【详述】flink向sr写数据的时候,一遇到查询时间比较长的,就会报"Message": “call frontend service failed, address=TNetworkAddress(hostname=172.17.60.250, port=9020), reason=THRIFT_EAGAIN (timed out)”
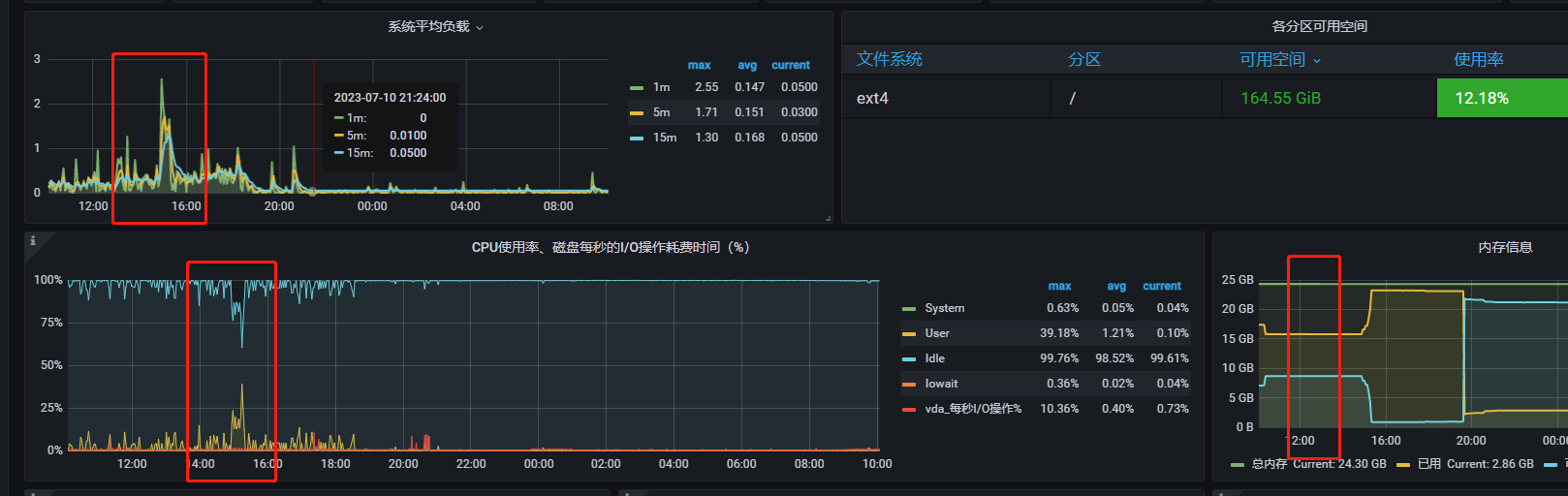
【背景】线上白天有很多查询时间长的sql,造成flink同步任务重启
【业务影响】查询慢,数据同步不稳定
【StarRocks版本】2.4.2
【集群规模】3be+2fe
【机器信息】24C/64G/万兆
【联系方式】社区群8-力
【附件】
fe.log:
2023-07-10 08:45:16,234 WARN (thrift-server-pool-4498|1230676) [FrontendServiceImpl.streamLoadPut():1186] failed to get stream load plan: get database read lock timeout, database=ods
2023-07-10 08:45:17,469 WARN (tablet scheduler|32) [Database.readLock():132] slow read lock db:13323 ods 7269ms
java.lang.Exception: null
at com.starrocks.catalog.Database.readLock(Database.java:132) [starrocks-fe.jar:?]
at com.starrocks.clone.DiskAndTabletLoadReBalancer.getPartitionStats(DiskAndTabletLoadReBalancer.java:1389) [starrocks-fe.jar:?]
at com.starrocks.clone.DiskAndTabletLoadReBalancer.balanceTablet(DiskAndTabletLoadReBalancer.java:1013) [starrocks-fe.jar:?]
at com.starrocks.clone.DiskAndTabletLoadReBalancer.balanceClusterTablet(DiskAndTabletLoadReBalancer.java:949) [starrocks-fe.jar:?]
at com.starrocks.clone.DiskAndTabletLoadReBalancer.selectAlternativeTabletsForCluster(DiskAndTabletLoadReBalancer.java:78) [starrocks-fe.jar:?]
at com.starrocks.clone.Rebalancer.selectAlternativeTablets(Rebalancer.java:63) [starrocks-fe.jar:?]
at com.starrocks.clone.TabletScheduler.selectTabletsForBalance(TabletScheduler.java:1260) [starrocks-fe.jar:?]
at com.starrocks.clone.TabletScheduler.runAfterCatalogReady(TabletScheduler.java:374) [starrocks-fe.jar:?]
at com.starrocks.common.util.LeaderDaemon.runOneCycle(LeaderDaemon.java:60) [starrocks-fe.jar:?]
at com.starrocks.common.util.Daemon.run(Daemon.java:115) [starrocks-fe.jar:?]
2023-07-10 08:45:17,470 WARN (tablet scheduler|32) [TabletScheduler.runAfterCatalogReady():377] select balance tablets cost too much time: 7 seconds
2023-07-10 08:45:51,776 WARN (thrift-server-pool-4432|1230438) [FrontendServiceImpl.streamLoadPut():1186] failed to get stream load plan: get database read lock timeout, database=ods
2023-07-10 08:45:56,351 WARN (starrocks-mysql-nio-pool-81141|1238371) [Database.readLock():132] slow read lock db:13323 ods 7144ms
java.lang.Exception: null
at com.starrocks.catalog.Database.readLock(Database.java:132) ~[starrocks-fe.jar:?]
at com.starrocks.sql.StatementPlanner
flink 任务:
java.lang.RuntimeException: com.starrocks.data.load.stream.exception.StreamLoadFailException: {
“TxnId”: 17338016,
“Label”: “3005ee92-16f3-4aa8-8570-111d352ff062”,
“Status”: “Fail”,
“Message”: “call frontend service failed, address=TNetworkAddress(hostname=172.17.60.250, port=9020), reason=THRIFT_EAGAIN (timed out)”,
“NumberTotalRows”: 0,
“NumberLoadedRows”: 0,
“NumberFilteredRows”: 0,
“NumberUnselectedRows”: 0,
“LoadBytes”: 0,
“LoadTimeMs”: 0,
“BeginTxnTimeMs”: 0,
“StreamLoadPlanTimeMs”: 0,
“ReadDataTimeMs”: 0,
“WriteDataTimeMs”: 0,
“CommitAndPublishTimeMs”: 0
}
审计日志:
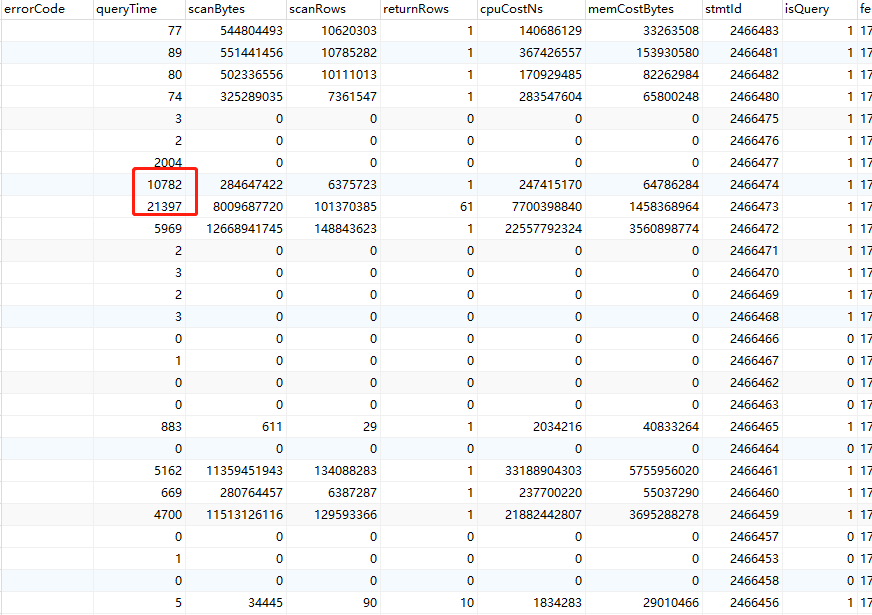
增加 增加observer节点可以分散查询压力吗,还是observer 也会去查leader 元数据,增加observer也不能缓解这个问题
flink 同步的doris 表模式:
) ENGINE=OLAP
PRIMARY KEY(ID)
COMMENT “OLAP”
DISTRIBUTED BY HASH(ID) BUCKETS 16
PROPERTIES (
“replication_num” = “3”,
“in_memory” = “false”,
“storage_format” = “DEFAULT”,
“enable_persistent_index” = “false”