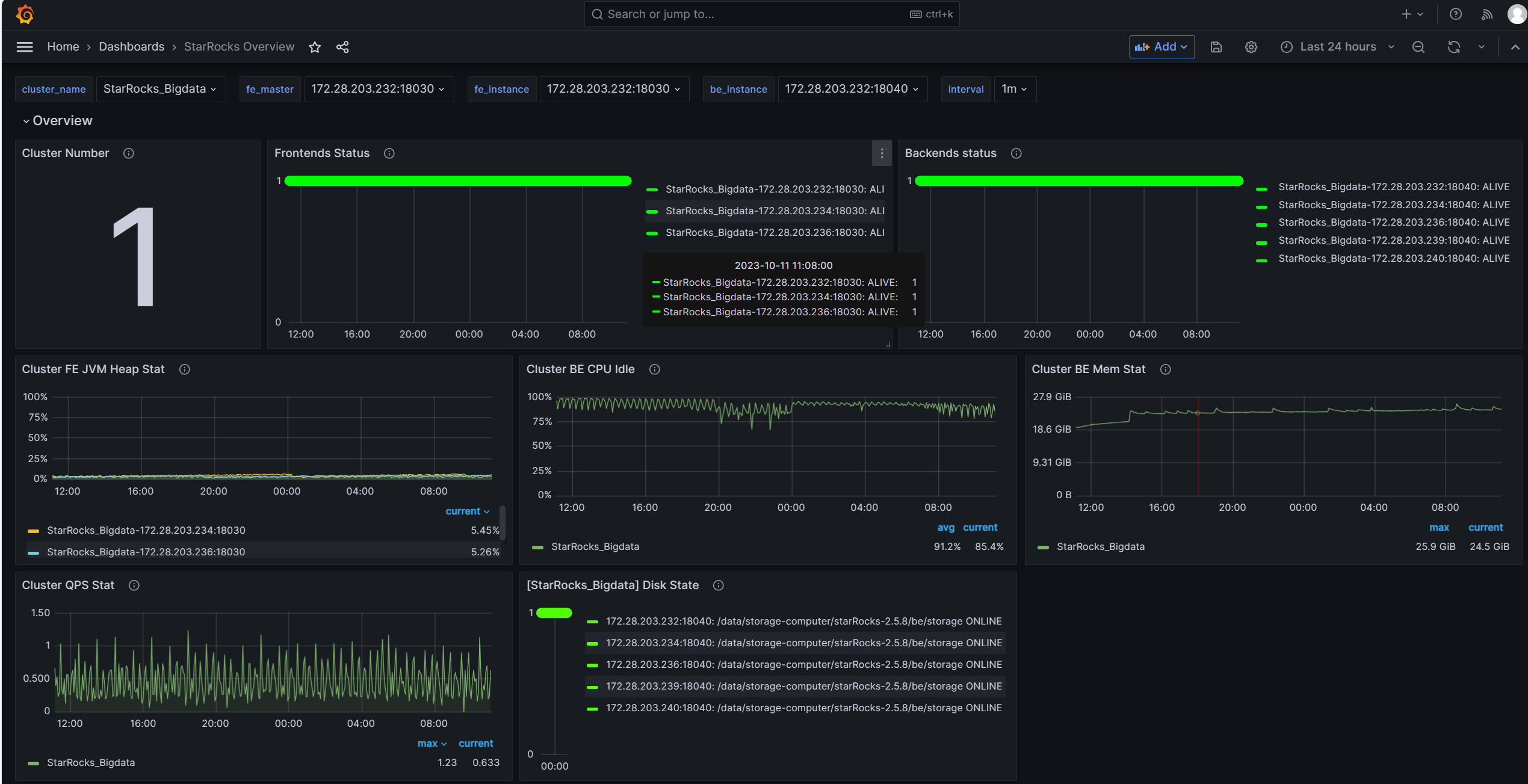
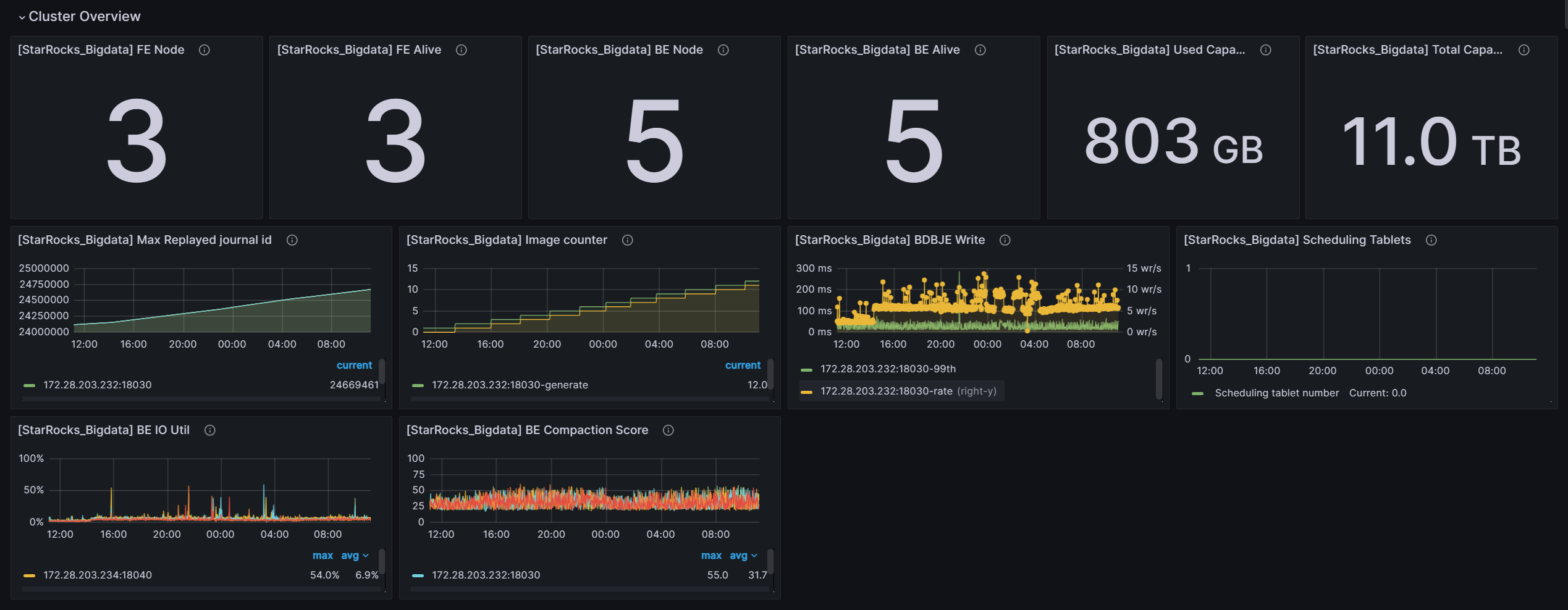
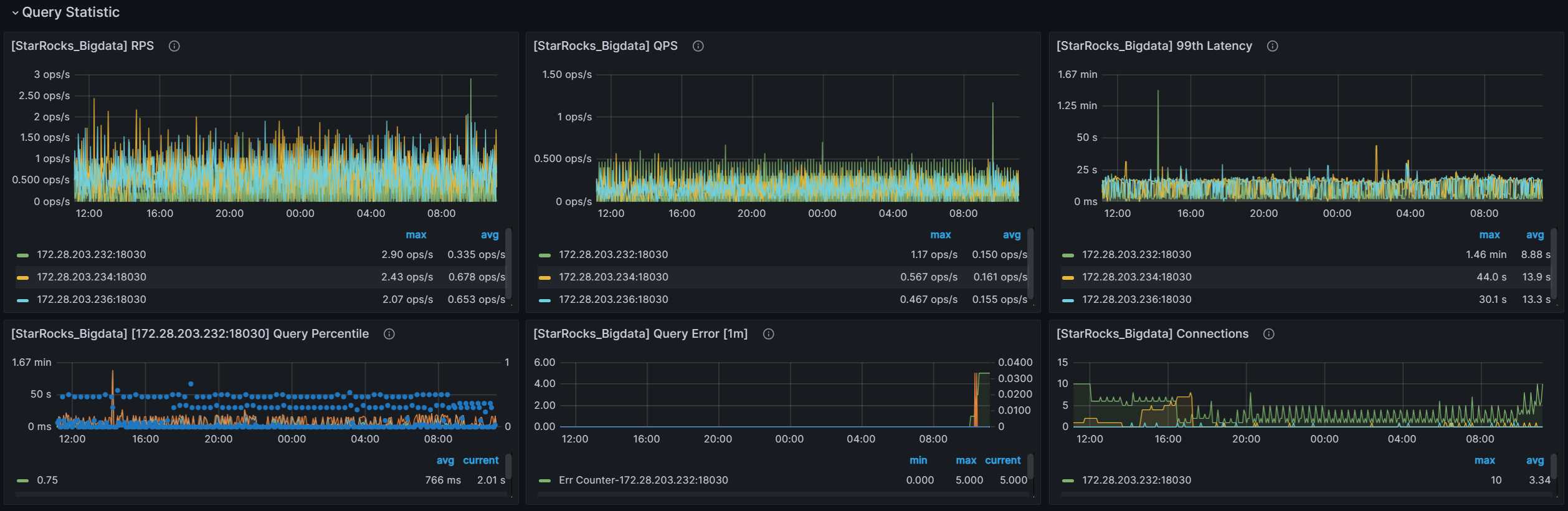
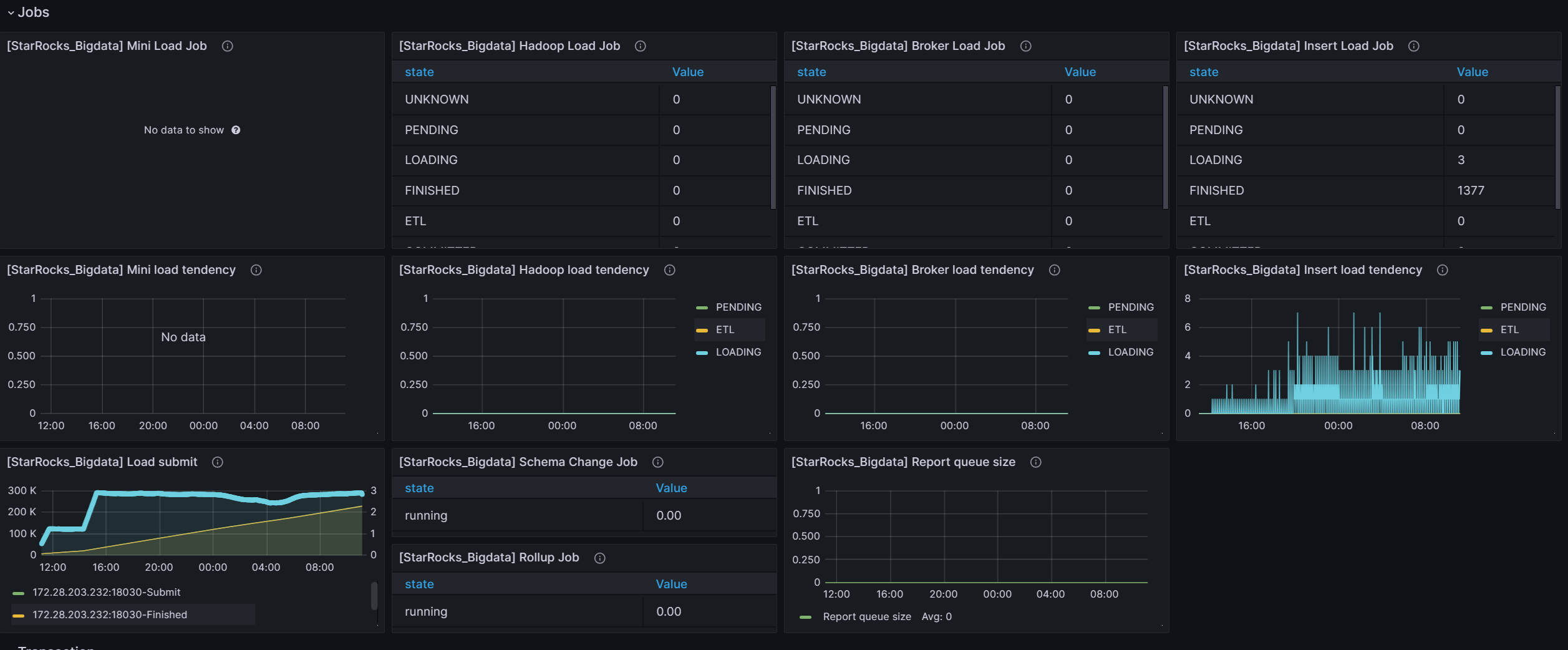
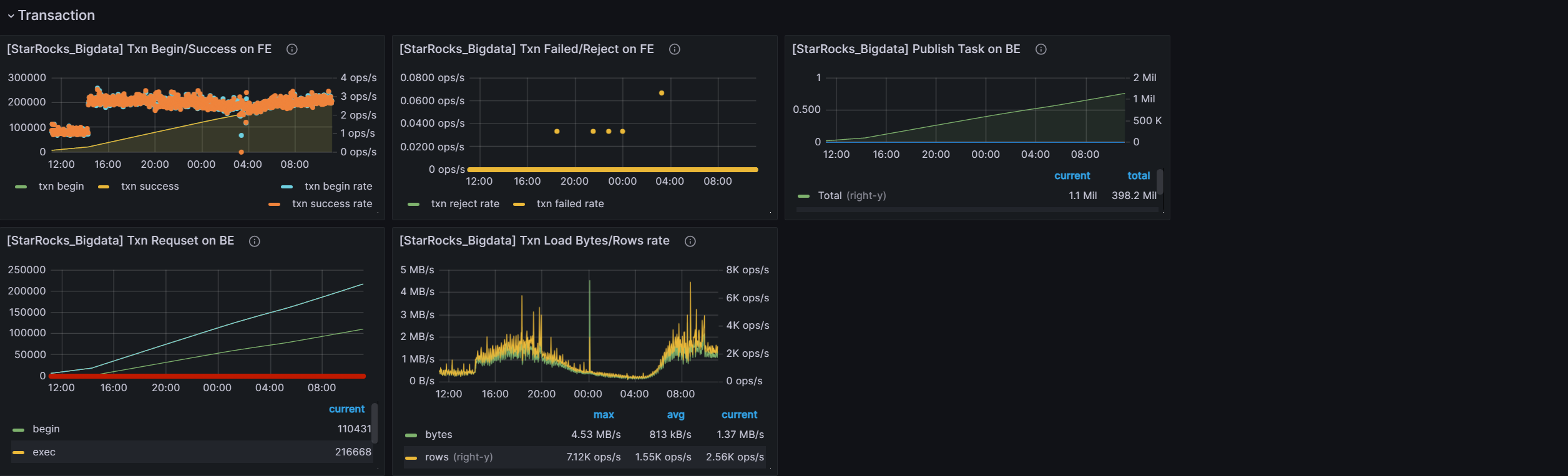
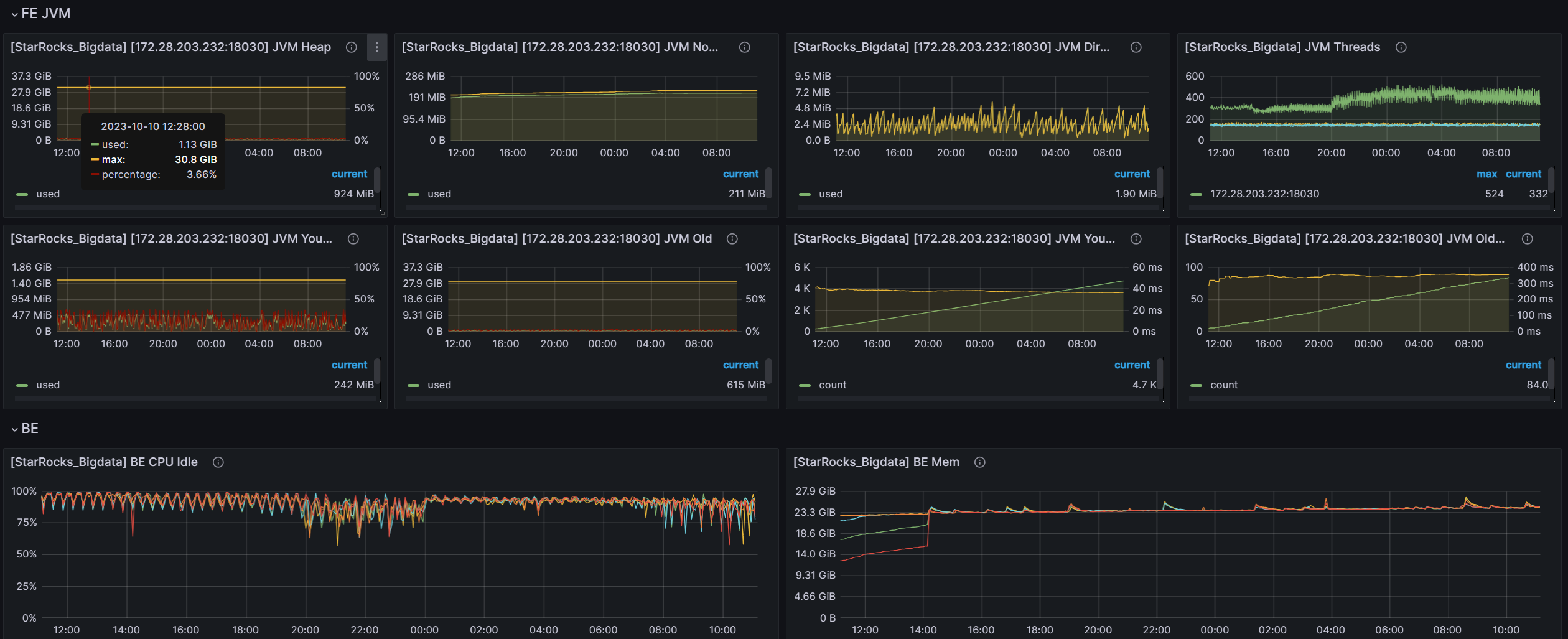
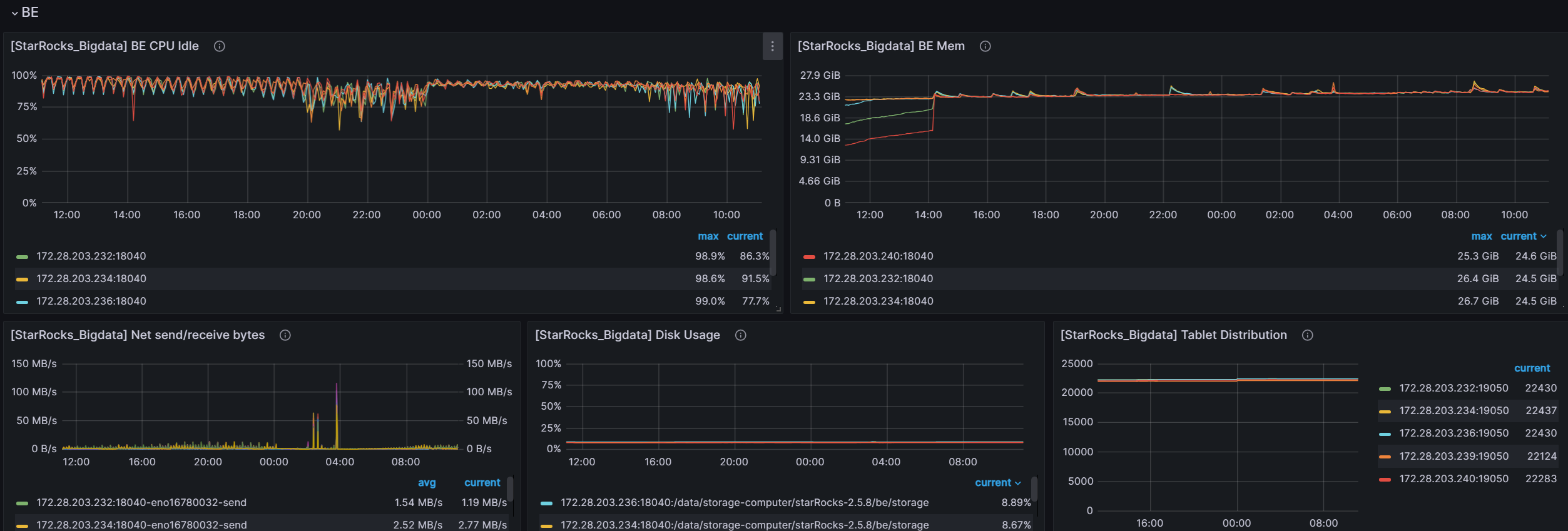
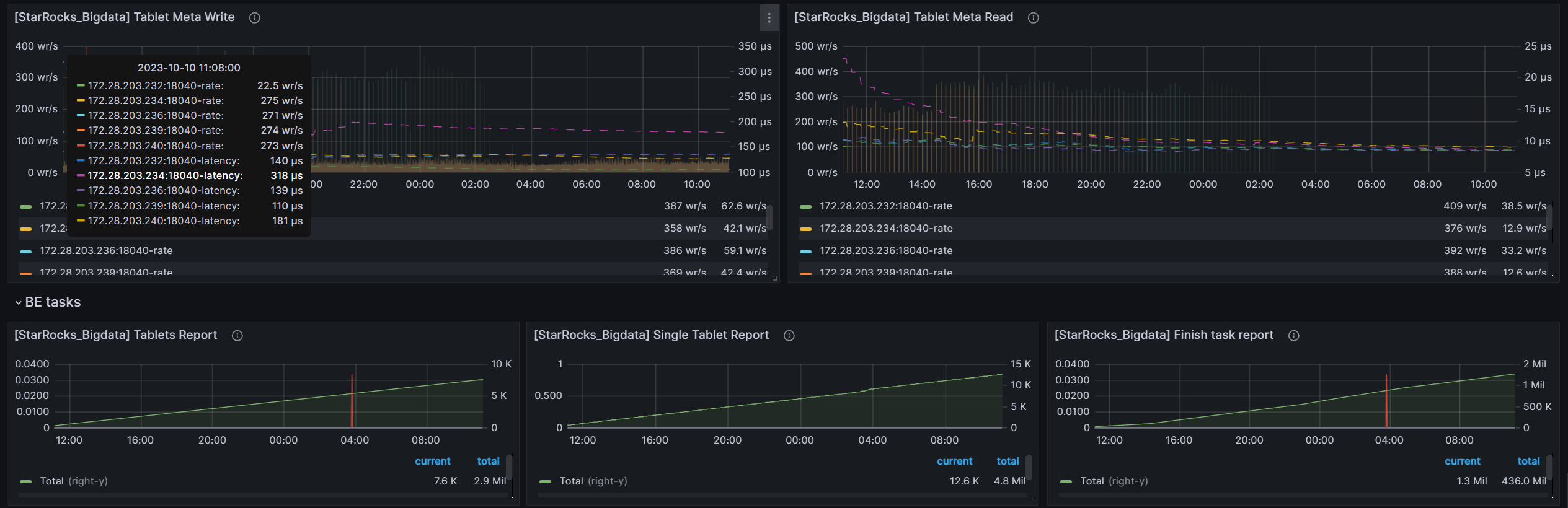
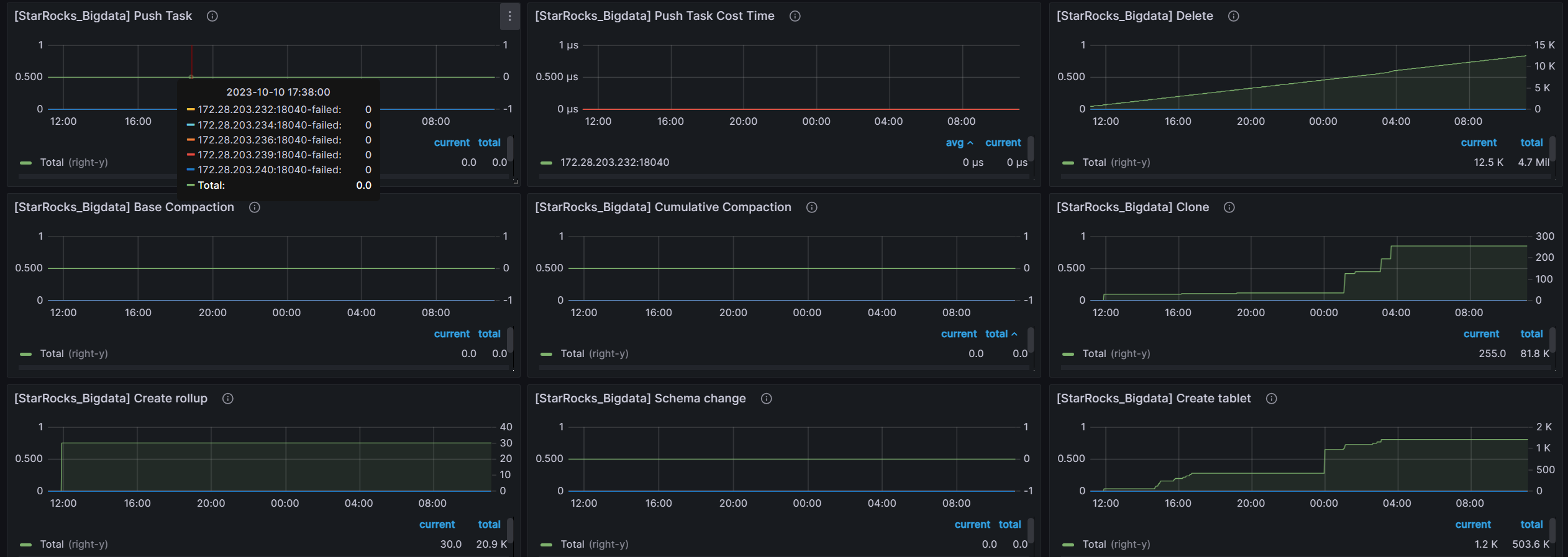
grafana的监控信息 前24个小时的
一下是 top iotop pstack 信息
Desktop.zip (833.8 KB)