
1. 物化视图支持基于()数据源创建?ABCD
A. StarRocks内表
B. Hive Catalog、Hudi Catalog 和 Iceberg Catalog 中的表和view
C. StarRocks物化视图
D. StarRocks逻辑视图
https://docs.starrocks.io/zh-cn/latest/using_starrocks/Materialized_view#创建异步物化视图
2. 物化视图可以被应用到()场景?ABC
A. 跟逻辑视图配合,用于数据建模和数仓分层
B. 利用透明改写能力,为报表加速
C. 湖上数据查询需要低延迟、高并发,Data Cache满足不了性能时,通过物化视图进仓加速
3. 物化视图有几种刷新方式? ABC
A. 定时刷新:即通过设定开始刷新时间与刷新间隔,根据时间推移自动刷新
B. 手动刷新:即通过命令手动触发刷新
C. 自动刷新:即在基表发生数据变化时,触发式自动刷新
- D. 随机刷新:即随机挑选一位幸运儿当场刷新
物化视图支持定时、手动、自动刷新三种方式,可以根据实际需要选择。
4. 关于增量刷新,以下哪些说法是正确的?ABDE
A. StarRocks 当前支持的增量刷新是分区级别的增量刷新,流式的增量算子刷新在roadmap中
B. 如果想要利用分区级别的增量刷新,物化视图的分区列需要存在于base表的分区列中
C. 如果是多表join的物化视图,任意一张表更新了都会触发分区级别的增量更新
D. Hive 外表物化视图也可以分区级别增量刷新,但是需要开启元数据轮询功能
E. 如果 base 表是非分区表,物化视图只能全量刷新
https://docs.starrocks.io/zh-cn/latest/data_source/catalog/hive_catalog#周期性刷新元数据缓存
5. 小明基于以下三张表创建了多表关联的物化视图。哪个base表刷新的时候会触发分区级别增量刷新? A
表A:分区表,以dt_a1,dt_a2为分区列
表B:分区表,以dt_b1为分区列
表C:分区表,以dt_c1, dt_c2 为分区列
物化视图:a join b join c的物化视图,以dt_a1为分区列
A. 表A
B. 表B
C. 表C
D. 任意一张表都可以触发分区级别增量刷新
E. 不能触发分区级别增量刷新
物化视图的分区列来自于哪一张base表,就会根据对应表的刷新触发分区基本的刷新。如果是其他base表有数据更新且不是排除表,则会触发全表刷新。
6. 如何尽可能控制物化视图的刷新资源? ABCD
A. 为物化视图的刷新设置资源组
B. 在物化视图的properties中为其设置刷新开启算子落盘
C. 合理的设置物化视图的分区,从而利用分区级刷新,必要时限制单次刷新的分区数量
D. 将不必要刷新的表(比如维度表)设置为排除表
E. 不刷了现算比较香
控制刷新资源有几个思路:
让刷新少用资源:使用资源组,开启算子落盘防止内存超限
尽可能少刷:根据实际使用需求,尽可能利用到分区级别刷新,在可接受范围内减少刷新
7. 查询改写题:小明根据ssb测试集中的两张base表创建了一张物化视图,如下。以下哪个sql可以透明地加速到这个物化视图上?ABC
create materialized view join_mv1 distributed by hash(`lo_orderkey`) as
select
lo_orderkey,
lo_linenumber,
lo_revenue,
lo_partkey,
c_name,
c_address
from
lineorder
inner join customer on lo_custkey = c_custkey;
A.
select
lo_orderkey,
lo_linenumber,
(2 * lo_revenue + 1) * lo_linenumber,
upper(c_name),
substr(c_address, 3)
from
lineorder
inner join customer on lo_custkey = c_custkey;
B.
select
lo_orderkey,
lo_linenumber,
lo_revenue,
c_name,
c_address,
p_name
from
lineorder
inner join customer on lo_custkey = c_custkey
inner join part on lo_partkey = p_partkey;
C.
select
lo_orderkey,
lo_linenumber,
lo_revenue,
c_name
from
lineorder
inner join customer on lo_custkey = c_custkey;
D.
select
lo_orderkey,
c_name,
sum(lo_revenue) as total_revenue,
max(lo_discount) as max_discount
from
lineorder
inner join customer on lo_custkey = c_custkey
group by
lo_orderkey,
c_name;
A 仅包含表达式和函数计算,可以改写。物化视图支持函数计算,四则运算的改写
B 在物化视图包含的表的基础上又join了一张新的表,可以复用lineorder与customer已经join的结果。
C 是基础的select,可以改写。
D 不能改写,因为选择了lo_discount列,mv中不包含这一列,所以不能改写。如果只是对mv内包含的列进行聚合计算,则可以改写。
8. 定义物化视图的查询语句里包含哪些会导致物化视图不能用于查询改写?ABDEF
A. Limit
B. order by
C. join
D. Union
E. 窗口函数
F. random函数
为了物化视图能够最大程度被复用,物化视图内请不要创建包含limit,order by,union,窗口函数,随机函数。
9. 如何判断一个查询能够被改写到物化视图?AB
A. Explain logical + 查询,通过看执行计划判断,如果有Scan节点命中物化视图则表示可改写成功
B. Trace rewrite + 查询,通过trace命令查看,如果有物化视图显示Rewrite Succeed则表示可改写成功
C. 目前没有什么判断方法
Explain logical和trace rewrite都可以模拟查询情况,欢迎使用。
10. 以下哪些场景可以被查询改写?ABCE
A. 定义物化视图的查询语句:A join B,后续查询:A join B join C
B. 定义物化视图的查询语句:A join B join C,并且声明了主外键约束, 后续查询:A join B
C. 定义物化视图的查询语句:col1, count(distinct col2) group by col1,后续查询:col1, count(distinct col2) group by col1
D. 定义物化视图的查询语句:col1, col2, count(distinct col3) group by col1, col2,后续查询:col1, count(distinct col3) group by col1
E. 定义物化视图的查询语句:co1, bitmap_union(to_bitmap(col2)) group by col1,后续查询:col1, count(distinct col2) group by col1
A 典型的query delta改写
B 典型的view delta改写
C 物化视图支持count distinct改写
D 因为查询再count distinct之上又进行了聚合:物化视图group by 两列,查询仅group by了其中一列,因此无法改写。
E 可以改写。在mv中使用bitmap_union(to_bitmap(col))定义,查询时,count(distinct col)会被自动改写为bitmap_union()
11. 物化视图是否可以只存储最近的分区数据? A
A. 可以,物化视图可以跟base表的生命周期不一样
B. 不可以,创建物化视图后,会对全表数据进行计算
可以单独为物化视图设置ttl:https://docs.starrocks.io/zh-cn/latest/sql-reference/sql-statements/data-definition/CREATE%20MATERIALIZED%20VIEW#参数
12. 在默认配置下,如果base表已经导入了新的分区数据,而物化视图还没有更新完成,在查询改写时会导致数据错误吗?B
A. 不会,会全部现算,不会改写
B. 不会,查询会union base表新分区的查询与物化视图的查询结果返回
C. 会,查询会基于物化视图返回结果
默认情况下,物化视图的改写前提是保证查询的结果正确性。在分区物化视图中,可以通过union改写来将base表数据与物化视图数据进行整合,最大程度复用物化视图的结果。
13. 如果非分区的base表更新非常频繁,但又想利用物化视图提高并发,该怎么办?B
A. 没办法,更新非常频繁的base表会导致物化视图数据过期
B. 设置stale rewrite,在牺牲一部分数据实效性的情况下提高并发
 竞猜得奖名单
竞猜得奖名单
第一名(三位)
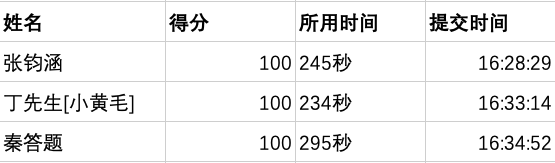
第二名(五位)
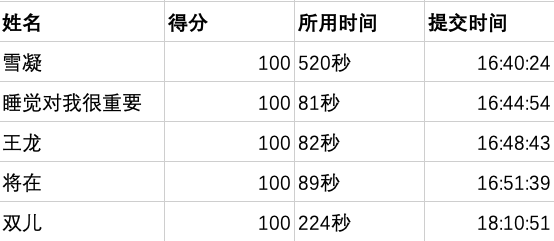
第三名(五位)
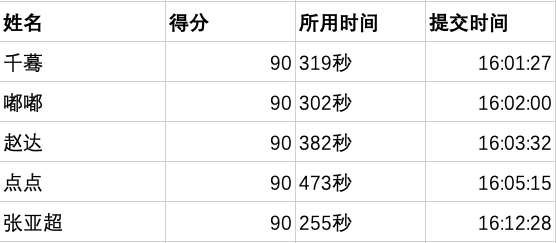
恭喜这几位小伙伴 欢迎后台加小助手领奖~
欢迎后台加小助手领奖~
