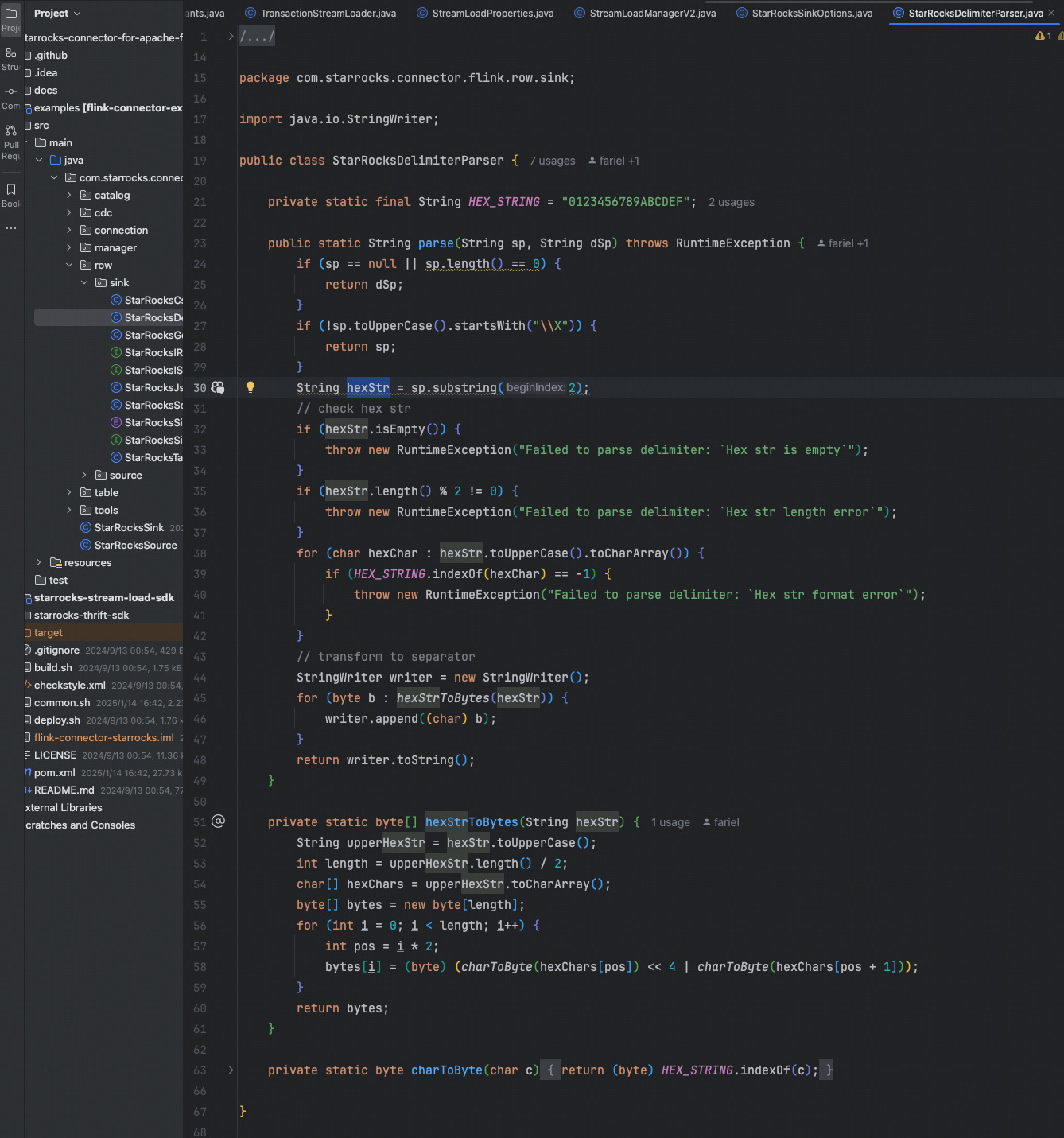
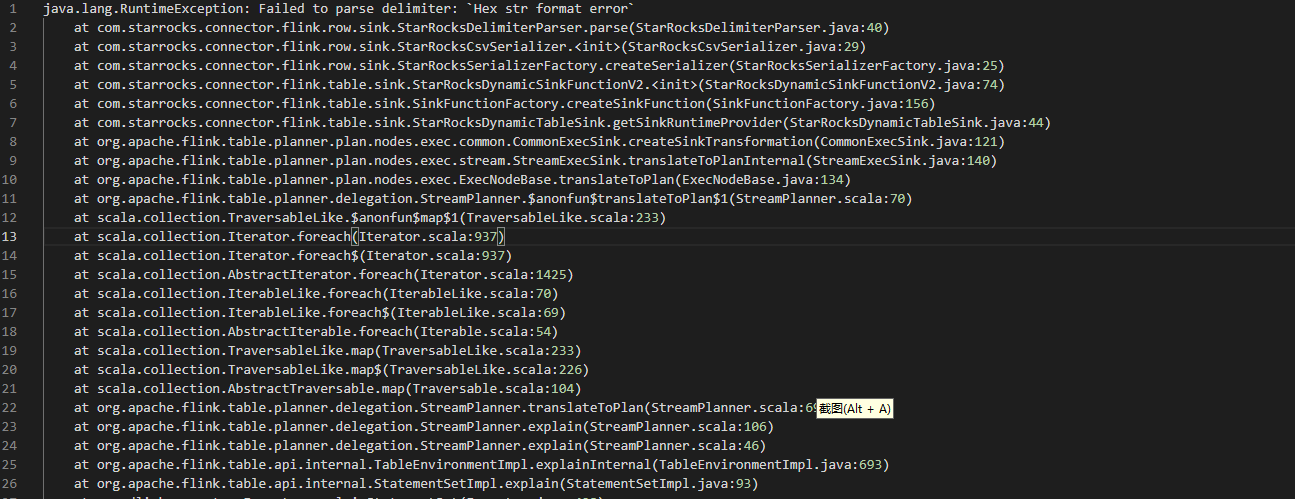
1、问题截图
2、脚本
–MySQL表
CREATE TABLE mysql_crawl_enterprise_website (
id int,eid varchar,enterprise_name varchar,website varchar,html varchar,PRIMARY KEY (
id) NOT ENFORCED) WITH (
‘connector’ = ‘mysql-cdc’,
‘hostname’ = ‘’,
‘port’ = ‘’,
‘username’ = ‘’,
‘password’ = ‘’,
‘database-name’ = ‘db_enterprise_outer_resource’,
‘table-name’ = ‘crawl_enterprise_website’,
‘scan.incremental.snapshot.enabled’ = ‘false’
);
–Kafka表
CREATE TABLE kafka_crawl_enterprise_website (
id int,
eid varchar,
enterprise_name varchar,
website varchar,
html varchar,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
‘connector’ = ‘upsert-kafka’,
‘topic’ = ‘ods_crawl_enterprise_website’,
‘properties.bootstrap.servers’ = ‘’,
‘properties.group.id’ = ‘source_province’,
‘properties.max.request.size’ = ‘104857600’,
‘key.format’ = ‘json’,
‘value.format’ = ‘json’
);
–Starrocks表
CREATE TABLE starrock_ods_crawl_enterprise_website (
id int,
eid varchar,
enterprise_name varchar,
website varchar,
html varchar,
PRIMARY KEY (id) NOT ENFORCED – 如果要同步的数据库表定义了主键, 则这里也需要定义
) WITH (
‘connector’ = ‘starrocks’,
‘jdbc-url’ = ‘jdbc:mysql://:9030’,
‘load-url’ = ‘:8030’,
‘database-name’ = ‘ods’,
‘table-name’ = ‘ods_crawl_enterprise_website’,
‘username’ = ‘’,
‘password’ = ‘’,
‘sink.buffer-flush.interval-ms’ = ‘5000’,
‘sink.properties.column_separator’ = ‘\x7c\x5e\x7c’,
‘sink.properties.row_delimiter’ = ‘\x02’
);
–MySQL数据同步到Kafka
insert into kafka_crawl_enterprise_website select * from mysql_crawl_enterprise_website;
–Kafka数据同步到Starrocks
insert into starrock_ods_crawl_enterprise_website select * from kafka_crawl_enterprise_website;
3、测试数据