
【详述】table1表中createTime作为第一个sort key,类型datetime(timestamp)
当我执行以下语句,order by 是asc时,大概0.1s。
SELECT * FROM table1 WHERE createTime >= ‘2023-07-01 00:00:00.0’ AND createTime <= ‘2023-07-03 23:59:59.0’ ORDER BY createTime ASC LIMIT 10;
但是,同样的查询,改成desc,却花了大概12s。
SELECT * FROM table1 WHERE createTime >= ‘2023-07-01 00:00:00.0’ AND createTime <= ‘2023-07-03 23:59:59.0’ ORDER BY createTime DESC LIMIT 10;
我查看了profile文件,发现两者读取的数据量相差1000倍左右。
请问这种情况应该如何优化?
我理解,在sort key和前缀索引的前提下,asc limit 10和desc limit 10,读取的数据量应该大概差不多,性能也不应该相差太多。而desc top N的场景在工作中非常常见,如倒序取topN。
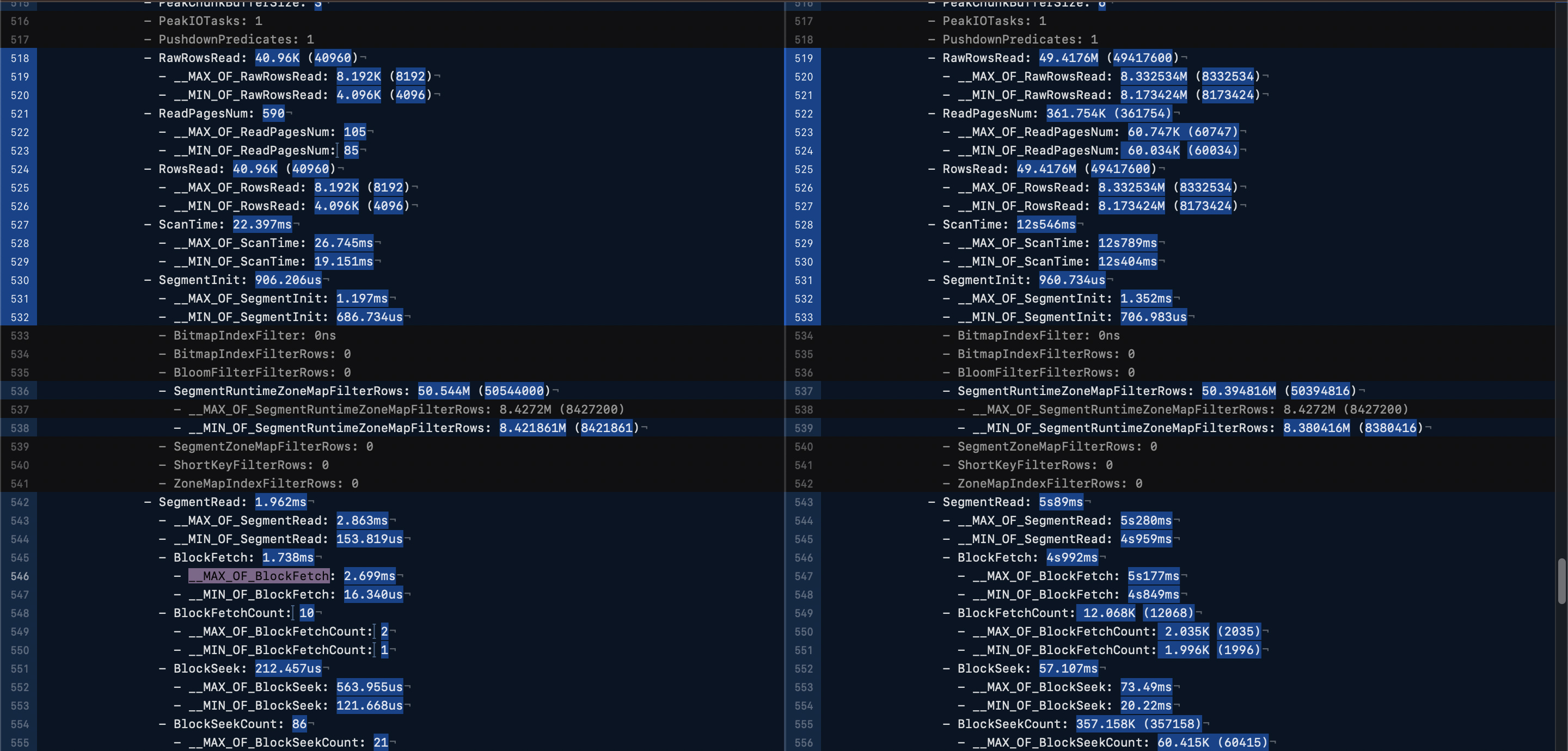
【业务影响】desc top N 场景性能较差
【StarRocks版本】StarRocks version 3.0.3
【集群规模】FE 3 + BE 3
【联系方式】jie zhang(ijavatar@126.com)