为了更快的定位您的问题,请提供以下信息,谢谢
【详述】broker load 导入hadoop parquet 数据,报错: [E1011]The server is overcrowded,CUP被占满
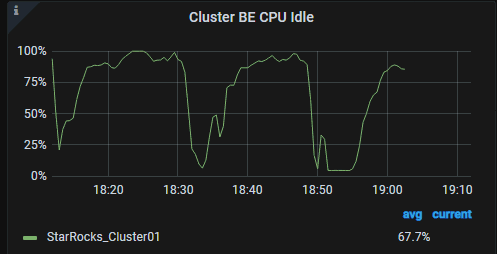
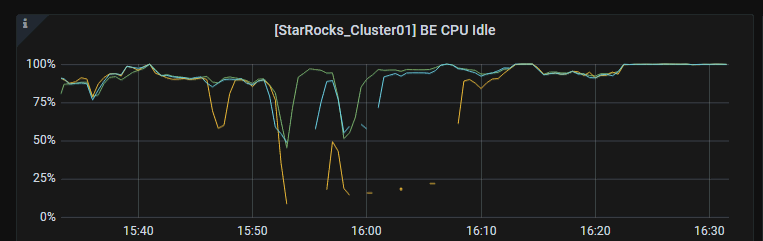
【背景】starrocks部署好后,broker load 导入数据正常半个月,现在出现了这个问题
【业务影响】无法导入数据
【StarRocks版本】2.5.7版
【集群规模】例如:3fe(1 leader + 2 follower)+3be(fe与be分开部署)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/128G/千兆网
【表模型】明细模型
【导入或者导出方式】使用broker load 导入hive 数据
【联系方式】StarRocks社区群18-乙酸乙酯香满屋,或者邮箱chenfan331@163.com
【附件】
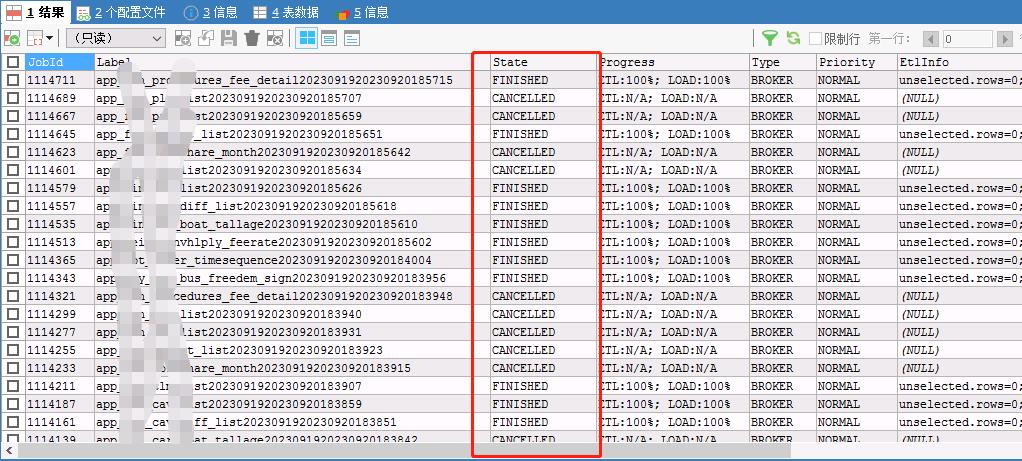
- fe.log/be.INFO/由于日志文件太大,已达600多M,需要时上传
先发报错日志主要内容,替换了网址为xx,其他没有修改
ScannerTotalTime, IOTaskWaitTime, ChunkBufferCapacity, SubmitTaskCount, FileScanner], CastChunkTime=[__MAX_OF_CastChunkTime, __MIN_OF_CastChunkTime], IOTaskExecTime=[__MIN_OF_IOTaskExecTime, __MAX_OF_IOTaskExecTime], MorselsCount=[__MAX_OF_MorselsCount, __MIN_OF_MorselsCount], ReadTime=[__MIN_OF_ReadTime, __MAX_OF_ReadTime], MaterializeTime=[__MIN_OF_MaterializeTime, __MAX_OF_MaterializeTime], ScanTime=[__MIN_OF_ScanTime, __MAX_OF_ScanTime], BufferUnplugCount=[__MAX_OF_BufferUnplugCount, __MIN_OF_BufferUnplugCount], FillTime=[__MIN_OF_FillTime, __MAX_OF_FillTime], CreateChunkTime=[__MAX_OF_CreateChunkTime, __MIN_OF_CreateChunkTime], ScannerTotalTime=[__MAX_OF_ScannerTotalTime, __MIN_OF_ScannerTotalTime], IOTaskWaitTime=[__MAX_OF_IOTaskWaitTime, __MIN_OF_IOTaskWaitTime], SubmitTaskCount=[__MAX_OF_SubmitTaskCount, __MIN_OF_SubmitTaskCount], FileReadTime=[__MAX_OF_FileReadTime, __MIN_OF_FileReadTime], FileScanner=[CastChunkTime, __MIN_OF_FileScanner, FillTime, CreateChunkTime, ReadTime, MaterializeTime, FileReadTime, __MAX_OF_FileScanner]})]), load_counters:{unselected.rows=0, dpp.norm.ALL=491520, dpp.abnorm.ALL=0, loaded.bytes=1171271402}, loaded_rows:491520, backend_id:635002, sink_load_bytes:1171271402, source_load_rows:708608, source_load_bytes:1687282109, load_type:BROKER) query_id=cb72e34d-7f7e-4fe5-9024-9bc2a0ad391b instance_id=cb72e34d-7f7e-4fe5-9024-9bc2a0ad391c
2023-09-20 18:44:00,477 WARN (loading_load_task_scheduler_priority_pool-41|1487) [LoadTask.exec():66] LOAD_JOB=1114387, error_msg={Failed to execute load task}
com.starrocks.common.LoadException: [E1011]The server is overcrowded @10.0.11.xx:8060 [R1][E1011]The server is overcrowded @10.0.11.xx:8060 [R2][E1011]The server is overcrowded @10.0.11.xx:8060 [R3][E1011]The server is overcrowded @10.0.11.xx:8060
at com.starrocks.load.loadv2.LoadLoadingTask.actualExecute(LoadLoadingTask.java:261) ~[starrocks-fe.jar:?]
at com.starrocks.load.loadv2.LoadLoadingTask.executeOnce(LoadLoadingTask.java:175) ~[starrocks-fe.jar:?]
at com.starrocks.load.loadv2.LoadLoadingTask.executeTask(LoadLoadingTask.java:146) ~[starrocks-fe.jar:?]
at com.starrocks.load.loadv2.LoadTask.exec(LoadTask.java:60) ~[starrocks-fe.jar:?]
at com.starrocks.task.PriorityLeaderTask.run(PriorityLeaderTask.java:25) ~[starrocks-fe.jar:?]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_201]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_201]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_201]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_201]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_201]
- 完整的报错异常栈,CPU爆满图片