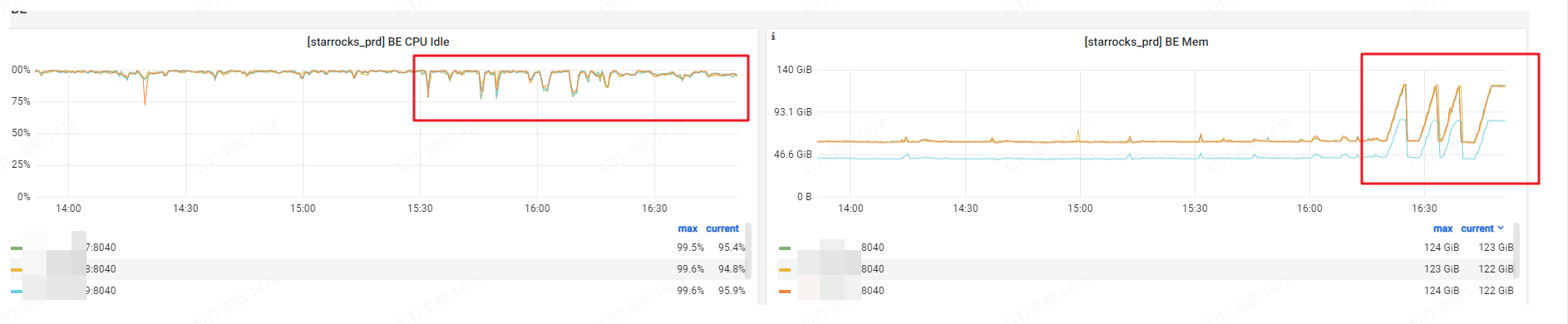
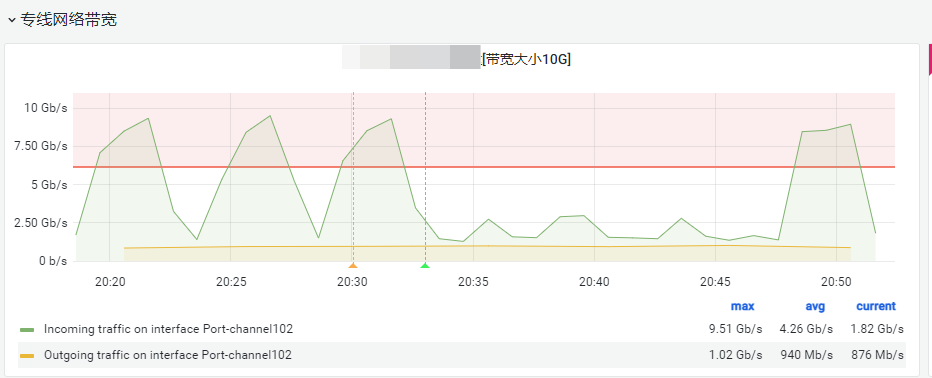
【问题描述】我们目前使用的是seatunnel来进行ETL抽数的(hive_to_starrocks),在2023-08-07 20:18:28 - 2023-08-07 20:52:25这个时间,因为历史数据需要重新初始化,所以有大量的数据需要导入到starrocks(3-4亿),这里带来的问题影响是:我们的hive集群与starrocks集群部署在不同机房,所以大量的数据初始化导致机房之间的带宽被占满(如下监控图)也会导致starrocks集群CPU、内存波动导致集群不稳定。有没有什么好的办法限制这种因为大量的导数从而影响整个集群。我看官方文档中资源隔离是支持<导入计算资源隔离>,但是没有写的很详细,而且貌似还没有支持Stream Load的导入隔离?
【StarRocks版本】2.5.8
【集群规模】3fe+10be(fe与be混部)
【机器信息】:96C/256G/万兆
带宽被占满监控:
starrocks集群CPU、内存:
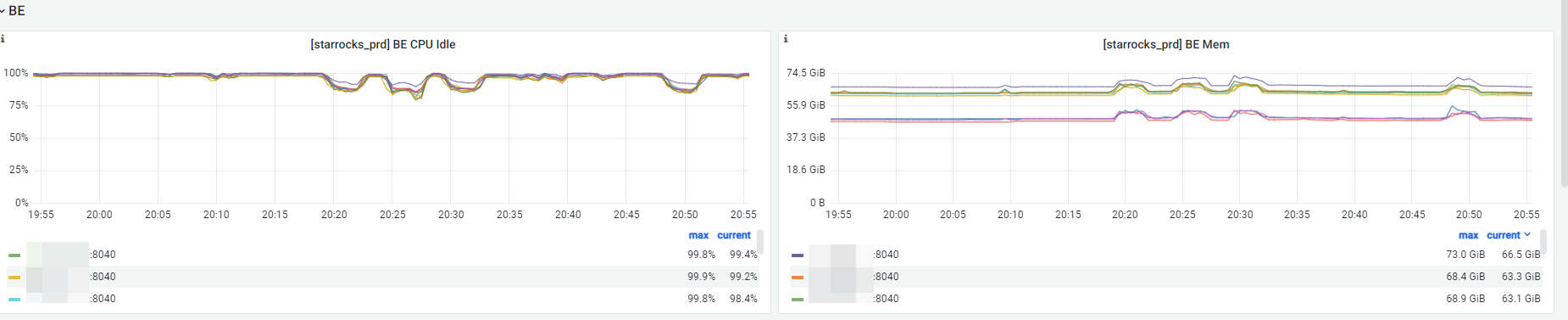
另外我们上个月也是因为导数导致集群的CPU和内存被打爆,官方有没有好的办法避免这种情况?