
1、环境介绍
当前实时任务接收所有前端上报的数据,中间通过flink任务将数据流拆解为实时任务和离线任
务,近三天的数据实时写⼊CK,⽽离线数据为flink接收数据流之后⼏乎不做处理通过⽂件流的形式写⼊
华为云的hive中,因此CK⾥的数据和hive中的数据⼀致,除了华为云之后,现在还有线下的规模较⼩的
CDH集群和规模⽐较⼤的集群(简称⼤集群)。
CDH集群上主要部署flink实时任务,同时为了分解华为云的压⼒,会把部分数据从线上的华为云同步到线下的⼤集群上。
2、 业务介绍
⽬前线下CK中近3天的宽表数据,主要做⼀些实时的维度的PV和UV的计算(只查询近3天的数据),表
关联的场景⽐如漏⽃、留存等场景以及有3天前的数据是查询线上的华为云hive数据。
3、 starrocks⽅案
短期计划
短期计划是打算在本地再搭⼀套starrocks,利⽤starrocks通过hive catalog查询表数据的功能,快速实现报表查询功能,由于通过hive catalog查询华为云会产⽣⼤量的⽹络开销,对⽬前带宽的是很⼤的考验,因此⽬前计划查询的是⼤集群上的数据,
⻓期计划
⽤starrocks取代hive和CK,实现真正的流批⼀体
4、查询目标
- 实时任务写⼊性能测试
- 数据查询性能测试
由于hive的查询性能和starrocks差距太⼤,就不做对⽐分析了
5、硬件规格
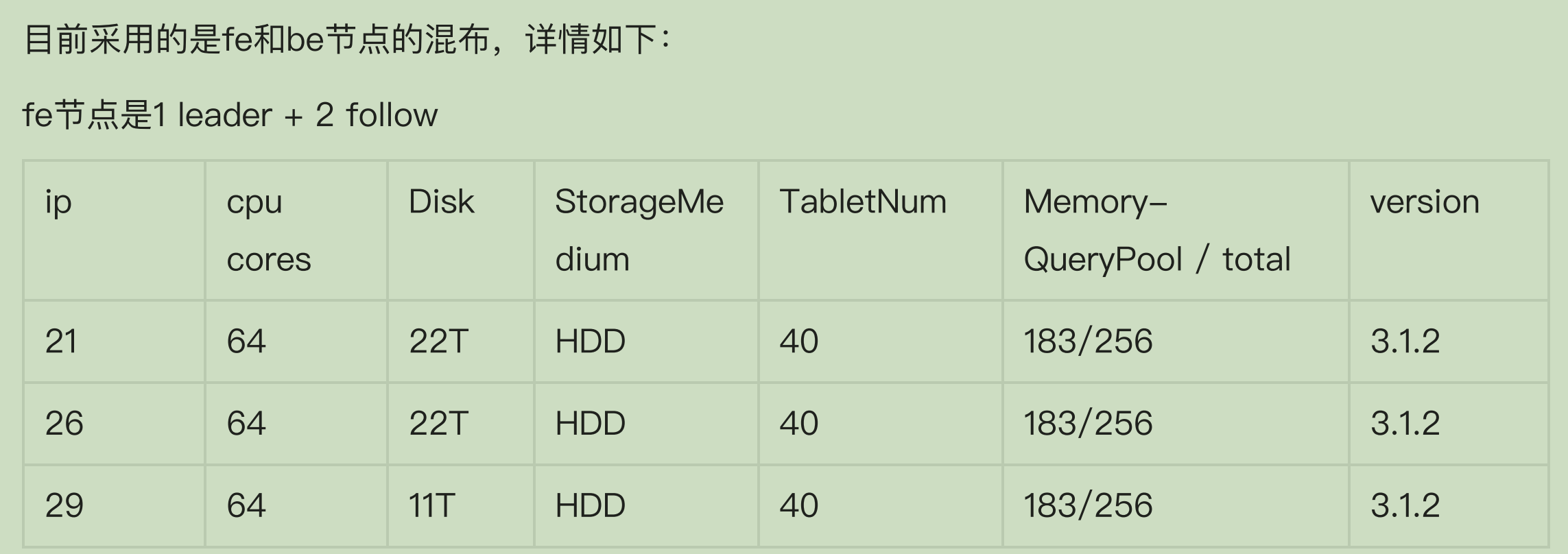
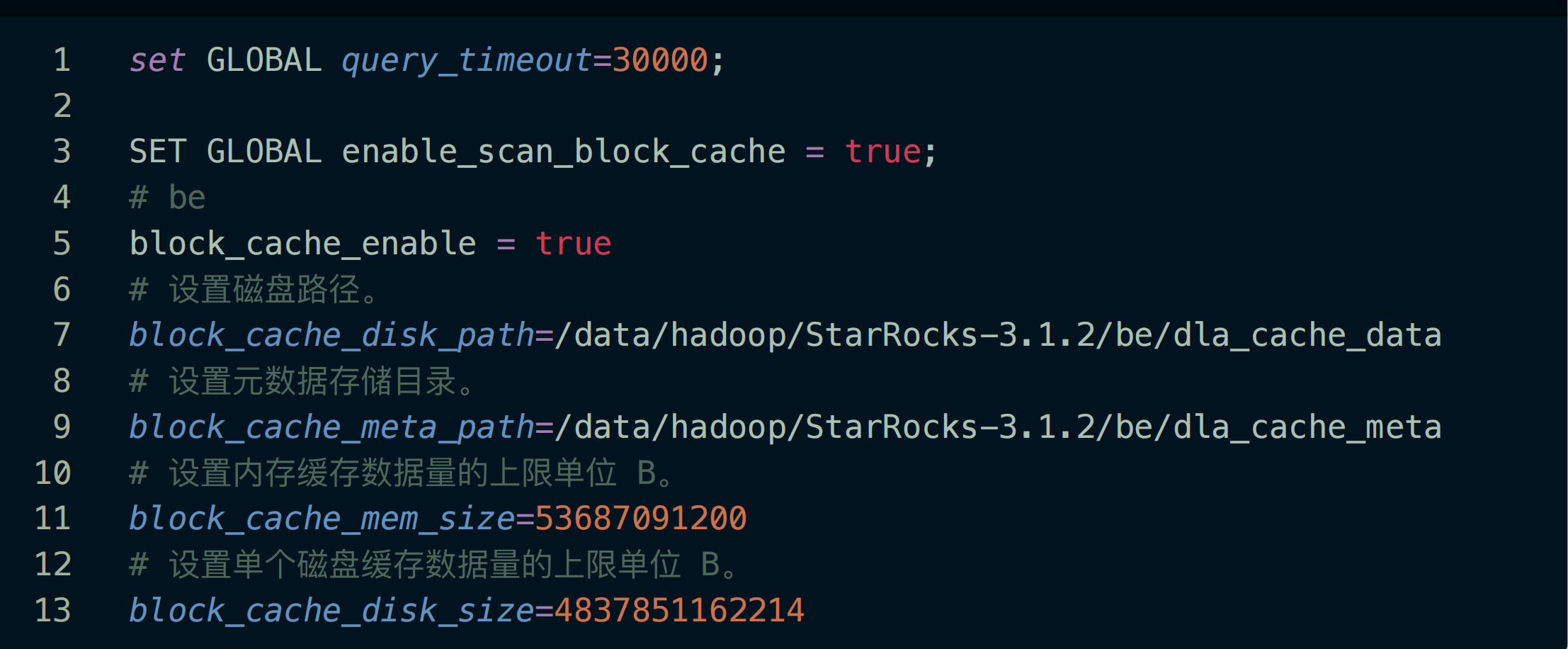
6、参数设置
7、数据规模
表结构:按照日期分区,按照产品ID排序
单月数据量:
new_user:6990135条
daily_active_user:92155306
event_1:10354689125
event_2:777605922
event_3:14453971633
单年数据量(13个月)
new_user:61970661条
daily_active_user:1066125517条
event_1:95232274288
event_2:5070695497
event_3:117199721038
8、测试 SQL-流量趋势附件2-1:流量趋势 一年 三并发测试-按维度 ip=21.log (1.3 MB)
见附件 Profile
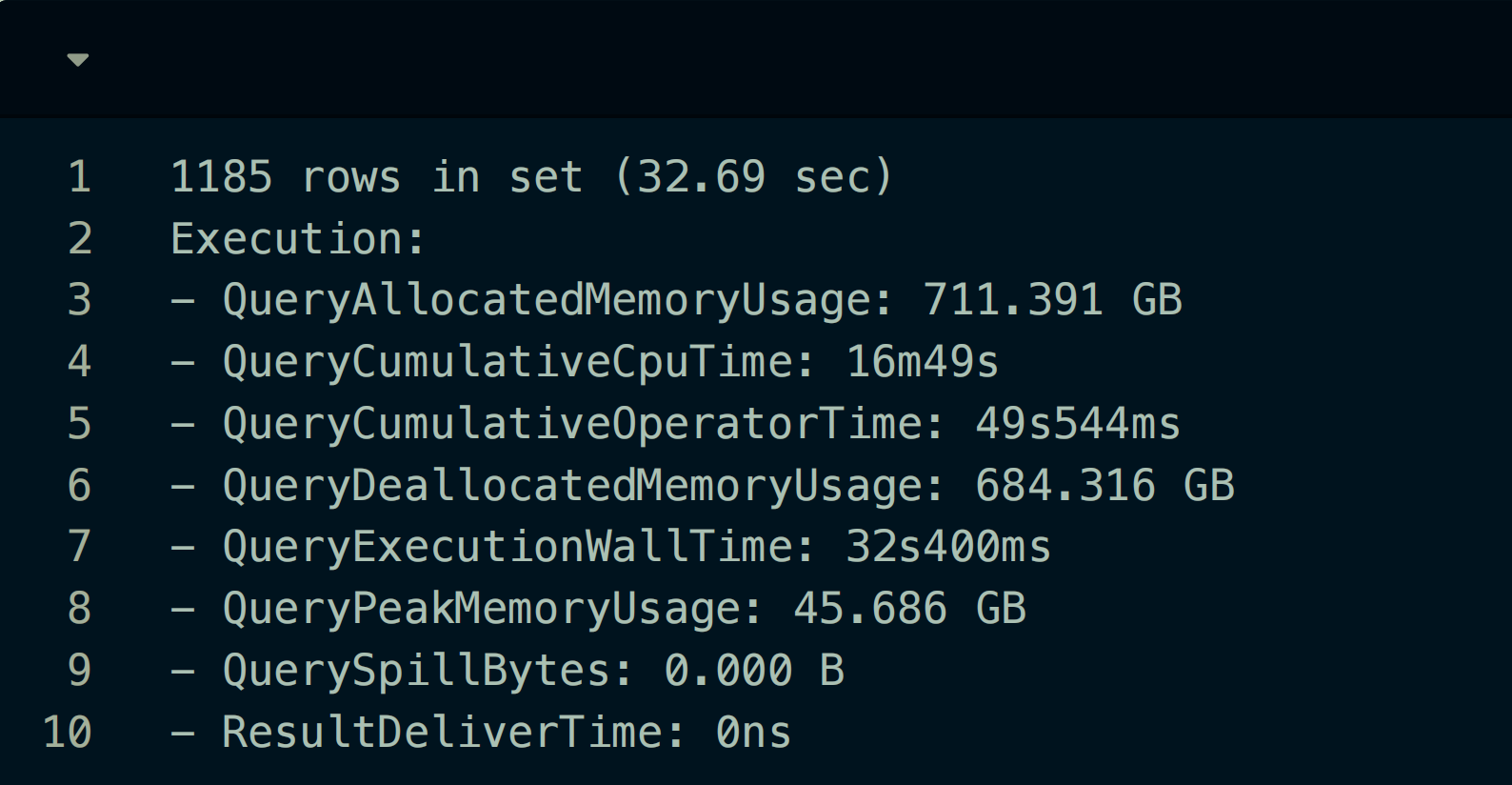
9、测试结果
⼀年的数据量同时只跑⼀个的单发任务
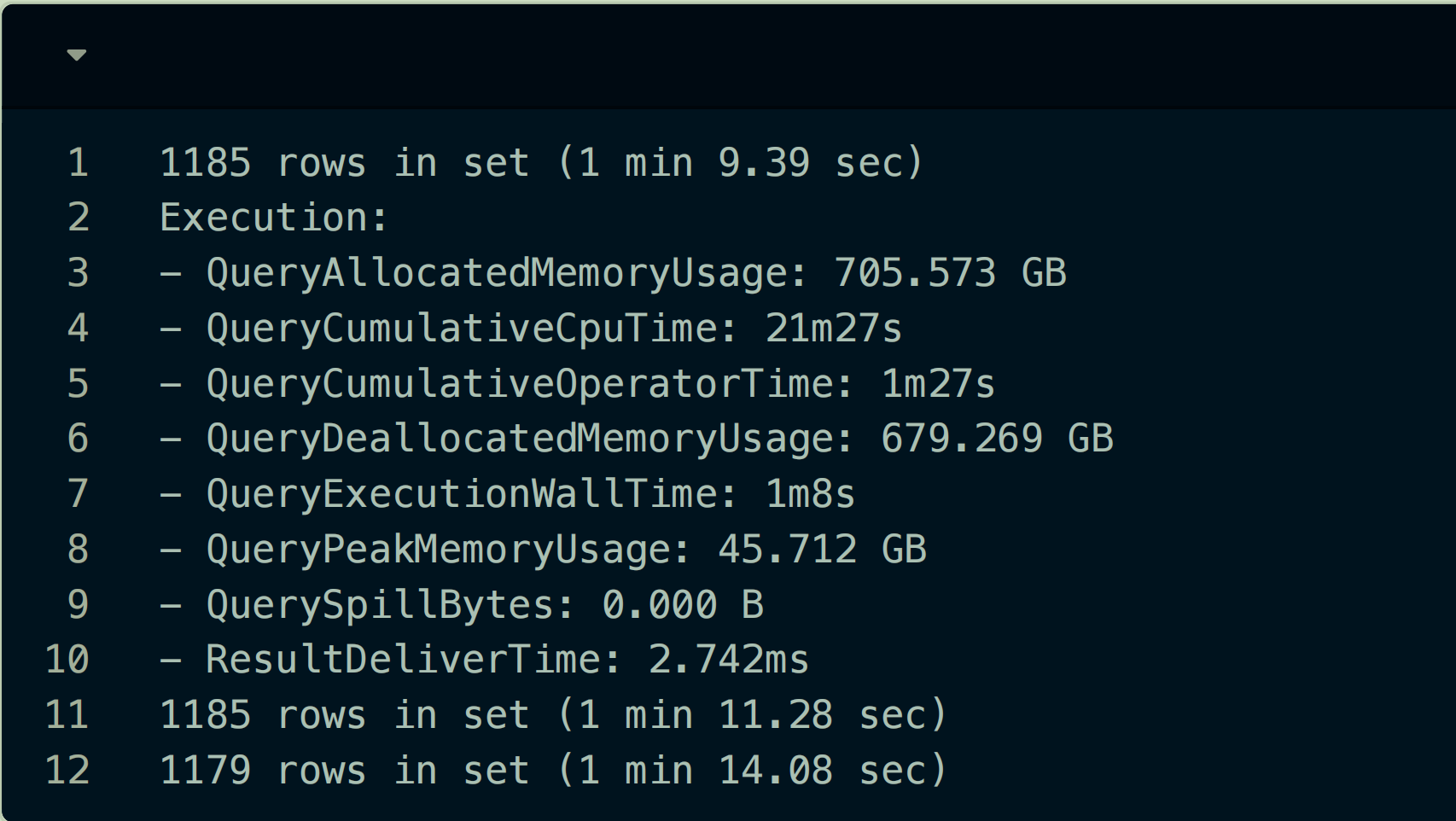
⼀年的数据量同时跑三个的任务
10、其它
1)pipeline
2)explain_costs
explain_costs.log (376.4 KB)

