
FE checkpoint失败
现象
版本:2.1
-
FE master 报错日志
The information_schema db is not persisted, it is generated in loadCluster when loading image. Its id will increase once the loadCluster is called. If the cluster runs for a long time(3 months for example), its id may be bigger than 10000 ( which is the upper limit of system id), because the loadCluster will be called every time a checkpoint is done. The reason why the information_schema db’s id will be increased maybe there will be many clusters in the system and every cluster will have its own information_schema db. But the cluster has be deprecated in our system, so we just give a fixed id number for every system db or table. -
bdb文件巨大
-
FE master 内存监控

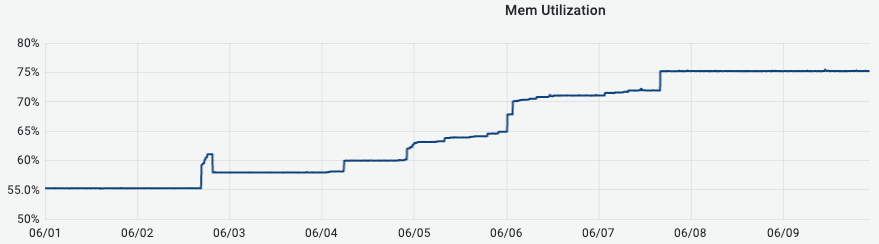
风险
FE 配置 8c32g,bdb文件过大,重启fe存在启动不了的风险
处理方式
- 先给一个follower搞个内存大的机器
- 看看这个follower的启动时间多长,以及占用了多少内存
- 然后占用的内存是机器内存的一半,可以完成正常的checkpoint
- 给这个节点指定成 新的 master
java -jar fe/lib/je-7.3.7.jar DbGroupAdmin -helperHosts {ip:edit_log_port} -groupName PALO_JOURNAL_GROUP -transferMaster -force {node_name} 5000 - 等待checkpoint完成
注意
bdb不能手动删除,需要等待系统自动理清。
但条件是所有fe节点都online状态,如果存在运行不正常的fe,则bdb不会自动删除数据。此时需要主动drop非正常的fe。
待fe都恢复正常后,bdb会减少空间,最后重新加入剔除的fe节点即可。