
建表的时候设置了分桶键,自动设置分桶数量,分区是按照小时分区,表达式创建分区,为什么刚开始的分区的分桶数都为6,大部分从第六个分区开始就变成1了?
后面自动分桶数是会按照上一个分区的数据量来进行分桶数的设置 ,有什么业务需求是会按照小时分区吗 ?还是为了做测试
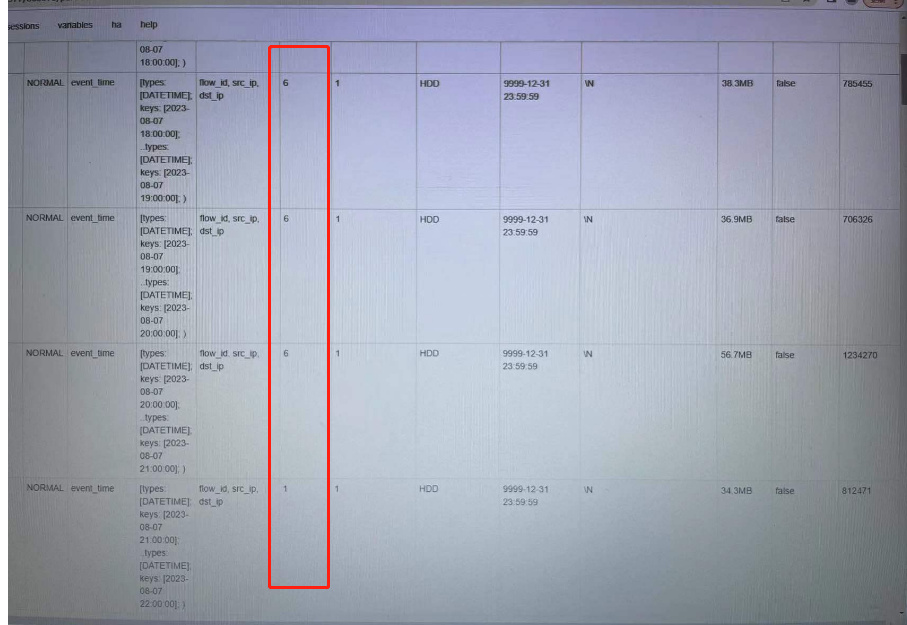
每个分区大概多少数据量? 如果不是实时导入 下一个自动分区创建时不能参考上一个分区的数据量 那么您这个场景不太适用这个场景 需要提前手动创建下分区
这个问题我也好奇,官方文档是这样描述的:“自 2.5.7 版本起, StarRocks 支持根据机器资源和数据量自动设置分区的分桶数量。” 。
设置分桶的数量应该是在DDL阶段完成的,这个时候数据还没有导入, 如何设置呢?
并且如果一个分区最开始导入100GB数据, 然后再导入300GB数据,分桶的数量会变么?
官方原话:“如您的表单个分区原始数据规模预计超过100GB,建议您使用下述方式手动设置分桶数量。”
感觉是如果每个分区的数据都很均衡的话,可以考虑使用自动分桶,毕竟下个分区的分桶数按照上一个分区的数据量来设置,如果数据量会陡增的话,还是建议手动分桶
请问自动确定分桶数的原理是怎样的,它如何确定需要多少个分桶,是有什么根据CPU核数之类的公式吗
大概逻辑就是,刚开始创建的时候是个固定值,比如你集群的be数量,然后动态分区创建几个分区后,根据历史分区的数据量决定新建分区的分桶数。
感谢解答,我找到了相关的patch,提到了详细的逻辑:
核心逻辑的计算函数入口:
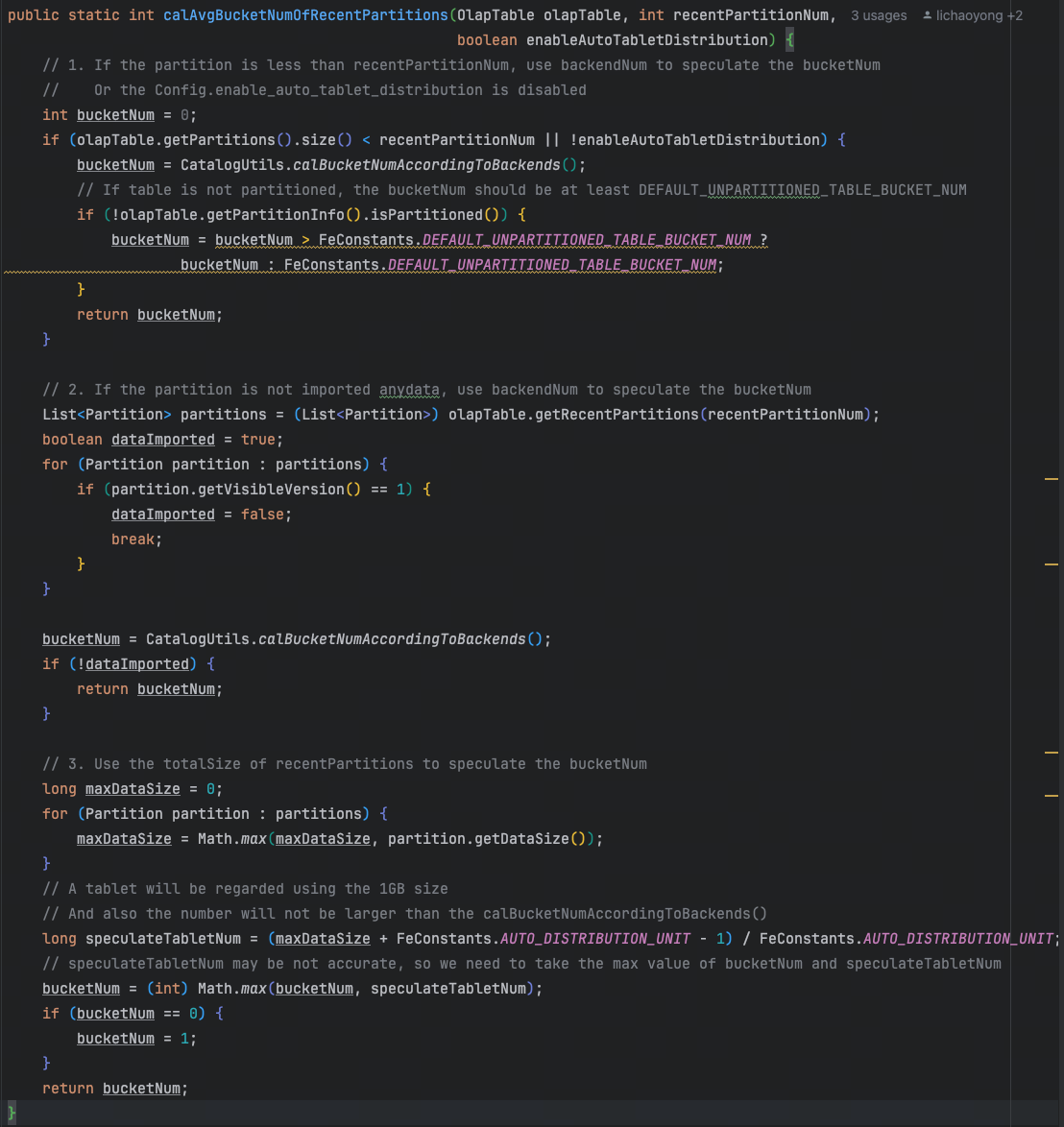
根据数据量决定分桶数的建议:
https://doris.apache.org/zh-CN/docs/table-design/data-partition/#bucket-的数量和数据量的建议
1赞