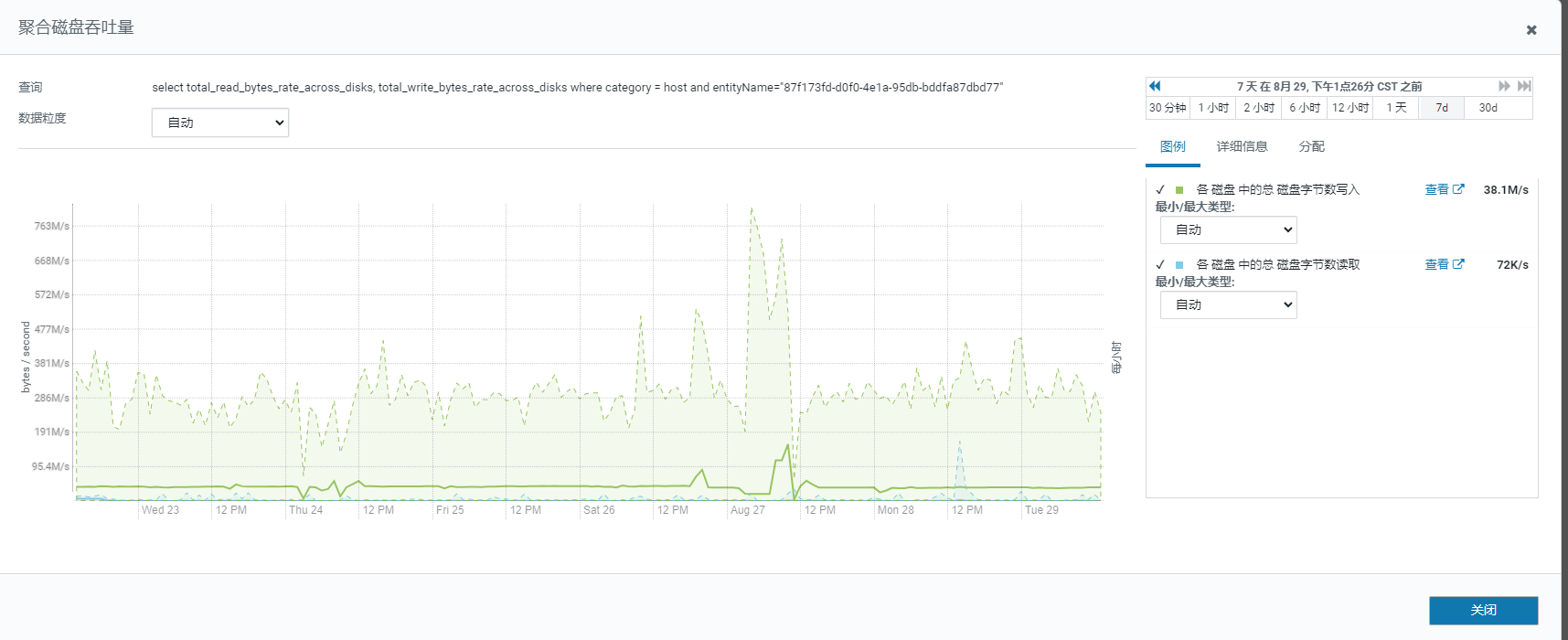
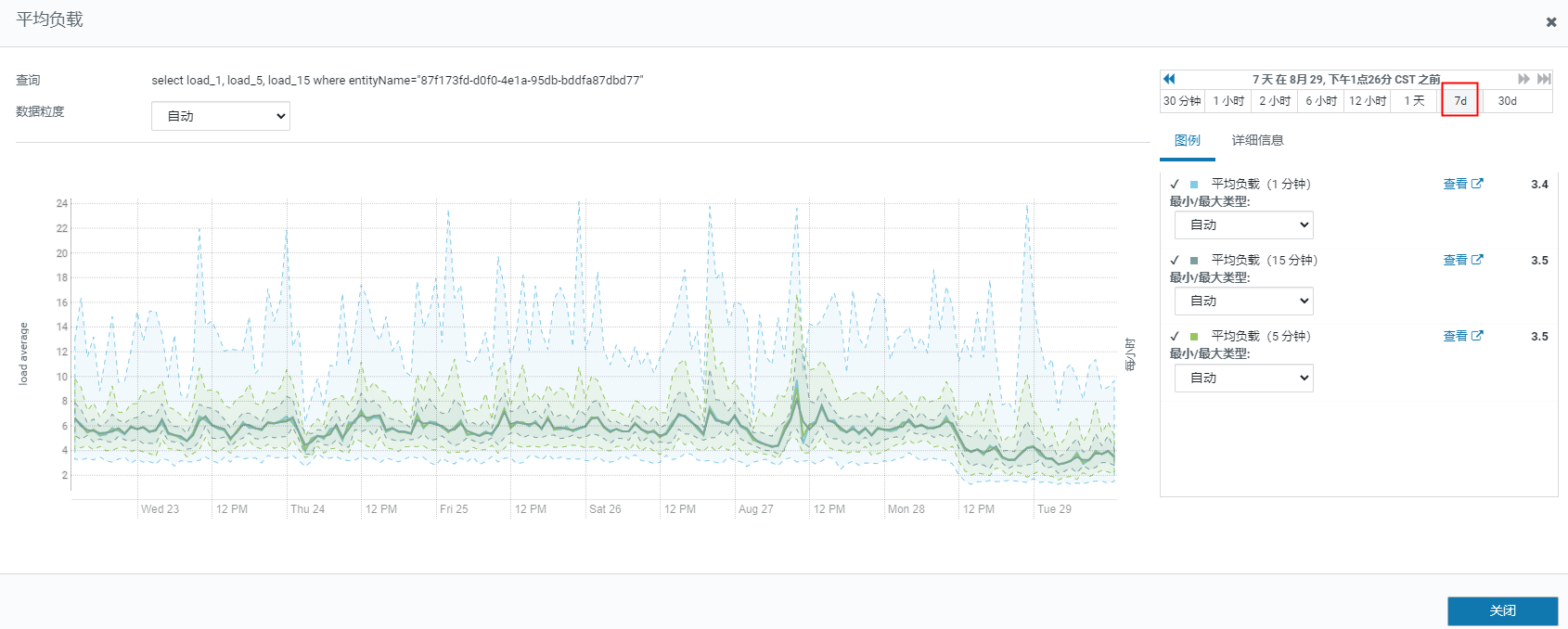
最近7天的cpu负载,峰值最高能达到23倍
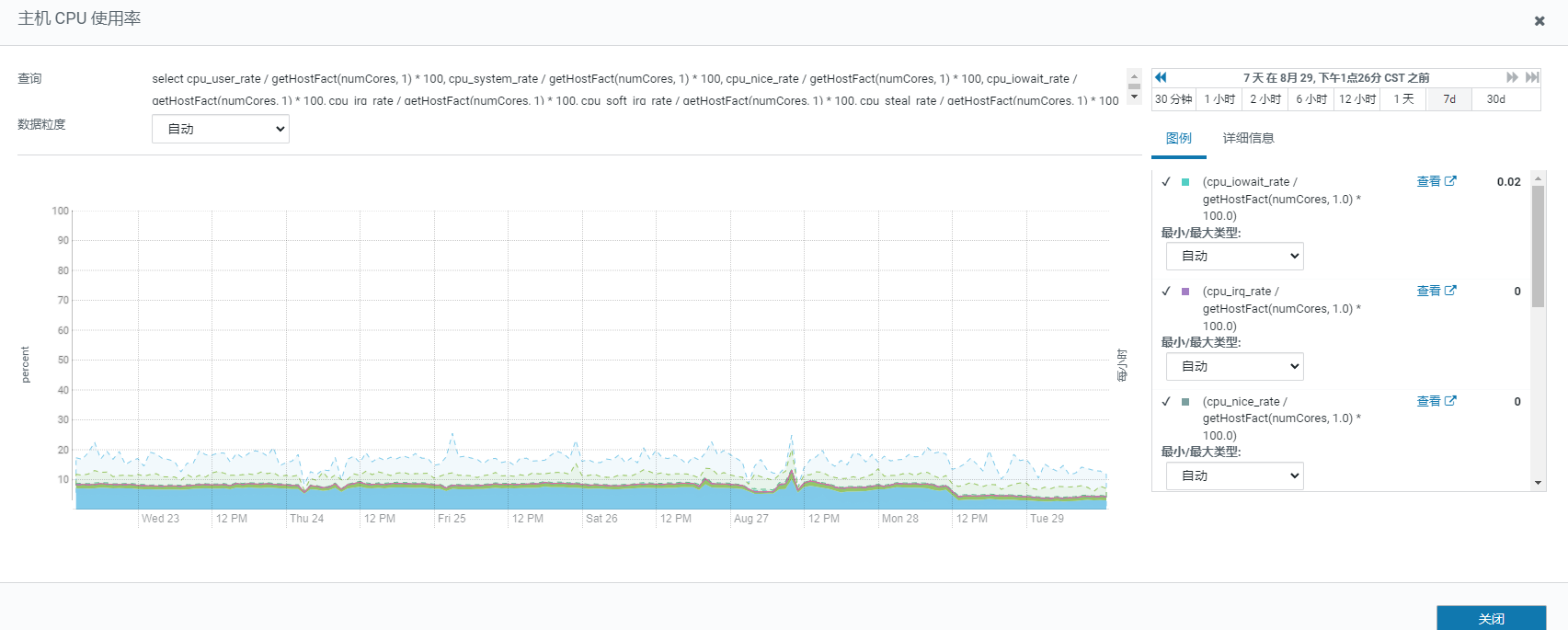
cpu使用率
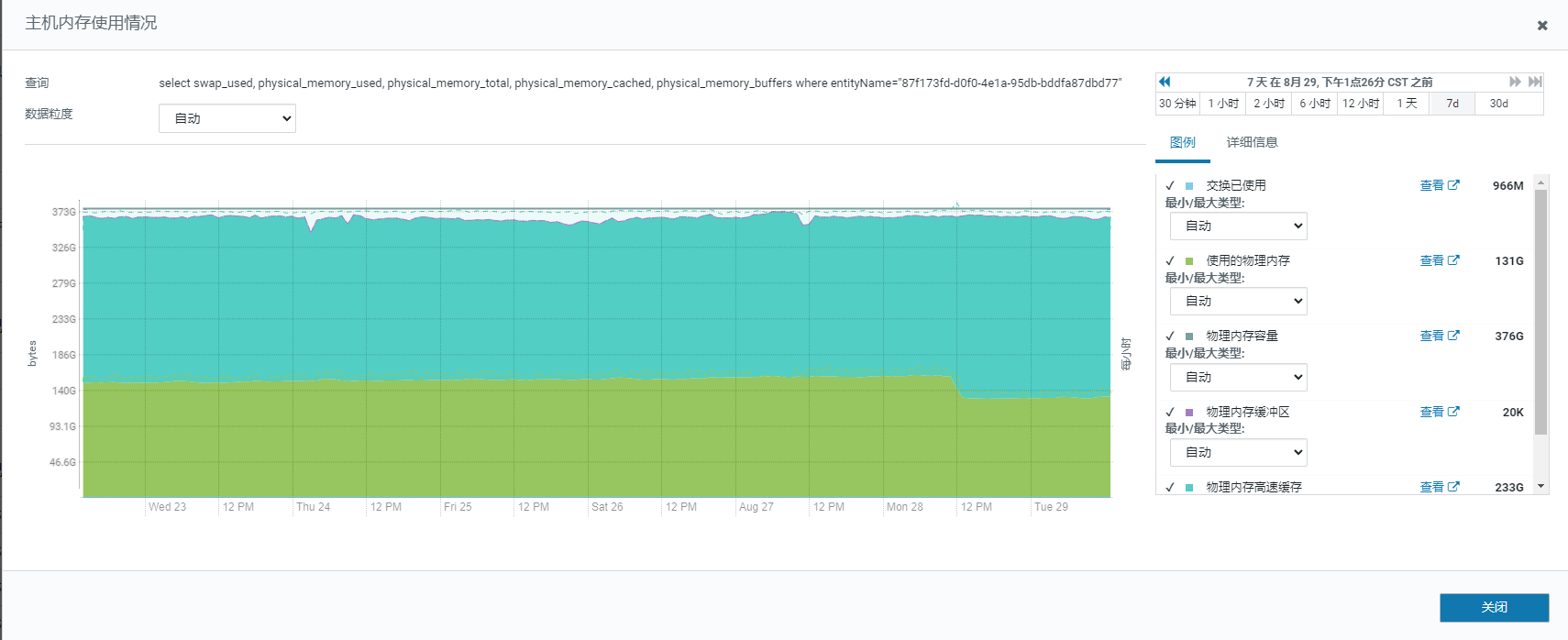
内存情况
磁盘读写情况

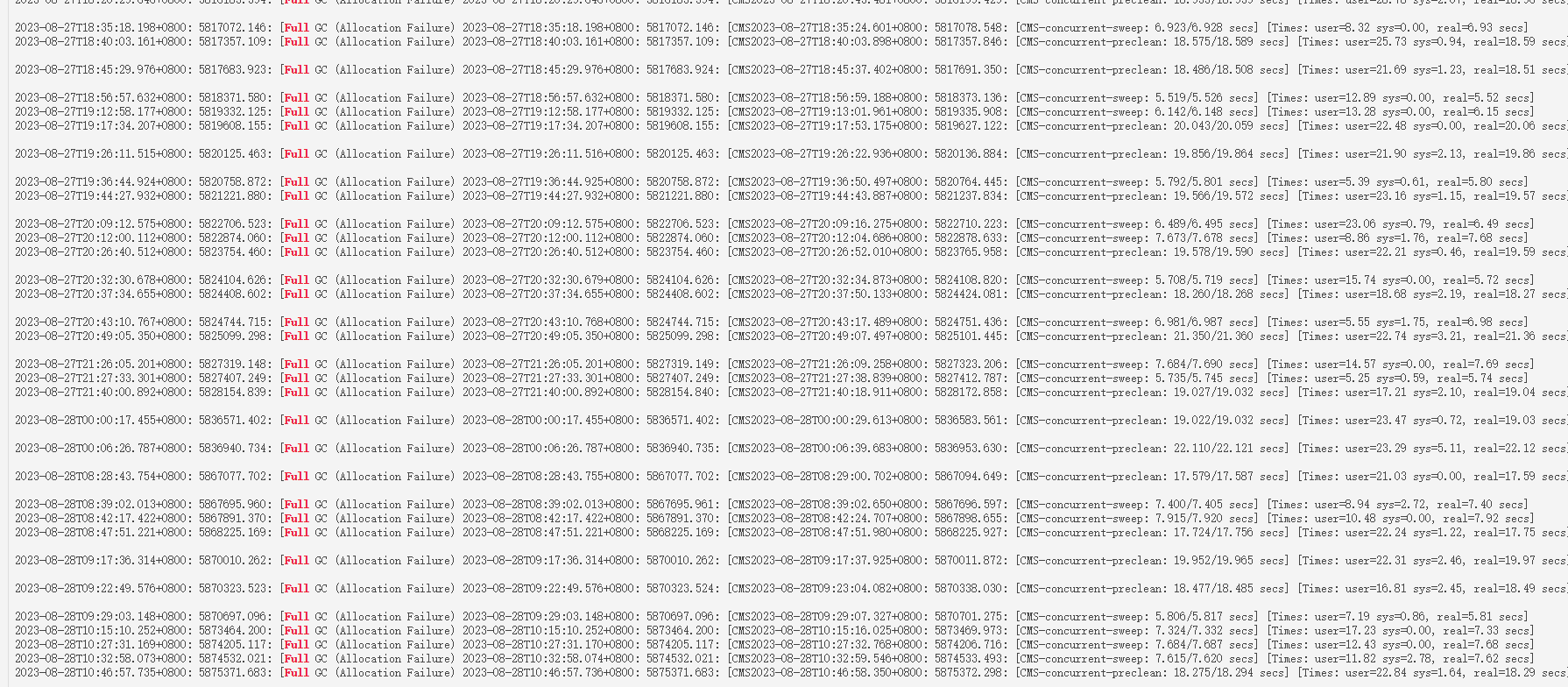
根据fe.log中的日志看,初步判断是 fe的jvm内存不够,可能是Leader节点内存使用过高发生了Full GC,也可能是Follower节点内存使用过高发生了Full GC。
目前看2个be,单个be上的tablet个数有 52万多个,但是集群数据量不大,说明存在非常多的tablet个数设置不合理的表。过多的tablet容易造成fe内存压力大。
看看fe的jvm内存监控情况,以及看看 fe.gc.log 是否触发了 full gc 或者 gc时间超过60秒
这个tablet的话,我们单台机器: 72c+376g+6块ssd ,一共两台机器,建表时指定BUCKETS 24,然后基本都是分区表,这个不合理吗?
buckets个数根据数据量来,2.4以上的版本 单个桶最大可以达到10G,一般 100M-1G左右,避免tablet个数太多
如果提高FE内存,能暂时解决崩溃问题不~
这是交换区还开着么,需要关掉交换区。可以参考检查下机器系统参数。
先调大 fe的jvm 大小,观察一段时间看是否还会频繁重启
是Follower挂了,还是Leader挂了
leader和follow都挂过,我暂时先调大一下内存,后续升级
gc日志能发下吗,先定位下问题
sr使用到的磁盘没有交换,这个交换是系统上其它的磁盘发生的,现在扩大了fe vm的内存到了50g,观察一阵子看看
发一下完整的 gc文件,自动重启前的gc文件
fe jvm使用率百分之10都不到,应该不是这个原因吧
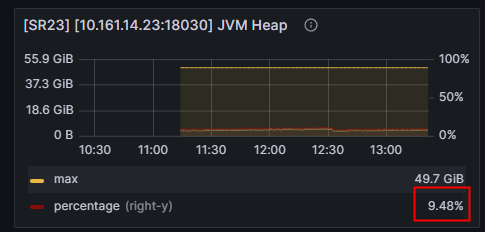
这个gc是2023-08-28 11:18 fe崩溃时的
20230828_gclog.txt (1.7 MB)
下面这个是2023-08-26 18:18左右leader节点崩溃时的gc
fe.gc.20230826.txt (2.5 MB)
现在好了吗?看起来像是内存泄漏了
升级到3.0.5后暂未出现问题。