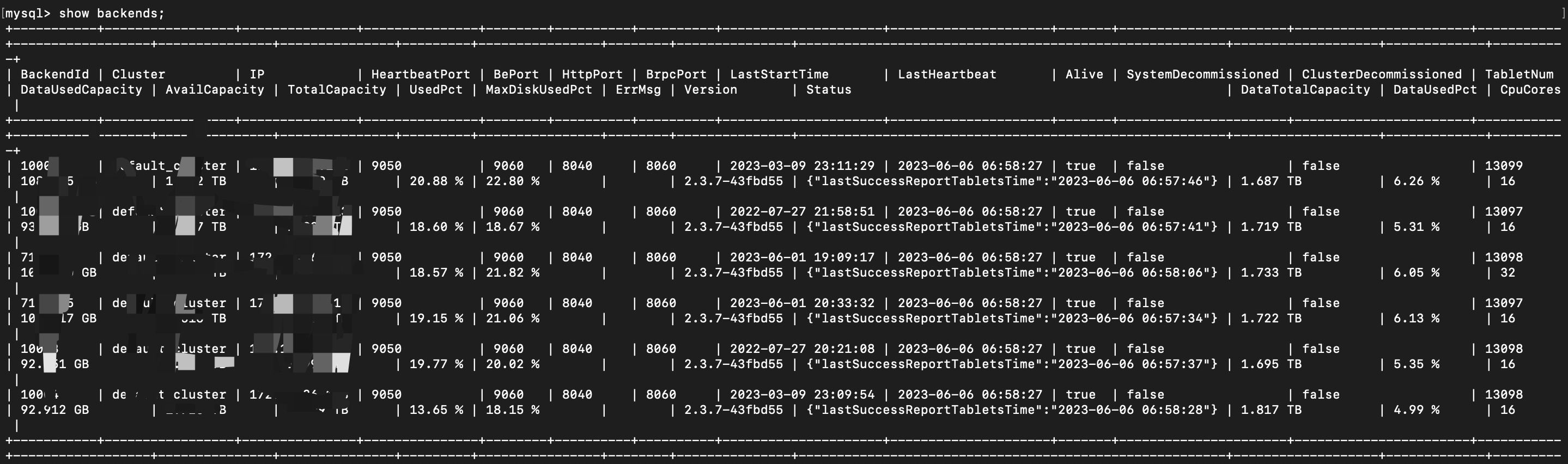
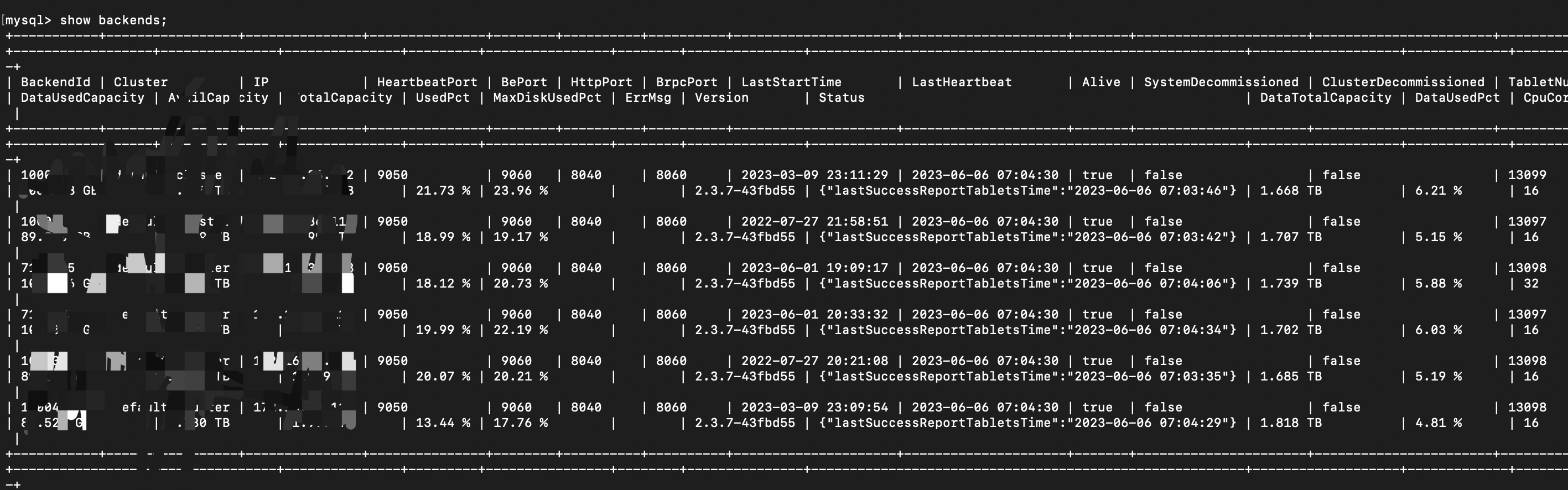
【详述】问题详细描述
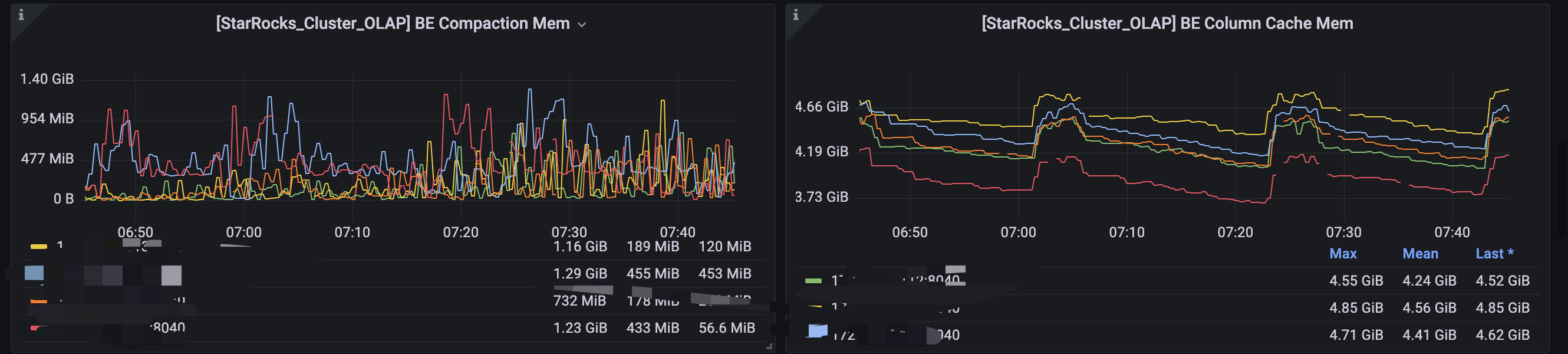
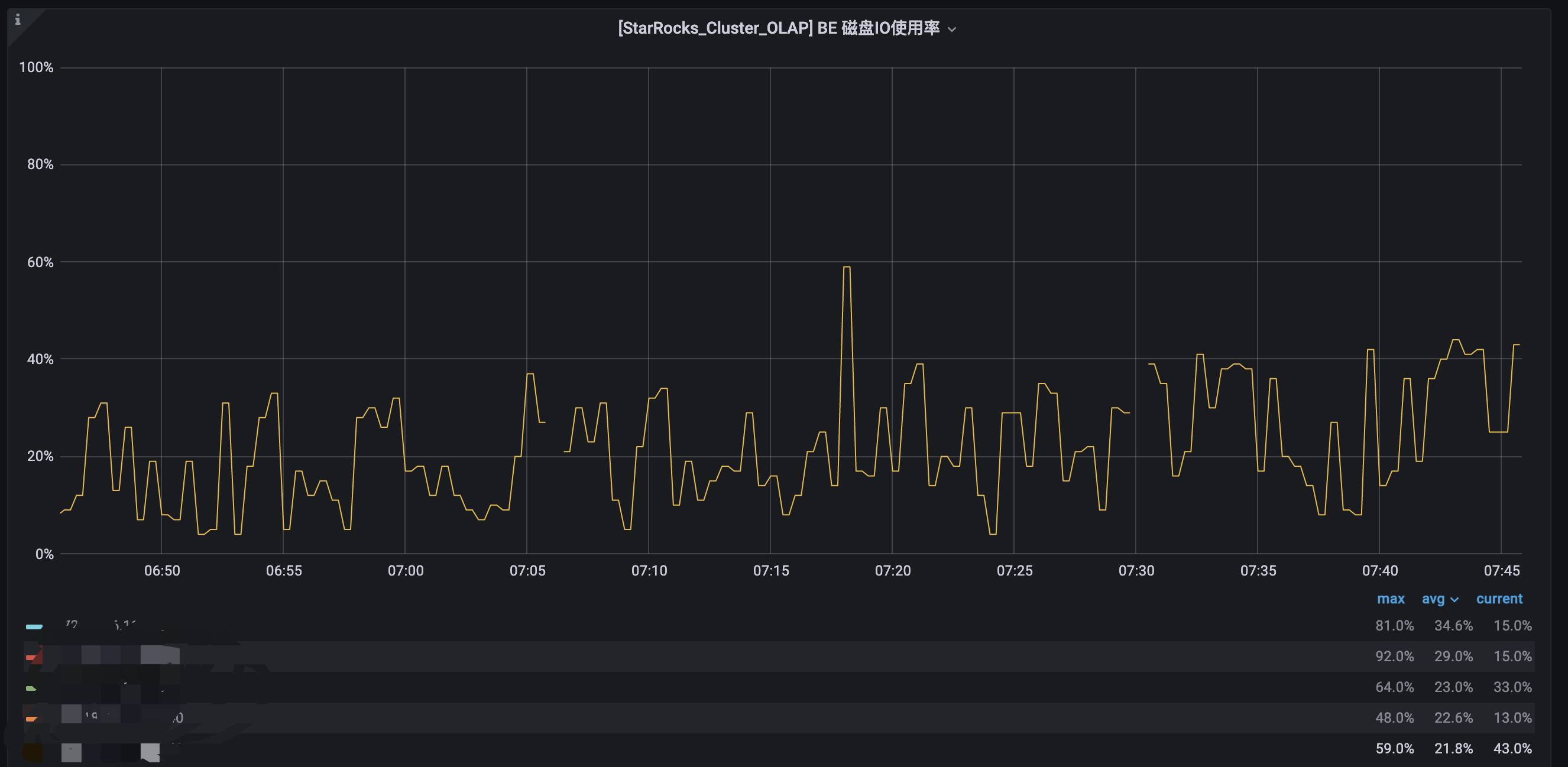
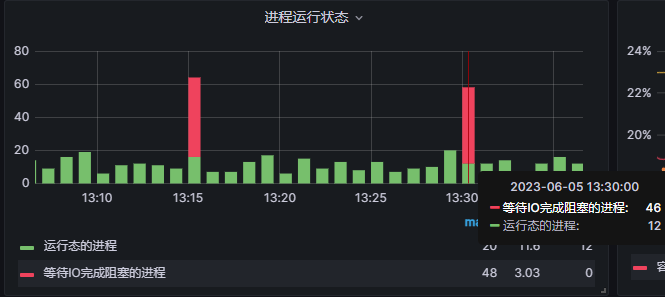
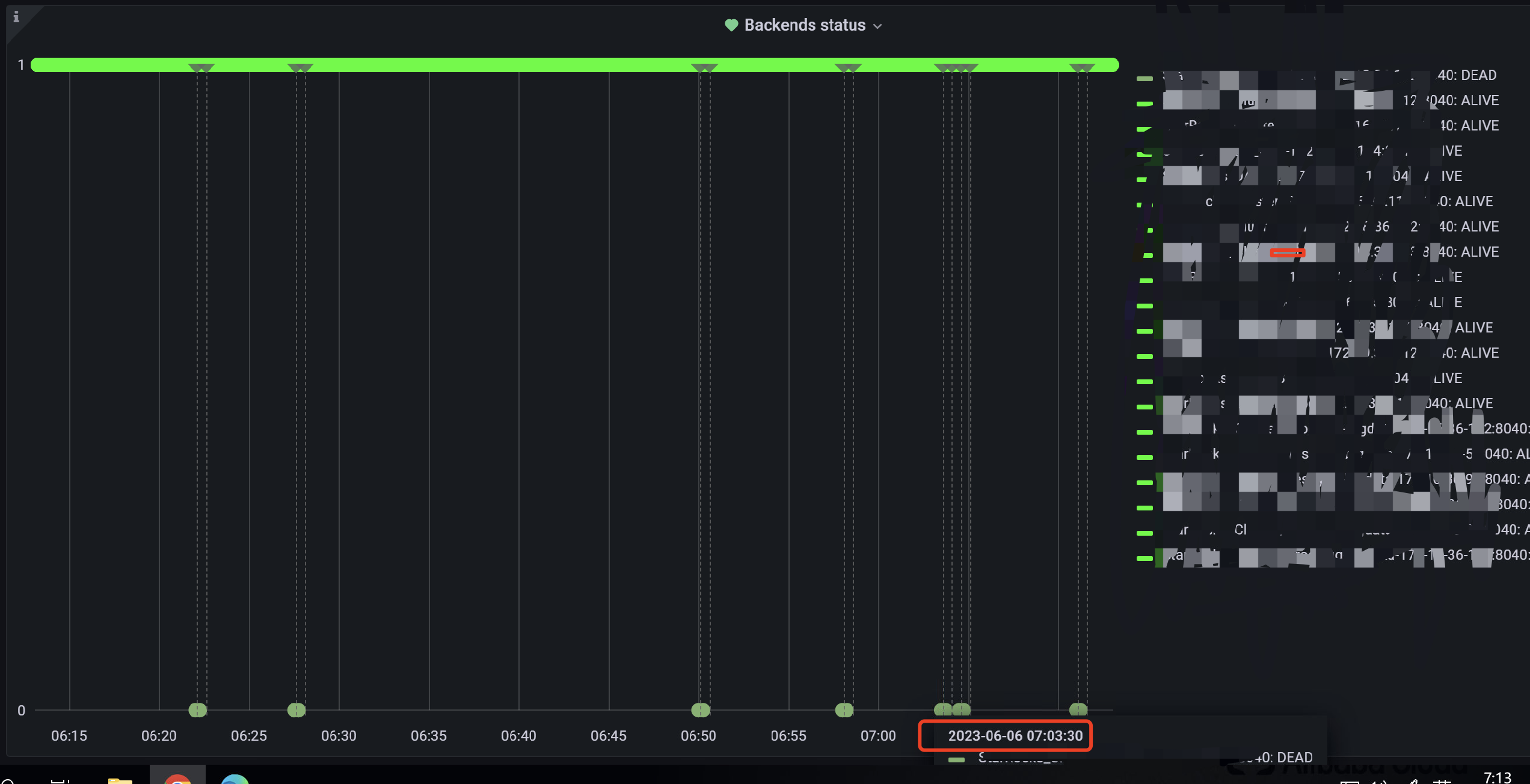
6~7 点BE频繁DEAD,
【背景】做过哪些操作?
6~7点 是导数高峰期,导数方式broker、flink、datax等。
【业务影响】
【StarRocks版本】例如:2.3.7
【集群规模】例如:3fe(1 follower+2observer)+5be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:16C/128G/万兆
【联系方式】
【附件】
- fe.log/beINFO/相应截图
- 慢查询:
- Profile信息,获取Profile,通过Profile分析查询瓶颈
- 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
- pipeline是否开启:show variables like ‘%pipeline%’;
- be节点cpu和内存使用率截图
- 查询报错:
- be crash
- be.out
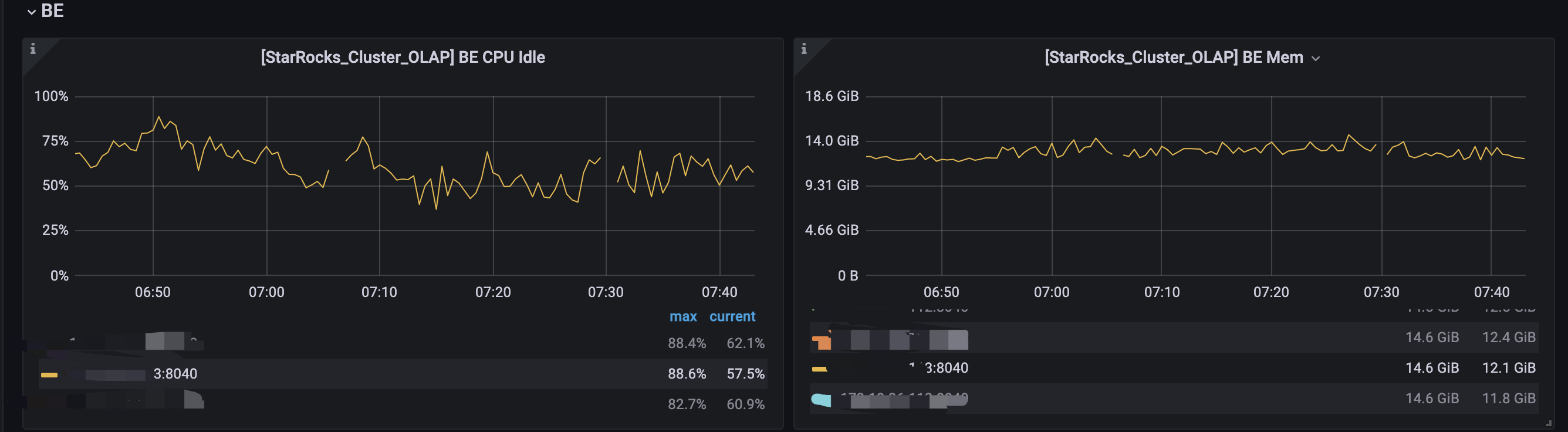
问题描述
2023-06-05T07:30:05 报警出现BE DWON,但是BE并没有DOWN,并且集群出现副本不健康,但是在自动修复。
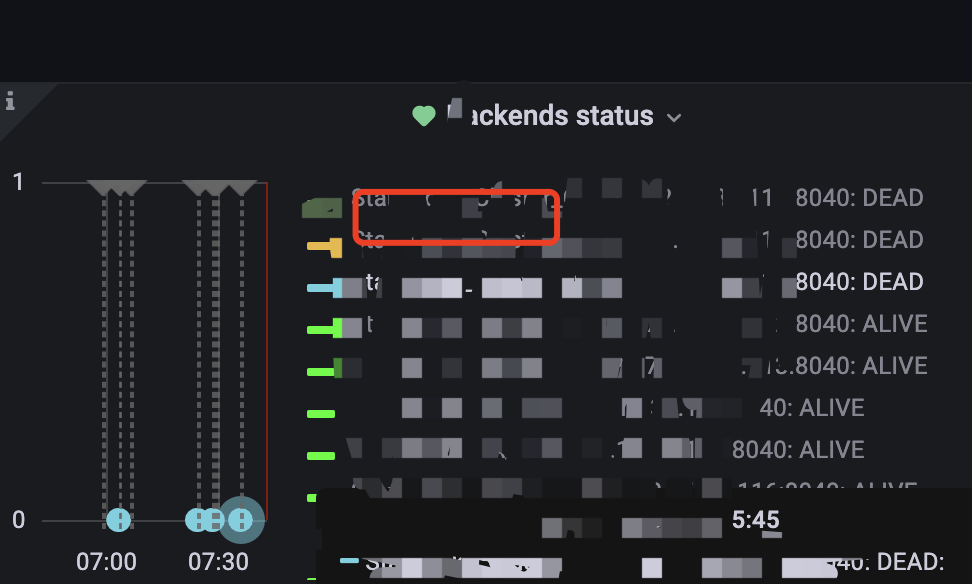
日志如下
be.info:
I0605-be.info (23.4 MB)
be.warn:
I0605-be.warning (95.5 KB)
fe.log:
I0605-fe.log (14.6 MB)
fe.warn.log:
I0605-fe.warn.log.0 (215.9 KB)
其他监控信息: