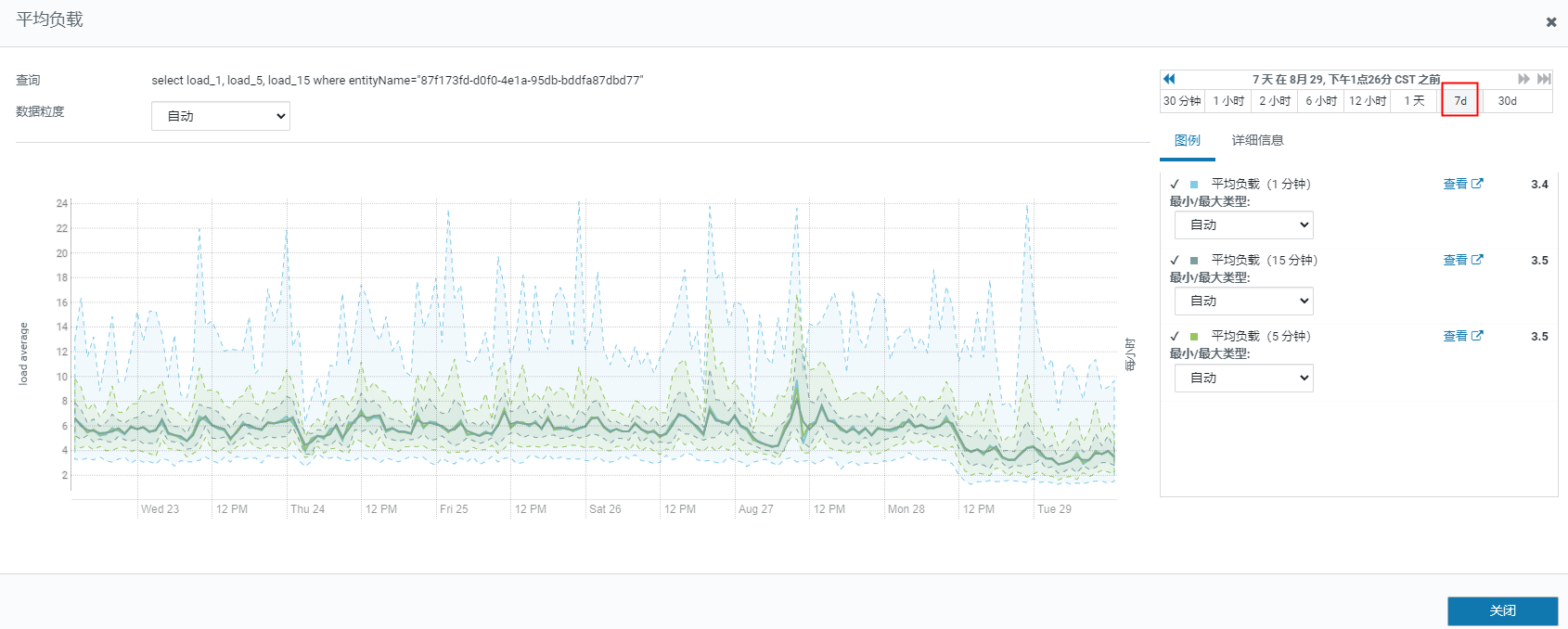
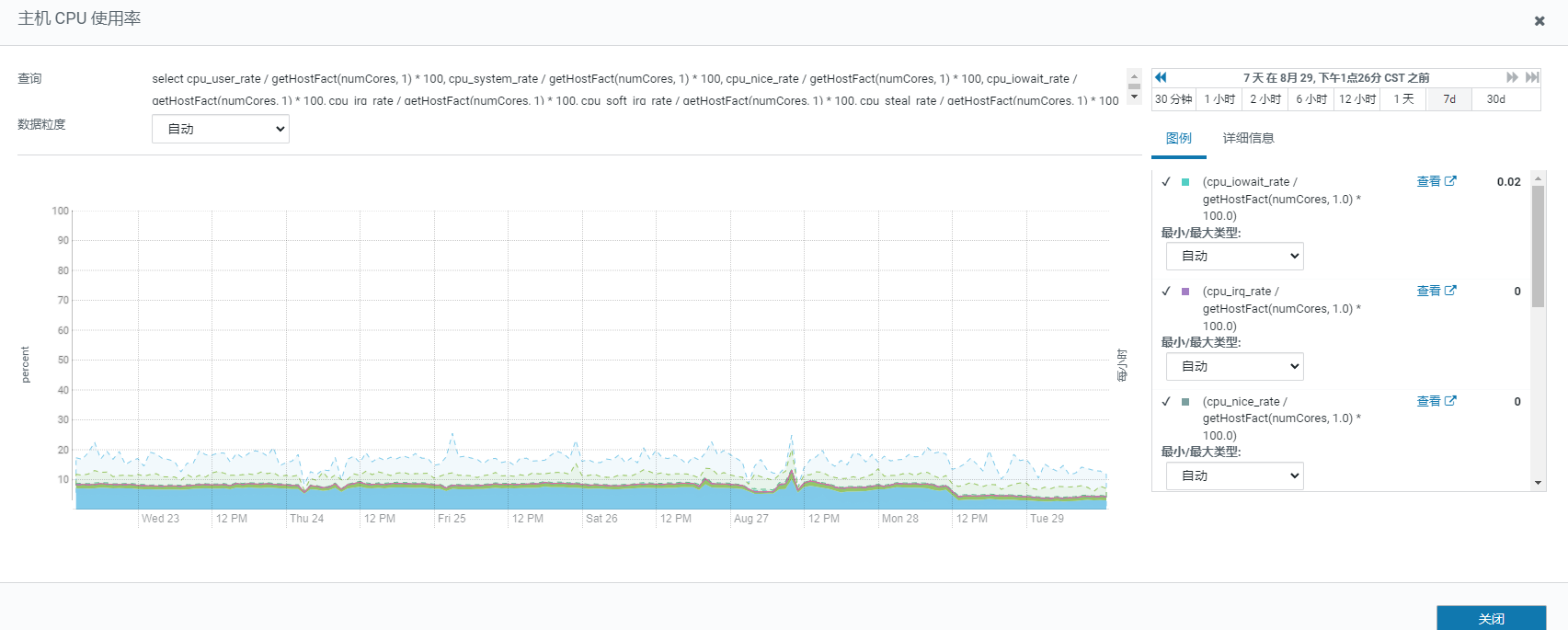
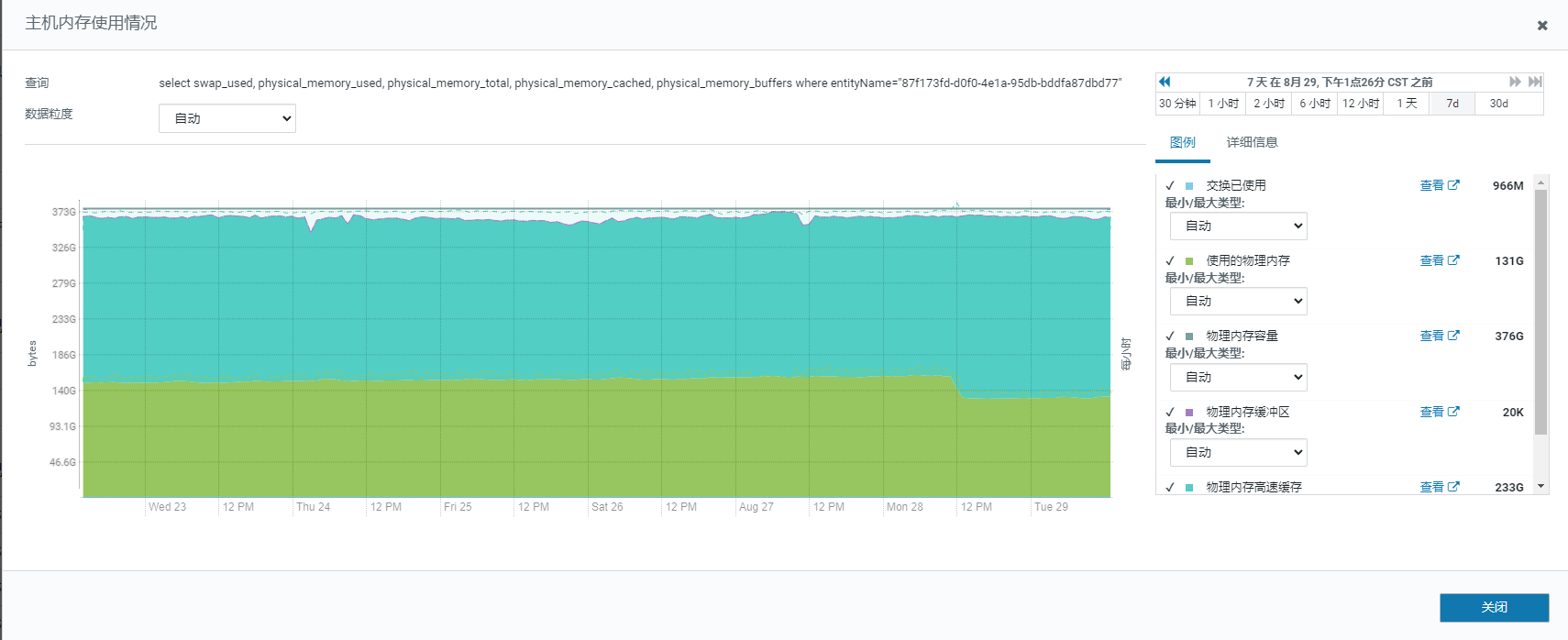
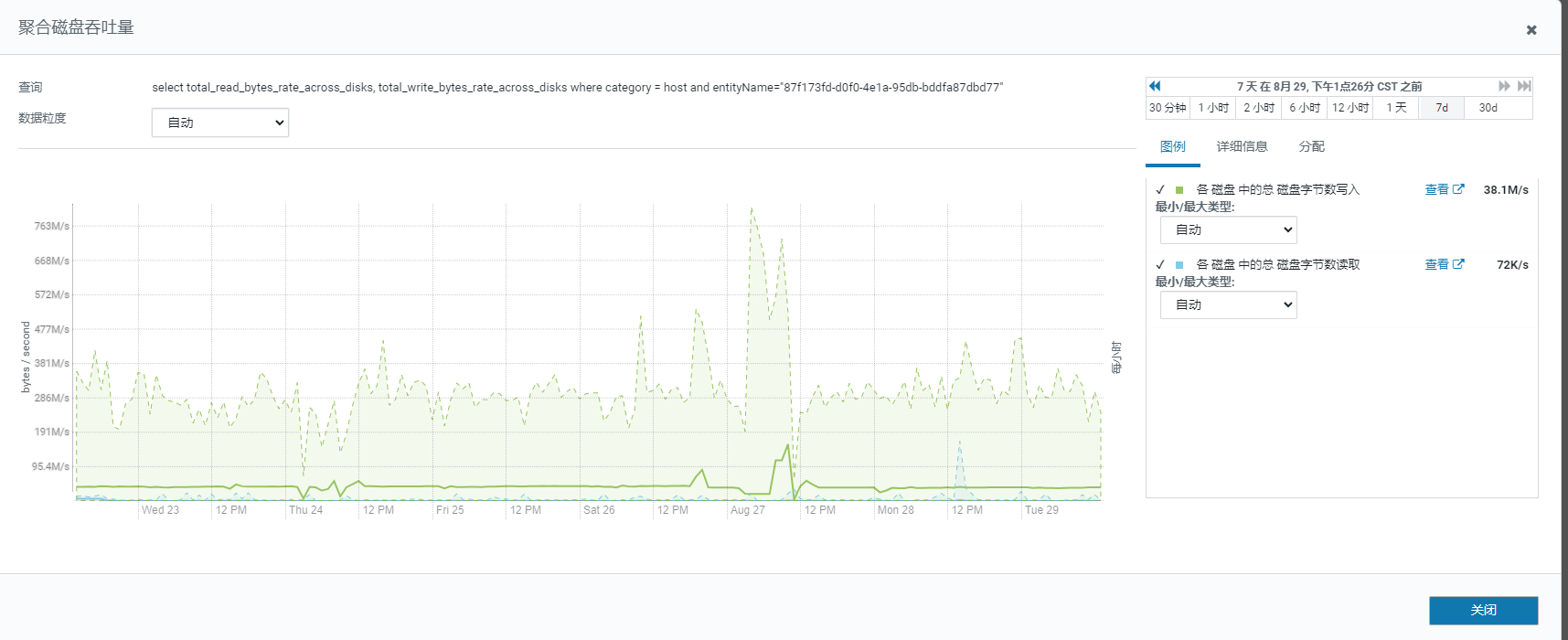
【详述】FE宕机
【背景】
【业务影响】
【StarRocks版本】3.0.2
【集群规模】2fe +2be(fe与be混部)
【机器信息】72C/376G/万兆
【联系方式】社区群3: 阿坚
【附件】
fe.out
fe.out.txt (17.2 KB)
fe.warn
fe.warn.txt (19.6 KB)
fe.conf中java配置
JAVA_OPTS="-Dlog4j2.formatMsgNoLookups=true -Xmx32768m -XX:+UseMembar -XX:Survivv
orRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSPP
arallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMM
SPerMB=0 -Xloggc:${LOG_DIR}/fe.gc.log.$DATE -XX:+PrintConcurrentLocks"