sr版本3.1.0
kafka版本3.5.1
debezium oracle connector 2.4
想问下有没有具体的代码实现 starrocks Kafka connector 消费kafka里debezium解析的oracle增量数据?
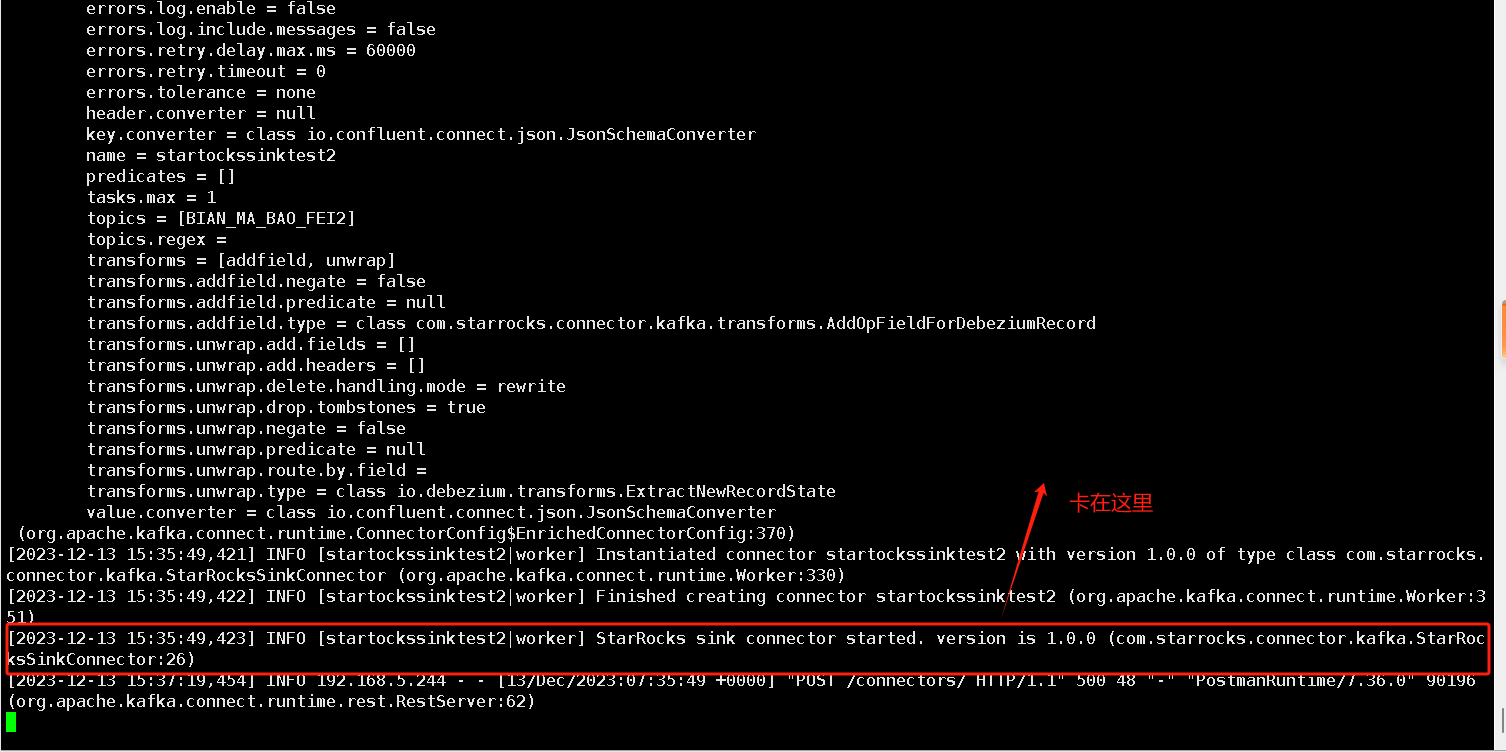
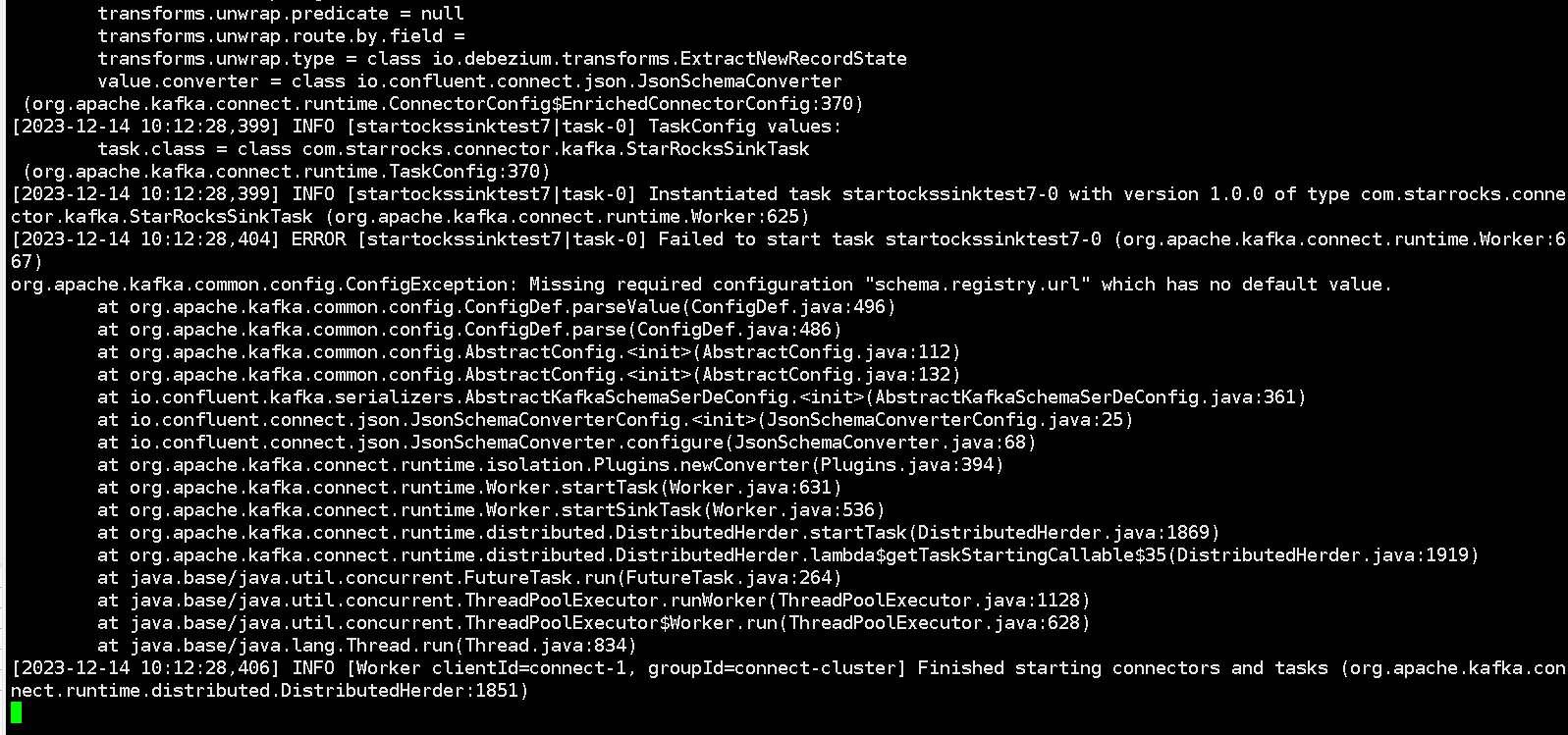
我根据官网的步骤尝试了下,报错:
{"error_code":400,"message":"Connector configuration is invalid and contains the following 2 error(s):\nInvalid value io.confluent.connect.json.JsonSchemaConverter for configuration key.converter: Class io.confluent.connect.json.JsonSchemaConverter could not be found.\nInvalid value io.confluent.connect.json.JsonSchemaConverter for configuration value.converter: Class io.confluent.connect.json.JsonSchemaConverter could not be found.\nYou can also find the above list of errors at the endpoint `/connector-plugins/{connectorType}/config/validate`"}
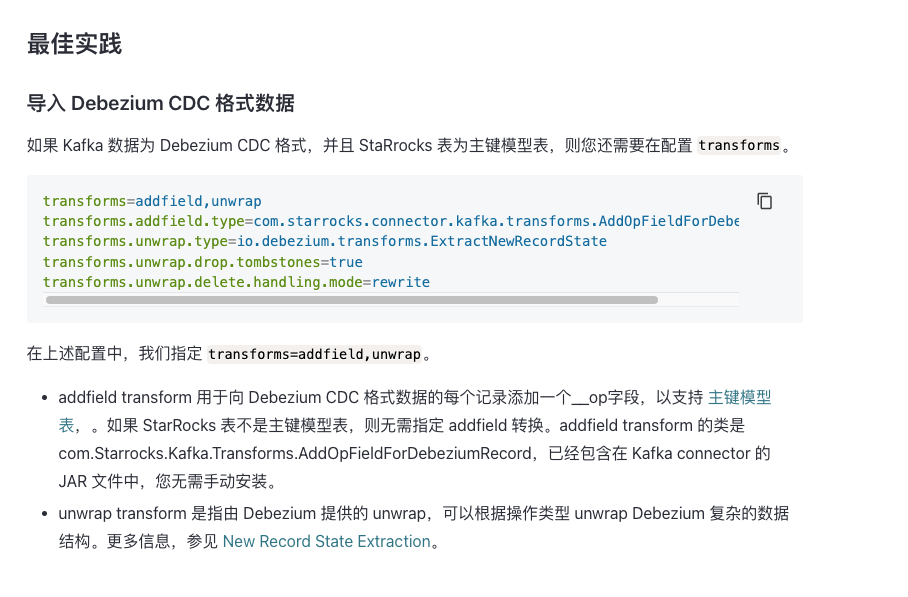
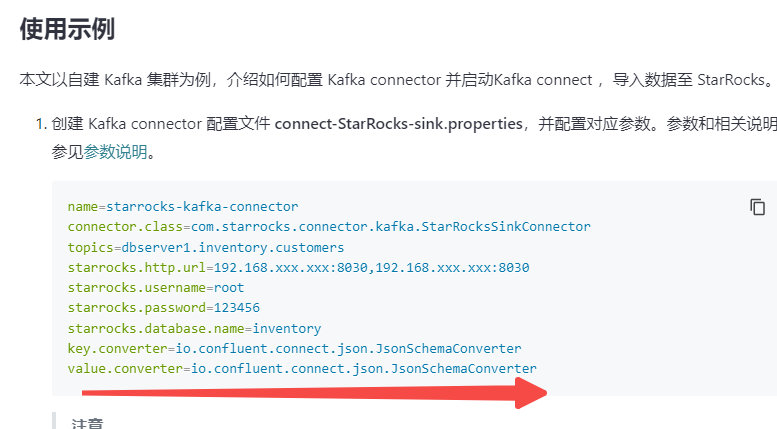
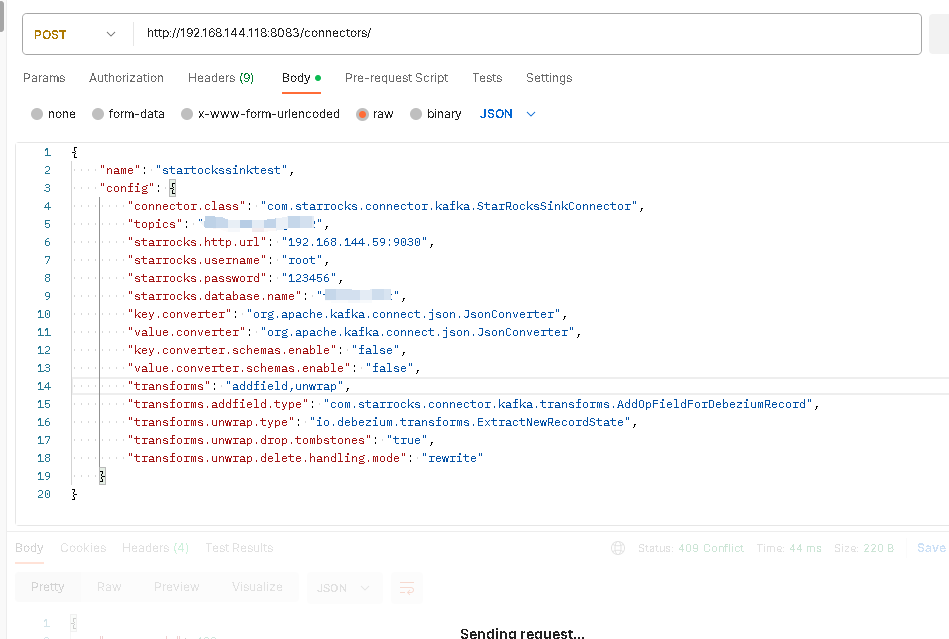
kafka connector配置如下:
curl -i http://10.133.1.1:8083/connectors -H "Content-Type: application/json" -X POST -d '{ "name":"starrocks-kafka-connector", "config":{ "connector.class":"com.starrocks.connector.kafka.StarRocksSinkConnector", "topics":"test1.t1", "starrocks.topic2table.map":"test1.t1:t1", "starrocks.http.url":"10.133.1.1:8030","starrocks.username":"root", "starrocks.password":"xxxx","starrocks.database.name":"ems", "key.converter":"io.confluent.connect.json.JsonSchemaConverter", "value.converter":"io.confluent.connect.json.JsonSchemaConverter", "transforms":"addfield,unwrap", "transforms.addfield.type":"com.starrocks.connector.kafka.transforms.AddOpFieldForDebeziumRecord", "transforms.unwrap.type":"io.debezium.transforms.ExtractNewRecordState","transforms.unwrap.drop.tombstones":"true", "transforms.unwrap.delete.handling.mode":"rewrite" }}'