
0. 业务背景及测试目标
0.0 业务背景
我们目前某个业务正在使用SR 2.5.x版本,目前遇到了两个问题:
i. 由于数据量不断增多,日增1TB(压缩后),以目前的集群规模来看,磁盘预计在2个月内就会用光,然后需要再进行扩容
ii. 业务重度的使用到了部分列更新功能来对不同数据源的数据打宽,以便业务查询能够更快速,目前某表t_1 已经有百亿条数据,在2副本的情况下高峰期IO基本打满,一定程度上会影响业务查询
我们期望使用存算分离的功能来将数据进行冷热分离,降低存储成本,且借助存算分离的功能将导数的任务和业务查询的任务分开,避免不同负载的任务相互影响。由于multi warehouse的功能需要到3.2版本才发布,这次测试暂时只能验证冷热分离后的导数和查询能力是否与存算一体版本保持一致,后期3.2版本出来了再测试multi warehouse的能力。
0.1 测试目标
a. 数据同步能力是否与存算一体版本保持一致
b. sql查询保证兼容
c. 查询性能与存算一体集群相当
d. 3.x 新特性测试 – spill 功能,partial update by column 功能
e. 成本评估,存算分离模式下是否能与存算一体的成本相当或者有所下降
1. 安装部署
SR模式: 存算分离
集群配置:
1 FE (16C 64G)
14 BE (32C 128G NVMe 3.5T * 2)
对象存储: cos
测试SR版本: main-d17f9de
2. ddl 相关
olap 表都改成lake 模式
测试的所有表模型都是Primary Key模型,建表语句需要把 enable_persistence_index改成 false(目前测试版本不支持索引落盘功能), 建表的时候默认使用cache功能,保留30天的数据。
pg外表
使用跟存算一体集群相同的方式建表。
3. 同步任务配置
3.1 离线同步
a. backup 存算一体集群SR 2.5.5的数据到cos,再通过restore 命令恢复local表数据到存算分离3.x 的集群
b. 通过insert into 的方式将 local表的数据导入到cloud native表,用来验证cloud native表的查询性能。
3.2 实时同步
同步链路 kafka -> flink -> sr
| 同步类型 | 任务数 | 表数 | 任务资源 | 数据sink频率 |
|---|---|---|---|---|
| 单表同步 | 23 | 23 | JM 0.25CU (1 Core 4GB Memory) TM 0.25 - 4CU 不等 | 60s / 500w rows / 2GB |
| 部分列更新同步 | 26 | 6 | JM 0.25CU TM 0.25 - 4CU 不等 | 60s / 500w rows / 2GB |
| 总计 | 49 | 29 | 41.5CU | - |
数据量说明:
单表同步的任务中,有5个左右大表日新增或更新数据量在20亿条左右,其余日新增均在1亿条以下。
部分列更新同步的数据中,某表t_1 由七个部分列更新任务进行数据打宽,合并成一张大宽表,3个任务日新增活更新在20亿左右数据,其他4个任务日新增或更新在1-2亿条左右。
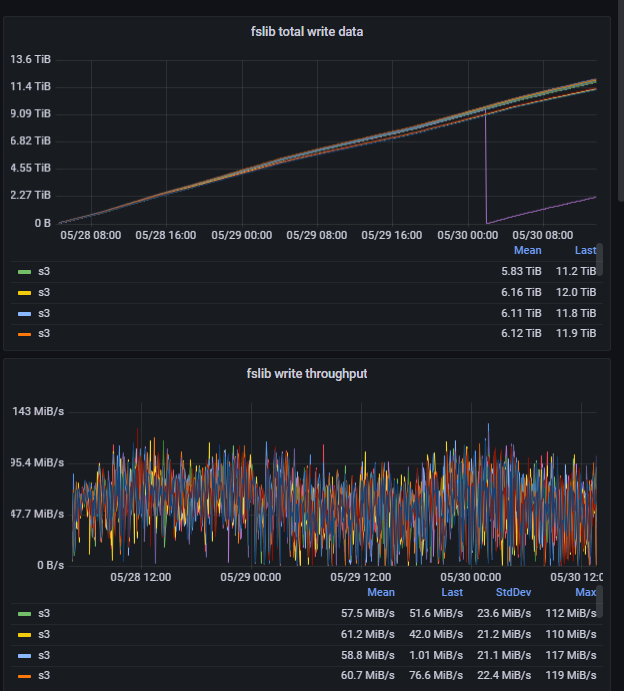
从监控可以看出,两天左右每台be节点导入了11TB以上的数据,单节点最高导数 120MB/s 左右。
从部分列更新表t_1的一个导数任务来看,追历史数据的时候,在 TM 2CU * 2的情况下,可达 11.8 w records/s, 正常情况下,高峰期导数据可达 5w records/s 以上,满足业务对导数性能的需求。
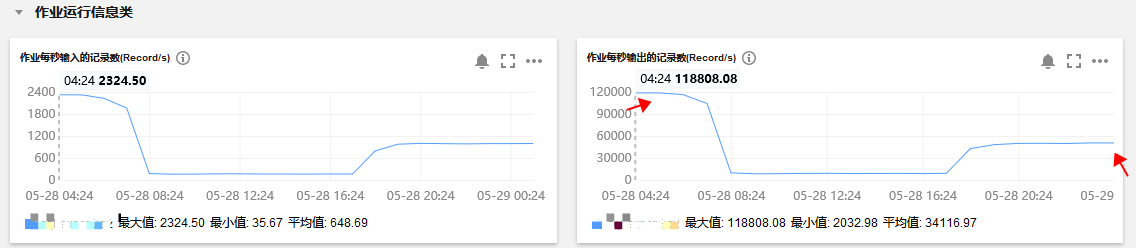
3.3 问题记录
a. 在一开始测试的版本进行实时同步的时候,启动任务数量多了,sink到SR报错: Reduce your request rate.
经与SR同学沟通,写数据的时候需要调用 cos list dir api, 导入的量大之后达到了 cos 的限制 (1000 QPS), 后续经SR的同学优化后导入数据不再需要调用cos list dir api, 重新启动所有的同步链路验证导数据正常。
b. 导入数据膨胀,无法清除历史版本数据
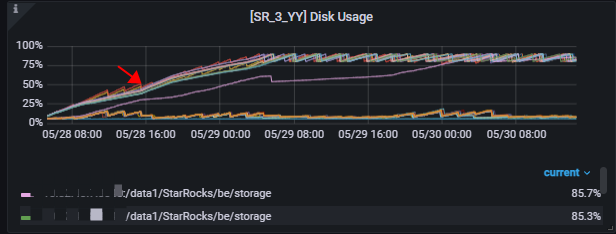
从监控可以看出导入历史数据量不大的时候,还能够正常的gc, 后续存量数据越来越多的情况下,由于cos list api性能的问题,无法正常的进行data gc, 导致历史版本数据无法删除,数据一直增加到磁盘容量的90%,触发cache淘汰才会下降。
与SR的同学沟通后续会优化掉这个问题。
c. 磁盘使用不均
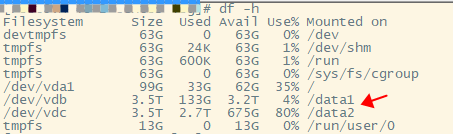
be节点单机配置了两块SSD盘,但是写入不均匀,与SR的同学沟通,目前是按表级别的分配, 所以表容量有倾斜时, 容易造成磁盘容量使用不均,后续将重构到块级别,能有效解决这个问题
4. 业务查询测试
基于离线导数进行测试
表的相关信息如下:
| table_name | 数据条数(select count(1)) | 数据容量 (show data) | 备注 |
|---|---|---|---|
| t_1 | 10217041079 | 682.179 GB | |
| t_2 | 27875463 | 3.845 GB | |
| t_3 | 87418835 | 14.084 GB | |
| t_4 | 179278249 | 23.981 GB | |
| t_5 | 1146 | 2.247 MB | |
| t_6 | - | - | pg 外表 |
| t_7 | - | - | pg 外表 |
cloud native表查询测试结果记录:
测试使用 mysqlslap -h $host -u $user -p $pass -P9030 --create-schema=$db -c 1 --number-of-queries=1 -F “;” -q q_x.sql 命令进行测试, 时间取整轮并发测试执行完的时间,即最慢的sql的执行时长。q_1 至q_6 测试结果如下:
| sql 查询编号 | 1并发 (seconds) | 10并发 (seconds) | 20并发 (seconds) | 50并发 (seconds) |
|---|---|---|---|---|
| q_1_cloud_native | 0.230 | 1.095 | 2.076 | 5.105 |
| q_2_cloud_native | 0.382 | 2.402 | 4.310 | 10.562 |
| q_3_cloud_native | 0.146 | 0.213 | 0.297 | 0.664 |
| q_4_cloud_native | 0.090 | 0.211 | 0.416 | 0.920 |
| q_5_cloud_native | 0.166 | 0.680 | 1.166 | 2.845 |
| q_6_cloud_native | 0.256 | 未测试 | 未测试 | 未测试 |
5. ETL 大查询测试
5.1 spill 测试
| table_name | 数据条数(select count(1)) | 数据容量 (show data) | 备注 |
|---|---|---|---|
| t_8 | 53705944649 | 2.816 TB |
观察监控可以看出,spill 模式下没有出现内存打爆的情况,能够充分的利用CPU及磁盘将大查询稳定执行完 。
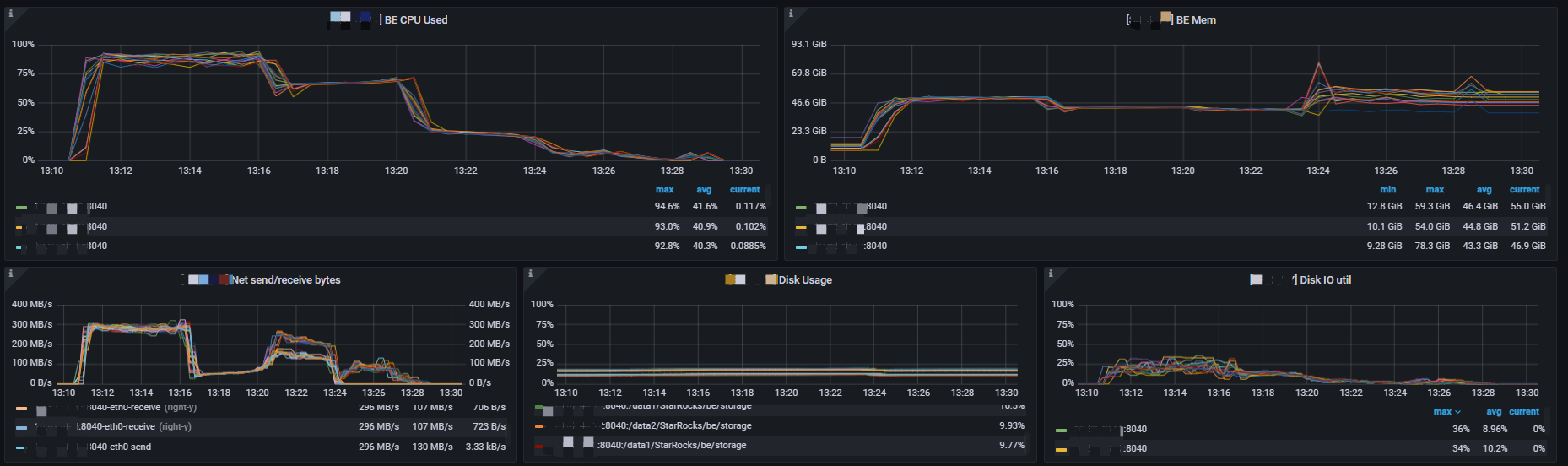
跑了793.4 s后通过这个sql生成了 3775753587 条数据。
5.2 partial update by column 测试
由于cloud native 表目前不支持parital update by column 功能,该测试基于local表进行
| table_name | 数据条数(select count(1)) | 数据容量 (show data) | 备注 |
|---|---|---|---|
| t_9 | 10217041079 | 682.179 GB | |
| t_10 | 3775753592 | 191.065 GB |
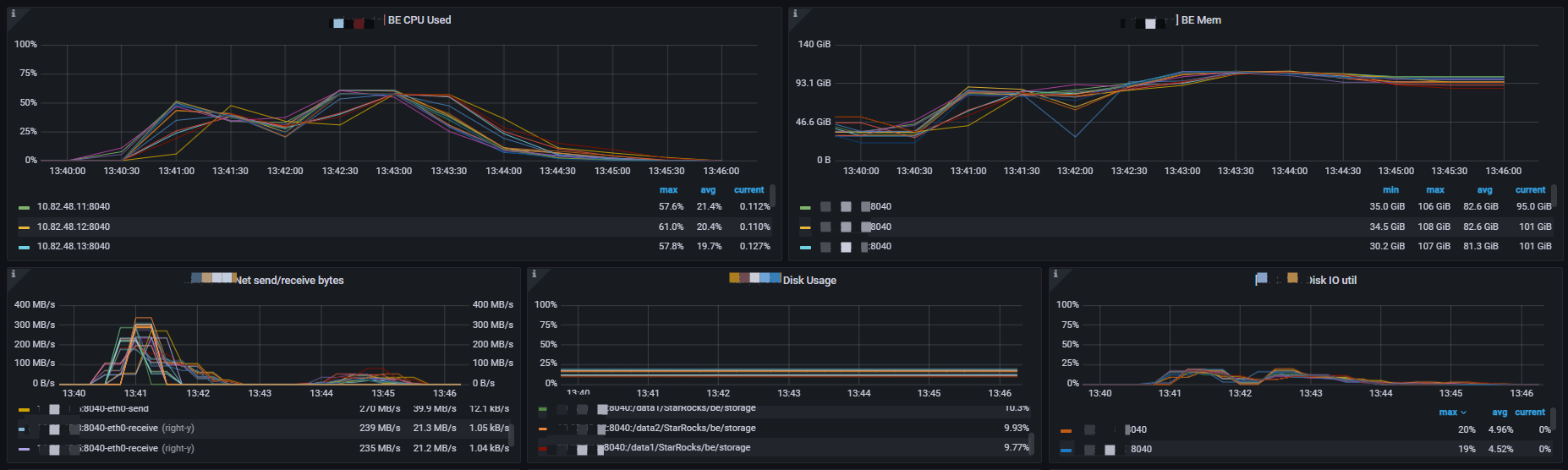
通过fe.audit.log查看,跑了88.14s 跑完了这个sql
5.3 总结
通过上述两个例子可以看出,在3.x 版本可以通过SR来稳定的跑百亿级别数据条数的ETL, 但是跑ETL的时候任需要消耗大量的资源。
6. 对比测试
olap local 表 查询结果
| sql 查询编号 | 1并发 (seconds) | 10并发 (seconds) | 20并发 (seconds) | 50并发 (seconds) |
|---|---|---|---|---|
| q_1_local | 0.663 | 5.168 | 10.091 | 24.567 |
| q_2_local | 0.406 | 2.224 | 3.851 | 10.772 |
| q_3_local | 0.203 | 0.212 | 0.443 | 0.914 |
| q_4_local | 0.092 | 0.140 | 0.347 | 0.402 |
| q_5_local | 0.263 | 0.727 | 1.256 | 3.087 |
olap local 表 vs cloud native表 对比
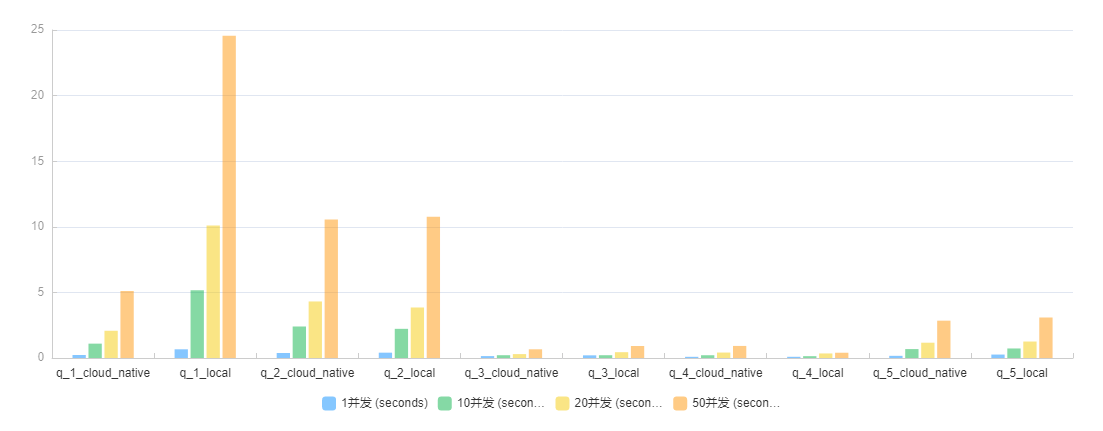
从上面的对比图可以看出,q2 - q5 四个sql, local表与cloud native表的查询性能基本持平,q1 在10并发以上的场景下cloud native表都比local表查询性能要好。
7. 待优化功能
a. 目前测试版本不支持Primary Key 索引落盘,后续版本会支持
b. 目前cache是单机能力, 未来会往多机共享方向演进
c. data gc 优化
d. 数据分布优化到块级别
e. 3.x be 部分metrics 还没兼容,待优化 (starrocks_be_disks_data_used_capacity starrocks_fe_tablet_num)
f. fe.audit.log 中的部分指标为0,待优化 (ScanBytes=0|ScanRows=0|Ret urnRows=0)
8. 总结
| 测试目标 | 测试验证情况 |
|---|---|
| a.数据同步能力是否与存算一体版本保持一致 | 经测试验证,存算分离版本的数据同步能力与存算一体的版本基本一致,但是data gc 这块还有明显的不足,需要继续优化。 |
| b. sql查询是否保证兼容 | 目前测试没有遇到sql不兼容的情况 |
| c. 查询性能是否相当 | 在命中缓存的情况下,cloud native表查询性能跟local表基本相当,cloud native表在复杂查询并发场景下还要由于local表 |
| d. 3.x 新特性测试 spill 功能,partial column update 功能 | spill 及 partial column update 功能验证能正常使用 |
| e. 成本评估,存算分离模式下是否能与存算一体的成本相当或者有所下降 | 从数据同步能力及查询性能来看,存算分离集群和存算一体的效果相当,但是由于data gc目前无法正常完成,导致新增了多余的磁盘利用及cos的成本,暂时来说成本较存算一体集群偏高,这块后续优化后再进行验证一下。 |
9. 思考
对于存算分离模式下,底层的对象存储可以使用AWS S3 的api进行统一访问,但是不同云厂商提供的产品性能有差异,这部分还需要SR的同学努力优化屏蔽掉不同云厂商产品所带来的差异,这样对于用户来说使用起来成本会更低,更加的方便。
对于SR的测试来说,数据量是比较关键的,如果量不够的话,无法发现一些性能瓶颈,后续希望SR的同学能够对新功能加量测试,最好能用TB级别以上的数据量进行测试,这样覆盖面会更全一点。
存算分离模式能有效的处理存储增长和计算增长不匹配的问题,在这种业务场景下,使用存算分离的模式来部署SR能达到降本增效的目标,但是对于某些存储增长和计算增长都比较稳定的旧业务来说,存算一体模式会更好一些。
10. 后续规划
由于目前主键模型存算分离测试的版本还处于早期的阶段,还有许多需要优化及完善的功能,我们近期暂时不会在业务上使用存算分离的模式。但是我们需要使用3.0的spill功能,目前只能通过硬件上的升级-- 纵向扩容(使用32C 128G NVMe SSD 7T *2 的机型) 及横向扩容(按负载增加be节点数)来缓解目前遇到的部分列更新IO消耗大的问题。
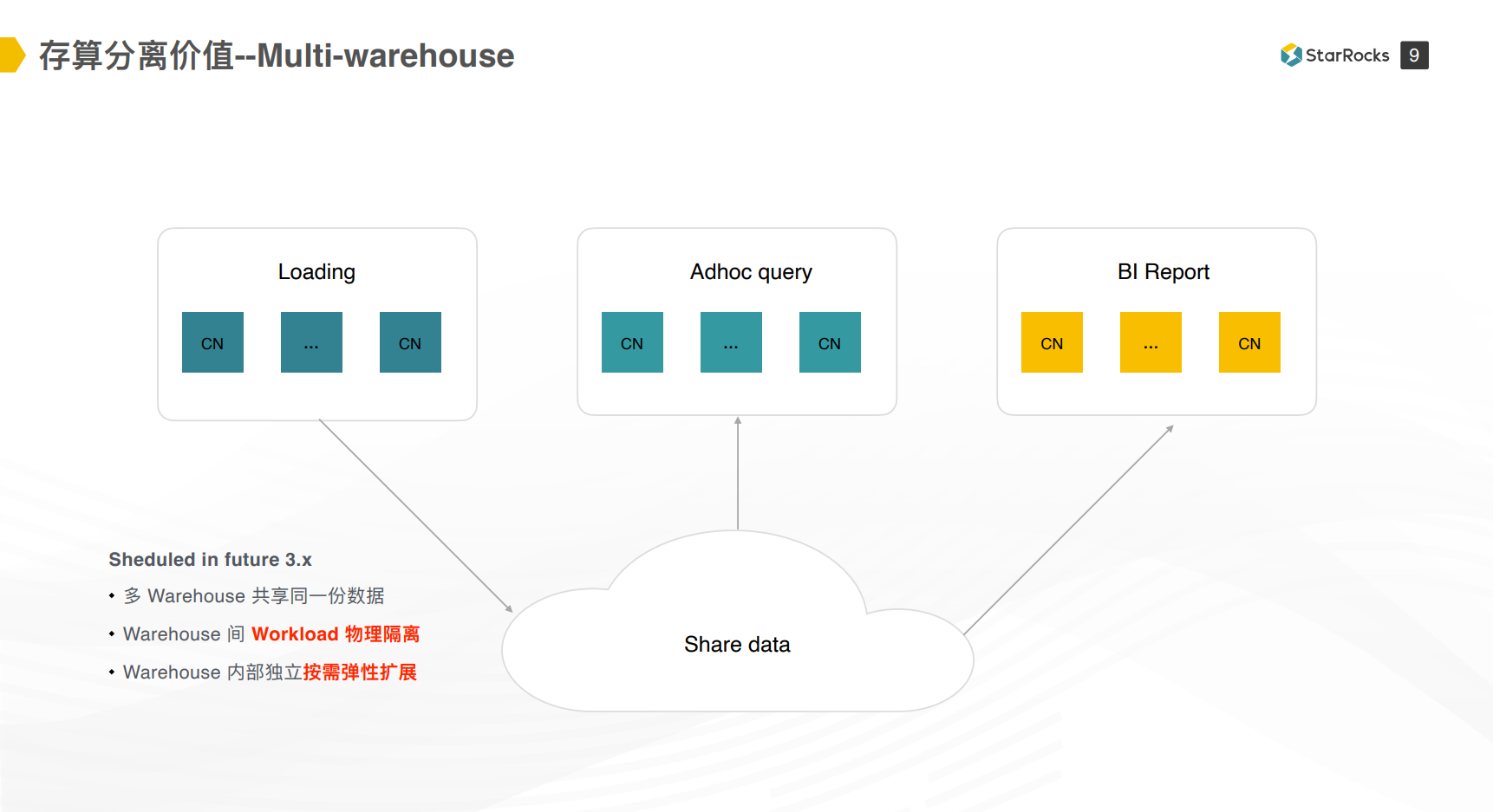
长期来说,我们还是期望能够通过存算分离功能来将不同的负载拆开,将导数任务、业务查询、ETL跑批等不同负载的任务分在不同的warehouse上,不同warehouse间共享一份数据,各个warehouse间按需进行弹性扩展,降低不必要的资源冗余,达到降本增效的目标。
此次测试只验证了部分重要的sql, 还没有对业务sql全面进行覆盖验证,后续等3.2版本出来后我们需要再对业务sql进行回放验证。
最后,感谢SR社区的同学在此次测试当中给予的支持,期望在大家的努力下我们能早日用上稳定的SR存算分离版本,解决业务痛点问题。