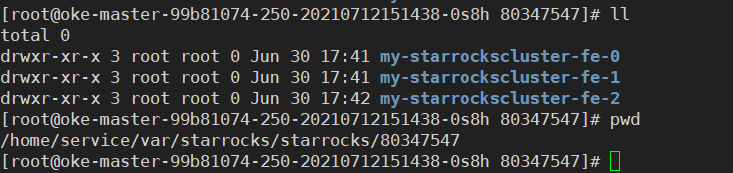
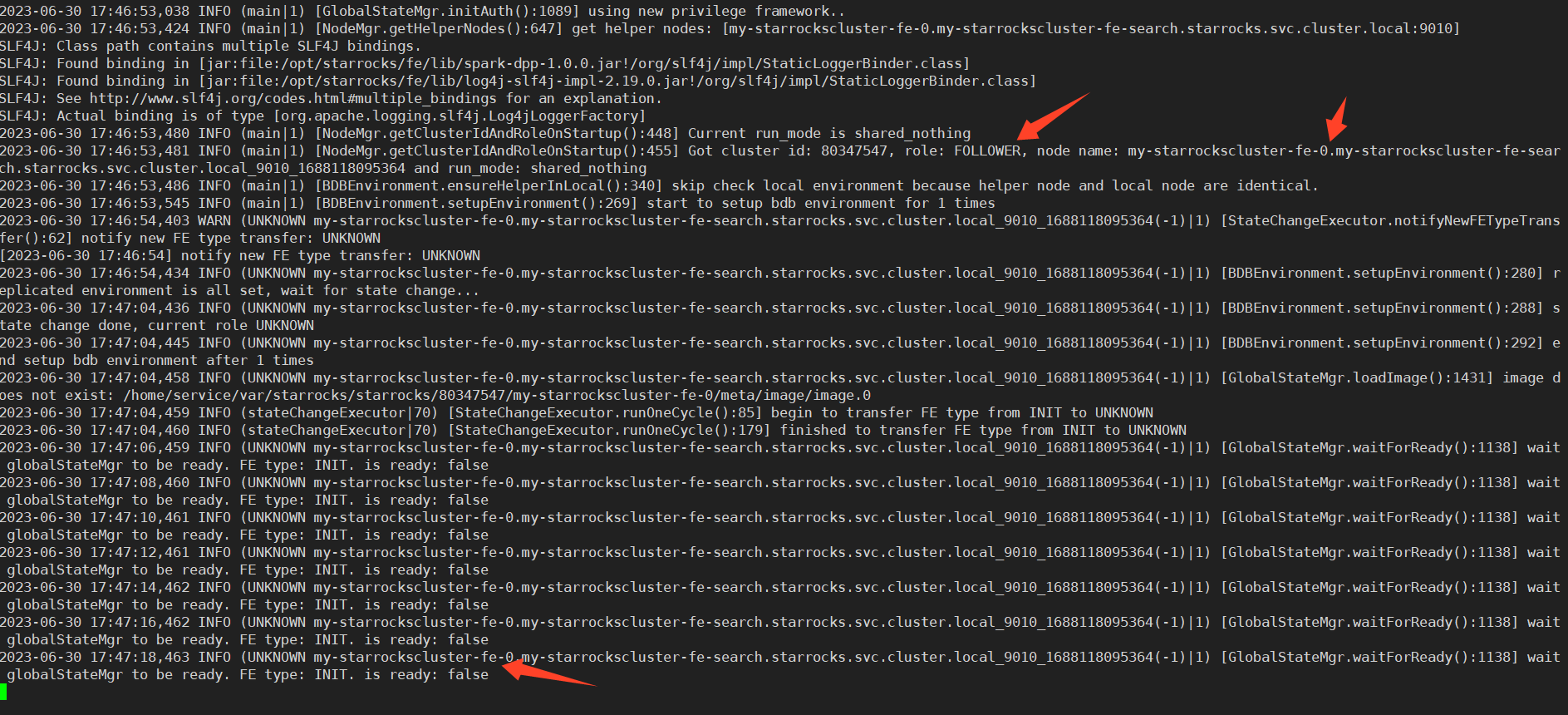
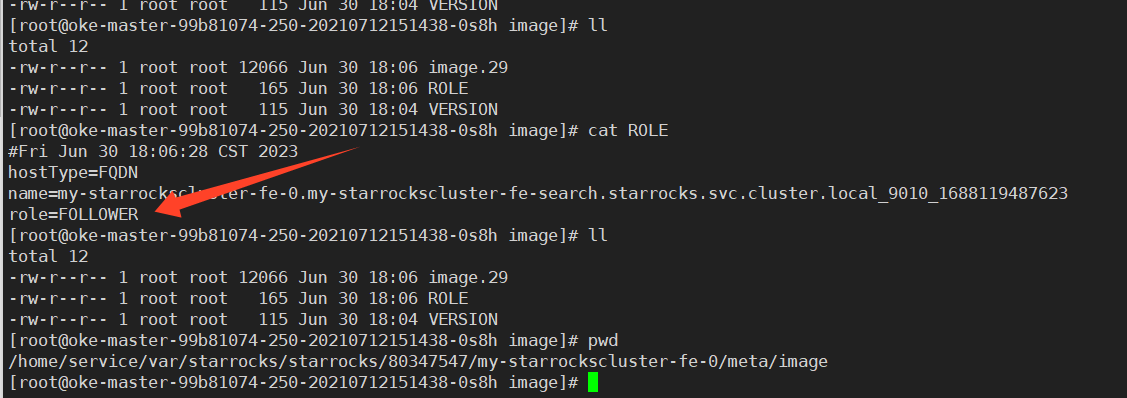
我遇到的问题可能更奇怪些,三个FE节点,都生成自己是 Follower
重现过程
# 部署 StarRocks 集群,三节点。
kubectl apply -f deploy.yaml;
# 删除整个集群环境
kubectl delete -f deploy.yaml;
# 重新部署集群
kubectl apply -f deploy.yaml
关于 deploy.yaml 的特殊之处在于,meta 信息是持久化存储的。下面是一个完整的CRD定义。
apiVersion: starrocks.com/v1
kind: StarRocksCluster
metadata:
labels:
app.kubernetes.io/instance: release-name
app.kubernetes.io/managed-by: Helm
cluster: kube-starrocks
name: kube-starrocks
namespace: starrocks
spec:
starRocksBeSpec:
annotations:
app.starrocks.io/be-config-hash: 951886d3
configMapInfo:
configMapName: kube-starrocks-be-cm
resolveKey: be.conf
configMaps:
- mountPath: /etc/my-configmap
name: my-configmap
fsGroup: 0
image: starrocks/be-ubuntu:2.5.4
limits:
cpu: 1
memory: 2Gi
replicas: 1
requests:
cpu: 1
memory: 2Gi
service:
type: ClusterIP
storageVolumes:
- mountPath: /var/core-dir
name: core
storageSize: 10Gi
starRocksFeSpec:
annotations:
app.starrocks.io/fe-config-hash: 7c889e00
configMapInfo:
configMapName: kube-starrocks-fe-cm
resolveKey: fe.conf
configMaps:
- mountPath: /etc/my-configmap
name: my-configmap
fsGroup: 0
image: starrocks/fe-ubuntu:2.5.4
limits:
cpu: 8
memory: 8Gi
replicas: 3
requests:
cpu: 100m
memory: 300Mi
service:
type: ClusterIP
storageVolumes:
- mountPath: /opt/starrocks/fe/meta
name: meta
storageSize: 2Gi
问题排查
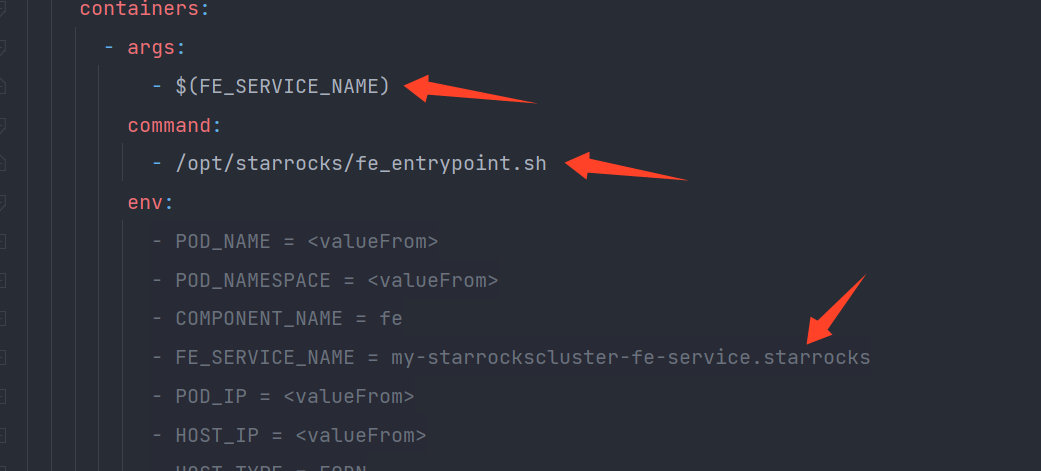
通过查看 fe_entrypoint.sh 脚本可知:probe leader 的方式有两种,如果是0号pod,则执行 probe_leader_for_pod0 ,否则执行 probe_leader_for_podX。
启动顺序:/opt/starrocks/fe_entrypoint.sh --> /opt/starrocks/fe/bin/start_fe.sh --> /lib/jvm/default-java/bin/java
update_conf_from_configmap
collect_env_info
probe_leader $svc_name # 先执行probe_leader,再调用 /opt/starrocks/fe/bin/start_fe.sh 启动FE
start_fe $svc_name
probe_leader()
{
local svc=$1
# find leader under current service and set to FE_LEADER
if [[ "$POD_INDEX" -eq 0 ]] ; then
probe_leader_for_pod0 $svc
else
probe_leader_for_podX $svc
fi
}
probe_leader_for_pod0()
{
# possible to have no result at all, because myself is the first FE instance in the cluster
local svc=$1
local start=`date +%s`
local has_member=false
local memlist=
while true
do
memlist=`show_frontends $svc`
local leader=`echo "$memlist" | grep '\<LEADER\>' | awk '{print $2}'`
if [[ "x$leader" != "x" ]] ; then
# has leader, done
log_stderr "Find leader: $leader!"
FE_LEADER=$leader
return 0
fi
if [[ "x$memlist" != "x" ]] ; then
# has memberlist ever before
has_member=true
fi
# no leader yet, check if needs timeout and quit
log_stderr "No leader yet, has_member: $has_member ..."
local timeout=$PROBE_LEADER_POD0_TIMEOUT
if $has_member ; then
# set timeout to the same as PODX since there are other members
timeout=$PROBE_LEADER_PODX_TIMEOUT
fi
local now=`date +%s`
let "expire=start+timeout"
if [[ $expire -le $now ]] ; then
if $has_member ; then
log_stderr "Timed out, abort!"
exit 1
else
log_stderr "Timed out, no members detected ever, assume myself is the first node .."
# empty FE_LEADER
FE_LEADER=""
return 0
fi
fi
sleep $PROBE_INTERVAL
done
}
probe_leader_for_podX()
{
# wait until find a leader or timeout
local svc=$1
local start=`date +%s`
while true
do
local leader=`show_frontends $svc | grep '\<LEADER\>' | awk '{print $2}'`
if [[ "x$leader" != "x" ]] ; then
# has leader, done
log_stderr "Find leader: $leader!"
FE_LEADER=$leader
return 0
fi
# no leader yet, check if needs timeout and quit
log_stderr "No leader yet ..."
local now=`date +%s`
let "expire=start+PROBE_LEADER_PODX_TIMEOUT"
if [[ $expire -le $now ]] ; then
log_stderr "Timed out, abort!"
exit 1
fi
sleep $PROBE_INTERVAL
done
}
show_frontends()
{
local svc=$1
# ensure `mysql` command can be ended with 15 seconds
# "show frontends" query will hang when there is no leader yet in the cluster
timeout 15 mysql --connect-timeout 2 -h $svc -P $QUERY_PORT -u root --skip-column-names --batch -e 'show frontends;'
}
总结如下:
- 如果是 0 号 Pod(probe_leader_for_pod0),探测不到 Leader,仍然会调用
start_fe.sh 来启动 fe。
- 如果是非0号Pod(probe_leader_for_podX),如果探测不到 Leader,则会直接退出!!(exit 1)
那么问题来了,切主的时候至少需要两个FE节点,造成FE处于不可用状态。
临时解决办法:
直接修改 Statefulset:
# 1. 修改启动参数。
command:
- /usr/bin/sleep
args:
- infinity
# 2. exec 进 pod 后,执行下面的命令。
# pod0: /opt/starrocks/fe_entrypoint.sh kube-starrocks-fe-service.starrocks &
# 注意:kube-starrocks 是 StarRocksCluster 的CR名称,starrocks 是对应的 namespace
# 其它:/opt/starrocks/fe/bin/start_fe.sh &