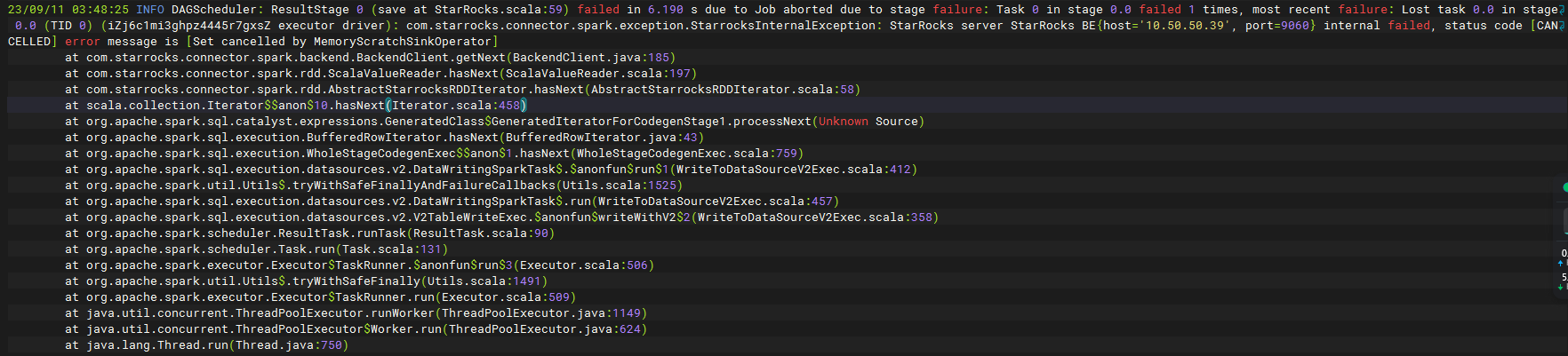
@trueeyu 大佬,重新测试了下,还是不行,测试SR集群版本是2.5.7,spark-connector的版本是1.0,spark的版本是2.4.3,目标读取表的tablet数量是80个,starrocks.request.tablet.size不管是设置成1还是10,都还是报这个错,这个问题什么时候会解决呢,我们现在生产的SR集群想要升级到2.5或者3.0,但是这个问题依旧存在,不敢升级
大约执行多少时间报的错?
那不应该啊,那不是这个问题,BE对应的具体报错也是这个吗?
一模一样的报错,BE上的错也是我之前给的那个日志一样的
是不是和SR版本底层变动相关,我们现在生产用的版本是2.4.3,就没这个问题,之前测试过,升级到2.4.5就碰到这个问题了,然后生产才回退到2.4.3的
2.4.5 指的是Spark版本号?
这个指的是SR集群的版本号,我们spark版本是2.4.5,SR集群之前升级到2.4.5的时候spark通过spark-connector去读取也有碰到这个问题,然后SR回退到2.4.3版本就不会了,starrocks.request.tablet.size这个参数都是设置成1或者10
如线下沟通,query_timeout设置成-1在2.4和2.5上的行为不一致,2.4上使用非pipeline,-1表示永不超时,2.5上使用的pipeline,最终timeout是max(1, query_timeout),也就是变成了1s,很容易就超时被cancel了,所以把timeout调整比较大的正数就可以了
大佬你好,我也遇到这个问题了。
我是为了解决 spark connector 导出starrocks 数据 time out 这个问题,才从2.5.1升级到2.5.8.
升级上来后,立马就出现了异常,观察到读了几万条数据后就挂了。
我的配置是
Spark 3.2.x
Connector 1.0.0
Sparrocks 2.5.8
show global variables like ‘%query_timeout%’; => 300
分区tablet数量 120
starrocks.request.tablet.size=10/1 (都不行)

麻烦问下,这个问题有修复么?我们也遇到了
已确定原因了,还未修复,如果有紧急需求的话,可以联系我先给打一个Patch
是需要修改StarRocks BE还是只需要修改Spark Connector呢?能在最新的版本中修复下么?
需要修改BE,是个内存统计的问题。
会在新版本中修复,基于你的版本给BE打个补丁试下?
我们现在用的v2.5.8,具体怎么操作呢?还有新版本是指在v2.5.12中修复么?
估计要2.5.13版本修复,你要是急需的话,我可以用2.5.8打个补丁,或是2.5.12打个补丁
我们现在临时采用了export方式,不太着急,等v2.5.13发布了,我们再升级吧