2023-07-24 14:26:42,385 INFO (leaderCheckpointer|144) [BackupHandler.readFields():673] finished replay 0 backup/store jobs from image
2023-07-24 14:26:42,385 INFO (leaderCheckpointer|144) [BackupHandler.loadBackupHandler():686] finished replay backupHandler from image
2023-07-24 14:26:42,386 INFO (leaderCheckpointer|144) [Auth.loadAuth():1890] finished replay auth from image
2023-07-24 14:26:42,386 INFO (leaderCheckpointer|144) [GlobalTransactionMgr.readFields():711] discard expired transaction state: TransactionState. txn_id: 13404, label: insert_83603d17-daa3-11ed-9f1b-0242ffa99e51, db id: 10002, table id list: 10530, callback id: -1, coordinator: FE: 10.9.2.217, transaction status: VISIBLE, error replicas num: 0, replica ids: , prepare time: 1681463133701, commit time: 1681463133729, finish time: 1681463133743, write cost: 28ms, publish total cost: 14ms, total cost: 42ms, reason: attachment: com.starrocks.transaction.InsertTxnCommitAttachment@45bff2d4
2023-07-24 14:26:42,386 INFO (leaderCheckpointer|144) [GlobalTransactionMgr.readFields():711] discard expired transaction state: TransactionState. txn_id: 13405, label: insert_8368a188-daa3-11ed-9f1b-0242ffa99e51, db id: 10002, table id list: 10530, callback id: -1, coordinator: FE: 10.9.2.217, transaction status: VISIBLE, error replicas num: 0, replica ids: , prepare time: 1681463133757, commit time: 1681463133777, finish time: 1681463133791, write cost: 20ms, publish total cost: 14ms, total cost: 34ms, reason: attachment: com.starrocks.transaction.InsertTxnCommitAttachment@1a2d201a
2023-07-24 14:26:42,386 INFO (leaderCheckpointer|144) [GlobalTransactionMgr.readFields():711] discard expired transaction state: TransactionState. txn_id: 13406, label: insert_836ff489-daa3-11ed-9f1b-0242ffa99e51, db id: 10002, table id list: 10530, callback id: -1, coordinator: FE: 10.9.2.217, transaction status: VISIBLE, error replicas num: 0, replica ids: , prepare time: 1681463133804, commit time: 1681463133825, finish time: 1681463133839, write cost: 21ms, publish total cost: 14ms, total cost: 35ms, reason: attachment: com.starrocks.transaction.InsertTxnCommitAttachment@405aa875
不断打印expired transaction state这个。

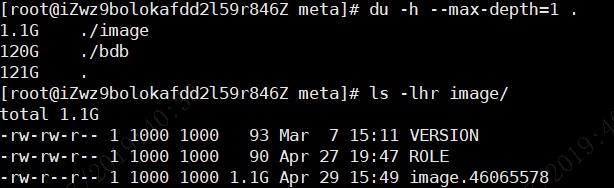
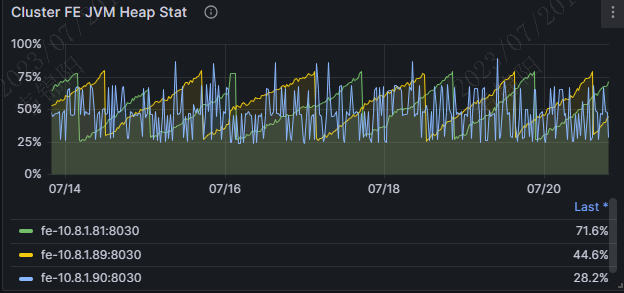

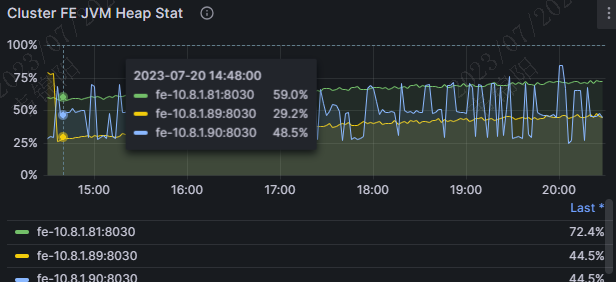
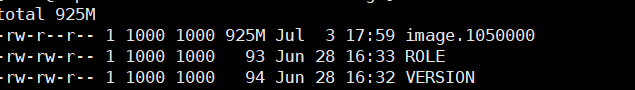 这个另外一个集群的,看了下,我们的所有的集群,image的时间都不是最近的时间。fe的jvm的内存的使用率,一定要在60%一下吗?
这个另外一个集群的,看了下,我们的所有的集群,image的时间都不是最近的时间。fe的jvm的内存的使用率,一定要在60%一下吗?