背景
需要利用StarRocks1.19.0以及之后版本的Primary Key模型
本文阐述json数据导入StarRocks,实现insert、update、delete
操作
StarRocks DDL
CREATE TABLE cdc_db.`cdc_table` (
`pk` int(20) NOT NULL COMMENT "",
`col0` varchar(64) REPLACE NULL COMMENT ""
) ENGINE=OLAP
PRIMARY KEY(`pk`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`pk`) BUCKETS 1
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
Stream load
json数据
[
{"pk":1,"col0":"aaca"},
{"pk":2,"col0":"aaba"},
{"pk":3,"col0":"aa4a"},
{"pk":4,"col0":"aa33"},
{"pk":5,"col0":"aaa3"}
]
Upsert
curl -v --location-trusted -u root: -H "format: json" -H "jsonpaths: [\"$.pk\", \"$.col0\"]" -H "strip_outer_array: true" -T json.text http://172.26.194.184:9011/api/cdc_db/cdc_table/_stream_load
Delete
curl -v --location-trusted -u root: -H "format: json" -H "jsonpaths: [\"$.pk\", \"$.col0\"]" -H "strip_outer_array: true" -H "columns:__op='delete'" -T json.text http://172.26.194.184:9011/api/cdc_db/cdc_table/_stream_load
Routine load
Kakfa数据中有标识:upsert 0 或delete 1
{"pk":1,"col0":"aaca","op_type":0}
{"pk":2,"col0":"aaba","op_type":0}
{"pk":3,"col0":"aa4a","op_type":0}
{"pk":1,"col0":"aaca","op_type":1}
{"pk":3,"col0":"aa4a","op_type":1}
CREATE ROUTINE LOAD cdc_db.cdc_task1 ON cdc_table
COLUMNS(pk,col0,__op)
PROPERTIES
(
"desired_concurrent_number"="3",
"max_batch_interval" = "20",
"strict_mode" = "false",
"format" = "json",
"jsonpaths" = "[\"$.data.pk\",\"$.data.col0\",\"$.op_type\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "172.26.92.141:9092",
"kafka_topic" = "cdc-data",
"property.group.id" = "starrocks-group",
"property.client.id" = "starrocks-client",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
Mysql binlog
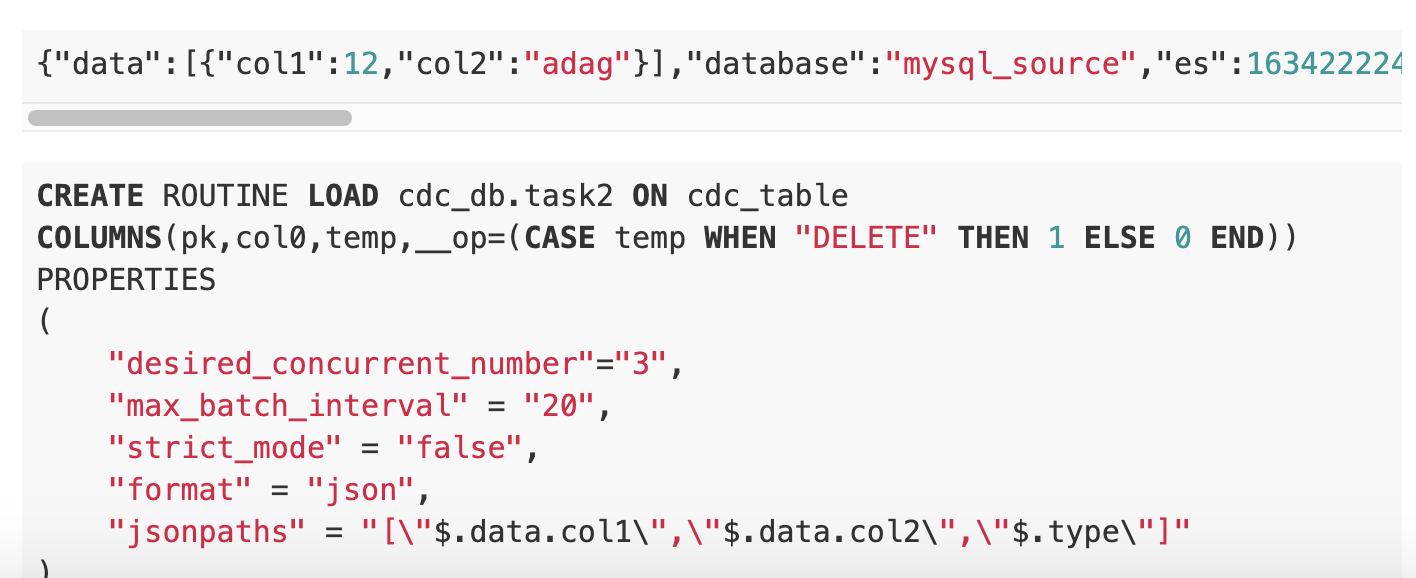
{"data":[{"col1":12,"col2":"adag"}],"database":"mysql_source","es":1634222249000,"id":644,"isDdl":false,"mysqlType":{"col1":"int(20)","col0":"varchar(64)"},"old":[{"col0":"dagdg"}],"pkNames":["host"],"sql":"","sqlType":{"host":12,"collect_time":-5},"table":"query_collect_time","ts":1634222249860,"type":"UPDATE"}
CREATE ROUTINE LOAD cdc_db.task2 ON cdc_table
COLUMNS(pk,col0,temp,__op=(CASE temp WHEN "DELETE" THEN 1 ELSE 0 END))
PROPERTIES
(
"desired_concurrent_number"="3",
"max_batch_interval" = "20",
"strict_mode" = "false",
"format" = "json",
"jsonpaths" = "[\"$.data[0].col1\",\"$.data[0].col2\",\"$.type\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "172.26.92.141:9092",
"kafka_topic" = "mysql-data",
"property.group.id" = "starrocks-group",
"property.client.id" = "starrocks-client",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
如果想到实现json数组的INSERT,可以参考如下方式
{"data":[{"col1":12,"col2":"adag"},{"col1":13,"col2":"adag3"],"database":"mysql_source","es":1634222249000,"id":644,"isDdl":false,"mysqlType":{"col1":"int(20)","col0":"varchar(64)"},"old":[{"col0":"dagdg"}],"pkNames":["host"],"sql":"","sqlType":{"host":12,"collect_time":-5},"table":"query_collect_time","ts":1634222249860,"type":"INSERT"}
CREATE ROUTINE LOAD cdc_db.task3 ON cdc_table
PROPERTIES
(
"desired_concurrent_number"="3",
"max_batch_interval" = "20",
"strict_mode" = "false",
"strip_outer_array" = "true",
"json_root" = "$.data"
)
FROM KAFKA
(
"kafka_broker_list" = "172.26.92.141:9092",
"kafka_topic" = "mysql-data-2",
"property.group.id" = "starrocks-group",
"property.client.id" = "starrocks-client",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
如果想到实现json数组的upsert和delete,需要json数组中有{"__op":0}或者{"__op":1}分别表示upsert和delete
{"data":[{"col1":12,"col2":"adag","__op":0},{"col1":13,"col2":"adag3","__op":1}],"database":"mysql_source","es":1634222249000,"id":644,"isDdl":false,"mysqlType":{"col1":"int(20)","col0":"varchar(64)"},"old":[{"col0":"dagdg"}],"pkNames":["host"],"sql":"","sqlType":{"host":12,"collect_time":-5},"table":"query_collect_time","ts":1634222249860,"type":"UPDATE"}
CREATE ROUTINE LOAD cdc_db.task3 ON cdc_table
PROPERTIES
(
"desired_concurrent_number"="3",
"max_batch_interval" = "20",
"strict_mode" = "false",
"strip_outer_array" = "true",
"json_root" = "$.data"
)
FROM KAFKA
(
"kafka_broker_list" = "172.26.92.141:9092",
"kafka_topic" = "mysql-data-3",
"property.group.id" = "starrocks-group",
"property.client.id" = "starrocks-client",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
Oracle log
注意:当前这种模式没办法支持delete
标准格式

CREATE ROUTINE LOAD cdc_db.task3 ON cdc_table
COLUMNS(pk,col0,temp,__op=(CASE temp WHEN "D" THEN 1 ELSE 0 END))
PROPERTIES
(
"desired_concurrent_number"="3",
"max_batch_interval" = "20",
"strict_mode" = "false",
"format" = "json",
"jsonpaths" = "[\"$.after.ID\",\"$.after.NAME\",\"$.op_type\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "172.26.92.141:9092",
"kafka_topic" = "test_ogg",
"property.group.id" = "starrocks-group",
"property.client.id" = "starrocks-client",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);