【详述】
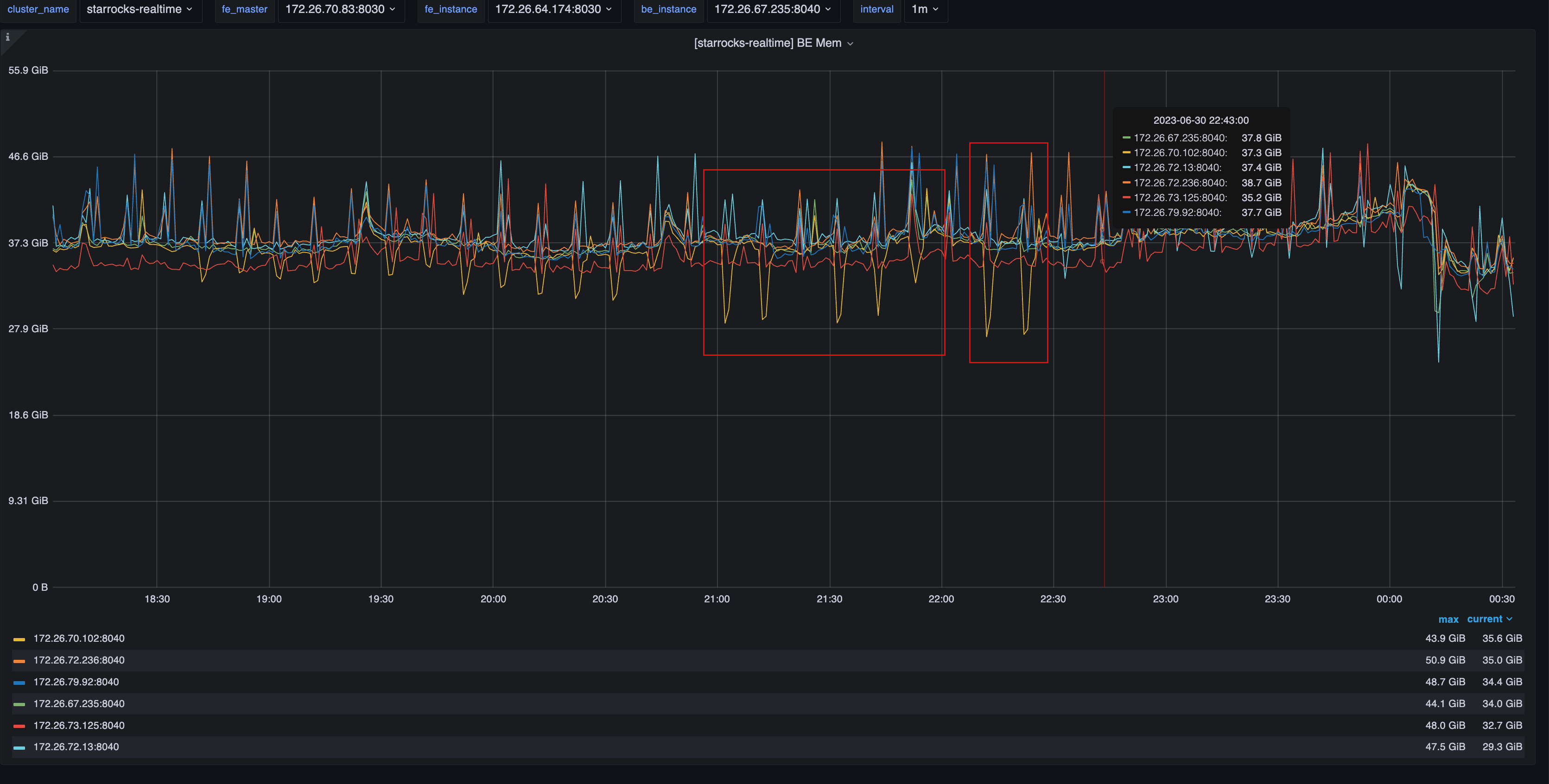
生产环境目前处于资源队列隔离下,隔离情况为如图:

生产业务rg_service2这个资源组的用户有一处调度任务,前后两次调度相隔几分钟,第一次调度总是失败,第二次就能成功。
相关报错信息为:
pymysql.err.ProgrammingError: (1064, 'Memory of Querydd0b349d-1747-11ee-bc78-0632b3434595 exceed limit. Pipeline Backend: 172.26.79.92, fragment: dd0b349d-1747-11ee-bc78-0632b34345a7 Used: 14591199497, Limit: 14589934560. Mem usage has exceed the limit of single query, You can change the limit by set session variable exec_mem_limit or query_mem_limit.')刚开始以为是单个sql的内存超限,调整为18G后依然出错:
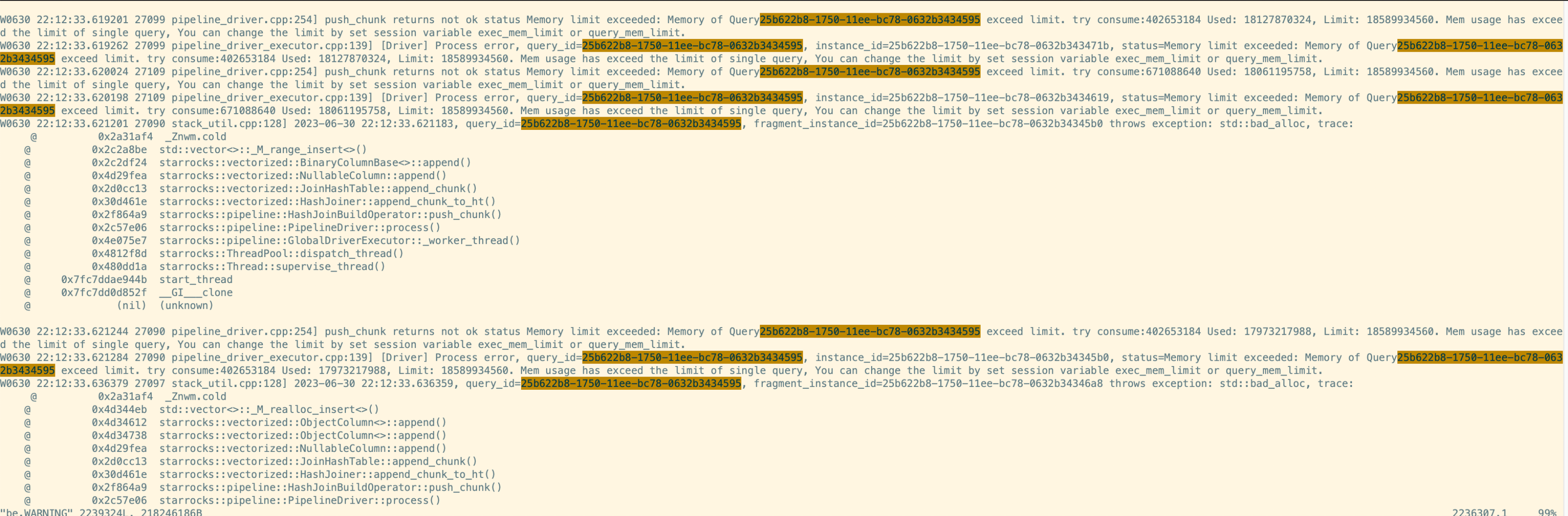
pymysql.err.ProgrammingError: (1064, 'Memory of Query25b622b8-1750-11ee-bc78-0632b3434595 exceed limit. try consume:402653184 Used: 18127870324, Limit: 18589934560. Mem usage has exceed the limit of single query, You can change the limit by set session variable exec_mem_limit or query_mem_limit.')后续排查该调度SQL成功后的审计日志得知,该SQL运行7秒左右,开销内存资源仅6G左右。
失败审计:
成功后审计:
查看相关be后台日志:
问题总结:
相同的SQL,前后两次不同时间的调度一个失败一个却成功,暴露这种奇怪的内存超限的问题。
可以明确的是,原因根本不像是报错中表达了,单个sql开销太大导致超出了资源队列的限制的问题。
因此原因很不解,且无头绪。
【StarRocks版本】2.5.3
【集群规模】例如:3fe+6be
【机器信息】fe:8c 32G、 be:32C 128G
【联系方式】15184315094