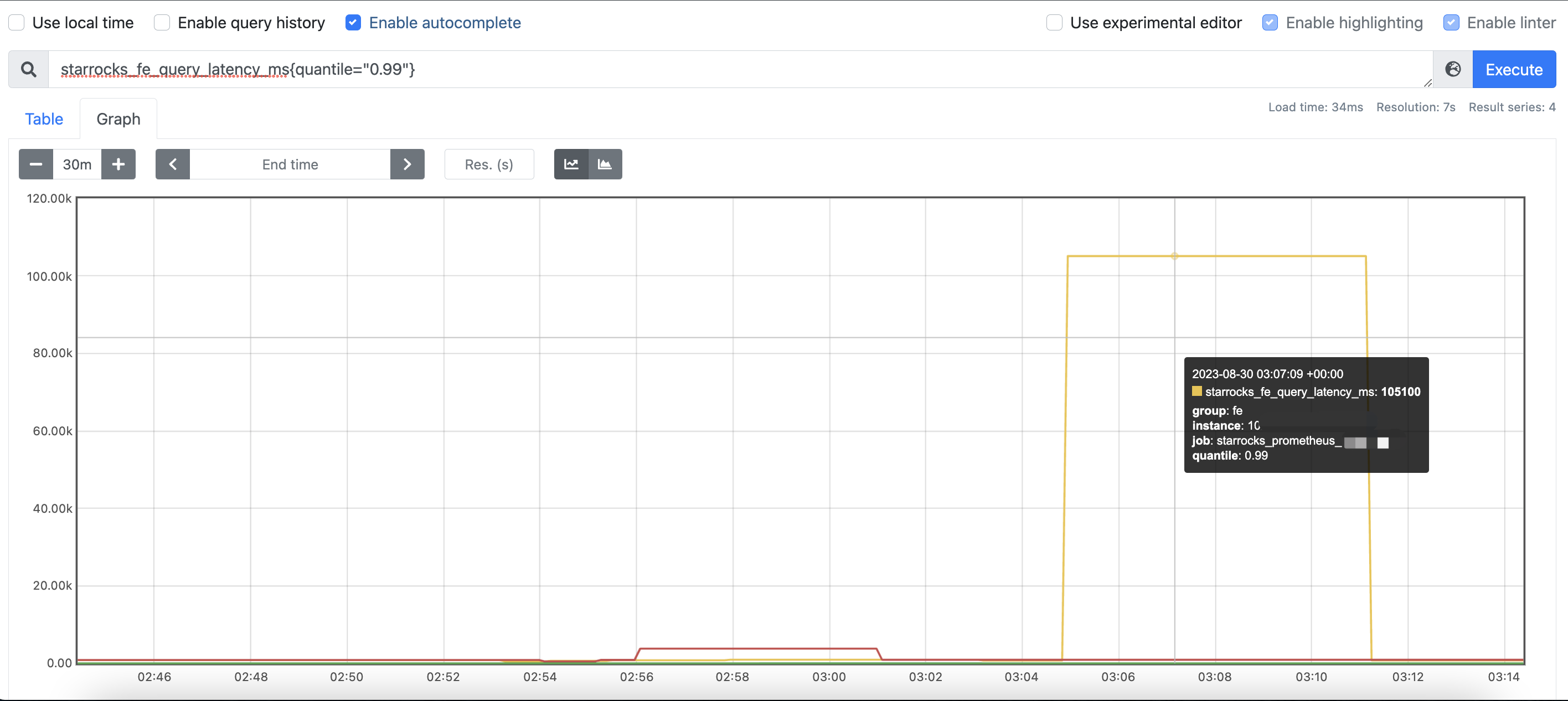
【详述】当前我们做了starrocks_fe_query_latency_ms{quantile=“0.99”}的报警,不过发现经常报警的一个case是:一个大query执行完毕之后就没有任何请求,对应fe的starrocks_fe_query_latency_ms{quantile=“0.99”}始终是一个很大的值,持续数分钟,那么请问metric: starrocks_fe_query_latency_ms 具体是如何统计的呢?统计频率是?
另外执行一个大query之后,后面没有任何请求,是不是对应的latency是不是应该为0ms呢?
如下图: