
StarRocks 存算分离性能测试报告2023-05-29T16:00:00Z
一、背景
我们公司是一家金融科技公司,主要为金融政企提供数据服务。数据团队负责处理和管理企业的海量数据,为企业的决策提供数据支持。目前,数据团队的工作内容包括数据治理、产业图谱、金融风控和企业信用评分等多个方面。
二、业务场景&平台组件概述
当前业务场景有企业数据治理,企业指标标签画像,企业财务信用评分等。大数据团队自建了cdh6.3.2版本大数据平台。数据仓库hive集成了阿里云jindo sdk,底层使用oss存储海量数据。计算引擎采用spark3.1.2,在spark上层搭建kyuubi网关对spark进行多租户和资源隔离。外部调度系统采用dolphinscheduler分布式调度,数据同步使用datax和seatunnel,主要的计算任务spark sql+udf进行开发,数据同步到elasticsearch给客户查询。即席查询使用trino(原presto)进行数据探查。
原有的大数据平台架构:
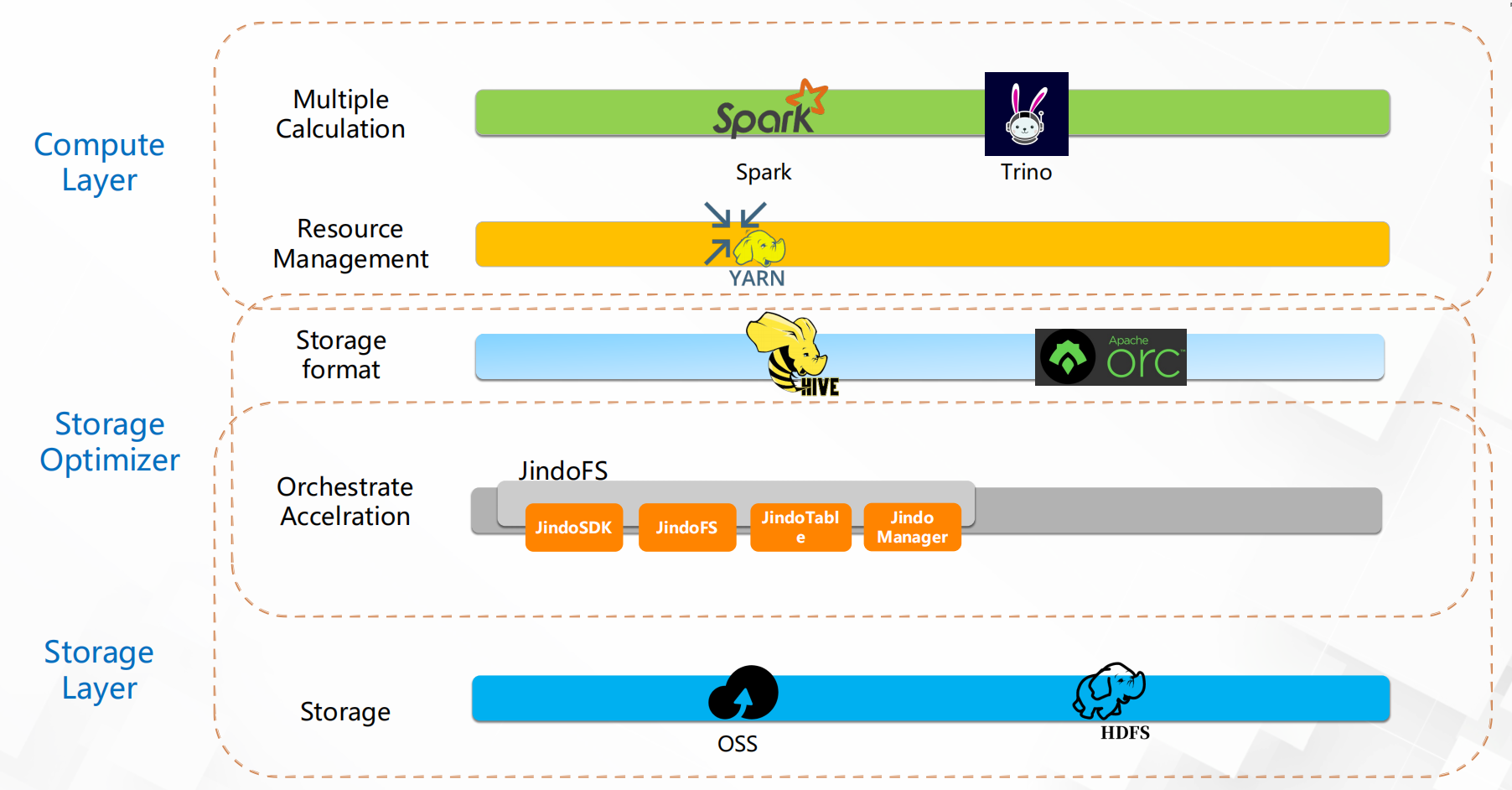
三、业务痛点
1、底层存储从hdfs切换到oss之后,spark sql跑批任务,时间很长。经常一个工作流需要几个小时。
2、spark查询时,shuffle过程中,大量的中间数据需要写入磁盘,导致ecs的磁盘经常打满。
3、ods层数据合并流程过于复杂,每天用ods表left join增量表,再insert overwrite到新的ods表,再将旧的ods表rename,新的ods表rename成原来的ods表名,同时还有数据质量检查,数据条数统计等,合并速度很慢。
4、初期集群因为各种问题报错,以及机器磁盘被打满,平台每天都要重启2-3次集群或者kill掉spark
任务。严重影响了生产上正在执行的任务。数开组小伙伴不得不加班加点的手动执行任务。
四、为什么需要StarRocks 存算分离
1、原先spark任务批任务,速度很慢,导致开发效率很低。使用StarRocks 存算分离,数据还是存储在oss中,测试下来任务执行耗时对比spark任务有5-10倍的提升。缩短了执行耗时,提升开发效率。
2、原先ods层增量数据合并流程,由于hive表没有主键更新的概念(没有upsert,只有insert overwrite),只能每天单表几亿数据量合并几十万的增量数据,再全量覆盖。使用StarRocks 存算分离后,可以建主键模型表,增量数据按照主键更新即可(upsert),数据合并更新效率快。
3、StarRocks 存算分离生态良好,可以兼容目前的数据格式,可以打通hive metstore直接查询oss中的orc文件,hive中的ods、dwd表可以直接通过StarRocks 的 hive catalog查询。
4、原先的大数据平台有繁多的组件例如spark、yarn、hive、trnio、zookeeper等,日常每个组件维护起来非常耗时且麻烦,在开发业务的同时还得分出时间维护大数据集群。使用StarRocks只需要维护一个StarRocks即可, 维护方便。
5、原有大数据集群利用率低,白天有大量的任务,到了晚上资源基本闲置。使用StarRocks 存算分离,be计算节点无状态,可以根据业务需要很方便的扩容缩容。
6、团队内部需要建设指标标签系统,沉淀指标数据进行BI展示,BI报表需要对数据进行上卷汇总以及支持汇总数据的下钻到明细数据。
五、生产环境使用StarRocks 存算分离的规划
初期,计划使用StarRocks做指标标签以及企业画像系统(StarRocks 作为ADS层使用),数据沉淀到BI报表上展示。将指标、标签数据通过hive catalog计算汇总数据StarRocks,明细数据通过异步物化视图写入StarRocks 中。BI报表连接StarRocks数据源读取数据。此时,大数据集群与StarRocks共存。
中期,新的数据需求使用StarRocks进行数据开发、计算存储。 在开发过程中逐步熟悉StarRocks的相关特性以及性能调优。
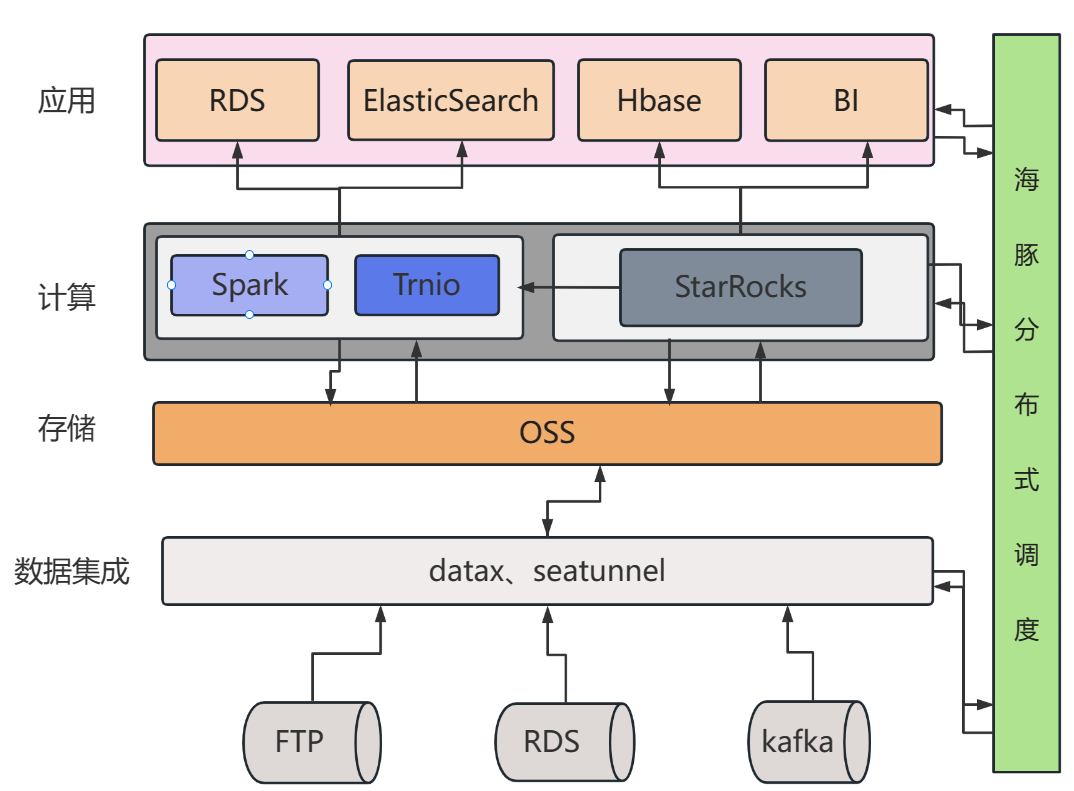
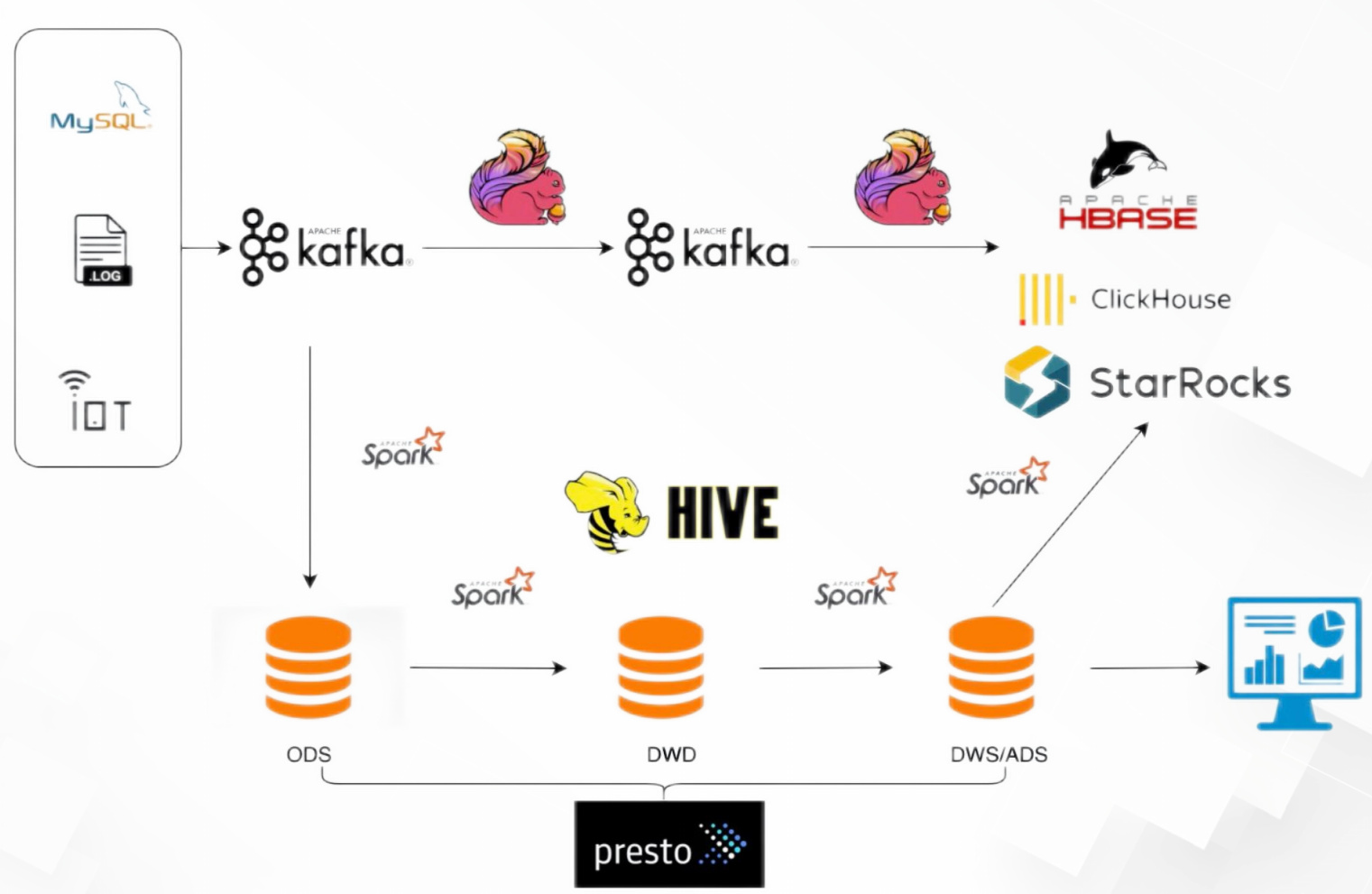
初期中期大数据平台架构(已在生产使用):
使用StarRocks存储指标、标签以及画像输出到hase以及BI报表,部分替代trnio即席查询,通过hive catalog+异步物化视图将hive数据导入到StarRocks中
最终大数据平台架构(规划中)
弃用大数据cdh集群,整体数据链路组件只有由Kafka、Flink和Starocks
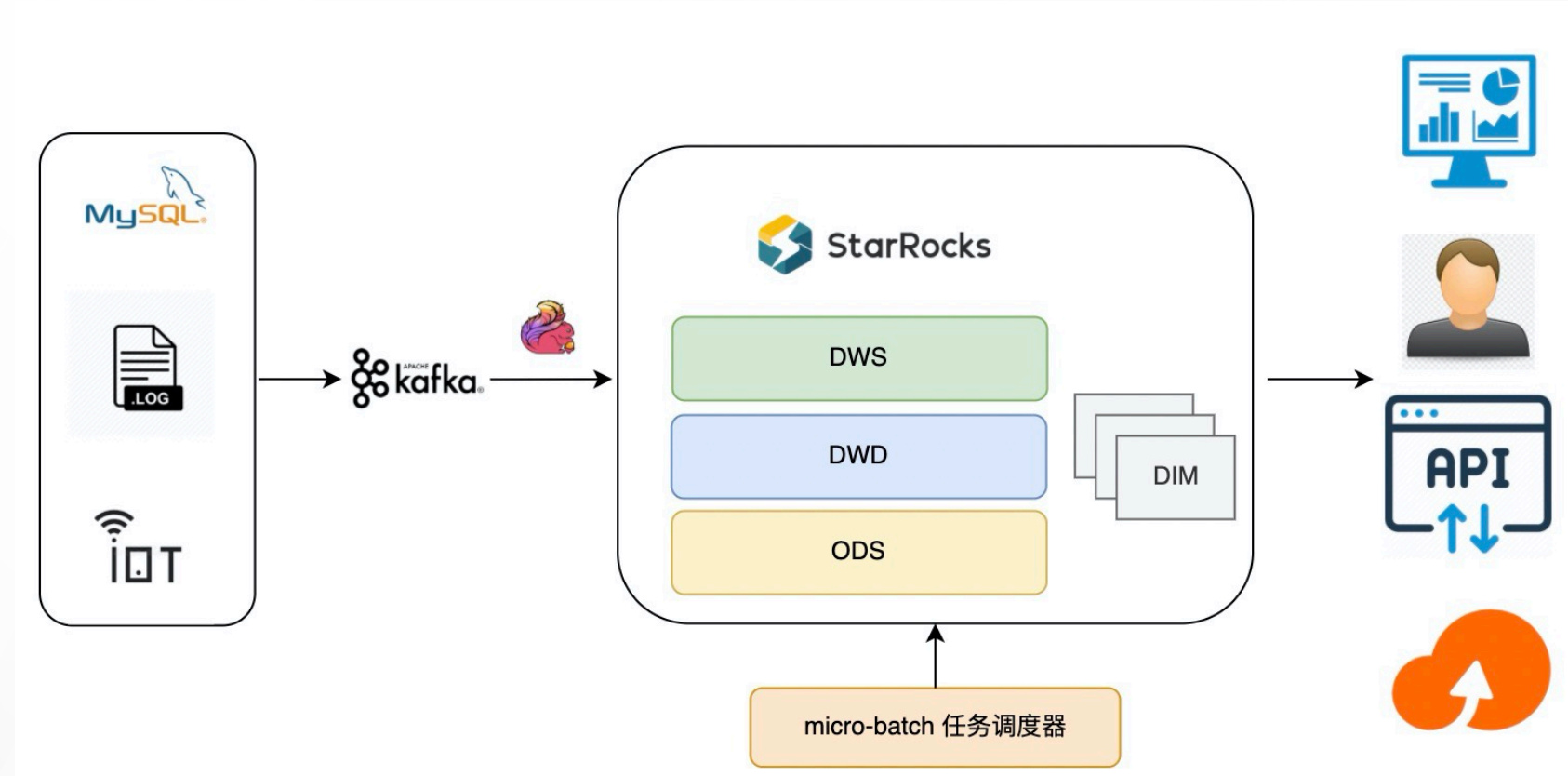
后期,计划用StarRocks替换掉现有的大数据集群,用StarRocks 统一整个大数据平台,数据存储和计算分离,存储层在OSS中,计算节点可以根业务需要任意扩容缩容。 避免了集群组件繁多,维护麻烦的问题,只需要维护StarRocks即可。
六、StarRocks 存算分离测试目标
测试StarRocks 3.0.0 RC01 版本存算分离在真实业务场景中的性能表现,主要包含以下测试场景:
-
数据同步性能测试
-
数据查询性能测试
测试环境
硬件规格
FE
| 硬件 | 规格说明 |
|---|---|
| 实例规格 | 通用型 g7 |
| Region | hangzhou |
| 节点数 | 1 |
| CPU | 4 vCPU |
| 内存 | 16 GB |
| 磁盘 | 200GB SSD |
| 网络 | 内网,千兆网卡 |
BE:
| 硬件 | 规格说明 |
|---|---|
| 实例规格 | 通用型 g7 |
| Region | hangzhou |
| 节点数 | 2 |
| CPU | 8 vCPU |
| 内存 | 64 GB |
| 磁盘 | 300GB SSD |
| 网络 | 内网,千兆网卡 |
软件版本
StarRocks 3.0.0 RC01
软件配置
设置全局执行内存128G限制
SET GLOBAL query_mem_limit = 137438953472
设置了查询超时时间
SET GLOBAL query_timeout = 3000
测试结果
数据导入
使用数据导入方式为:datax(底层为stream load导入)
Starrocks导入性能:
1、使用datax从mysql中同步一张企业基础信息表,数据量为3亿,导入到no cache的sr存算分离表中,平均导入速度在24 m/s左右
2、导入到有cache的sr存算分离表中,平均导入速度在30m/s
已有方案导入性能:
1、对比datax 从mysql以txt格式直接同步到oss中的速度,平均导入速度15 m/s
数据查询
注:生产环境使用spark sql+udf开发,spark计算节点使用了5台128G内存的ecs
硬件规格如图所示:
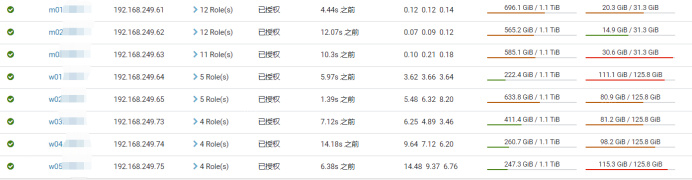
注:
sr3.0(with cache) :设置了本地磁盘缓存,"enable_storage_cache" = "true","storage_cache_ttl" = "2592000","enable_async_write_back" = "false"
set1048576 :在be设置了starlet_fs_stream_buffer_size_bytes = 1048576参数,且没有本地磁盘缓存
sr3.0(no cache):没有本地磁盘缓存,"enable_storage_cache" = "false","storage_cache_ttl" = "0","enable_async_write_back" = "false",数据完全存储在oss中,从oss中读取数据;
spark sql:spark sql查询hive数据,hive集成了阿里云jindo sdk,hive中数据全部以orc格式存储在阿里云oss中.spark sql使用了5台128G的ecs计算节点
trino:trino查询hive数据,使用了一台128G的ecs
执行耗时(秒):
| sr3.0 (with cache) | set1048576 | sr3.0(no cache) | spark sql | trino | |
|---|---|---|---|---|---|
| Total | 85.124 | 233.861 | 431.416 | 4011.893 | \ |
| Query01 | 0.032 | 0.997 | 0.634 | 25.854 | 2.248 |
| Query02 | 0.08 | 1.6 | 54.470 | 49.419 | 2.398 |
| Query03 | 1.734 | 4.976 | 21.208 | 161 | 4.669 |
| Query04 | 0.338 | 0.475 | 40.590 | 193 | 6.891 |
| Query05 | 5.760 | 10.80 | 23.93 | 57.62 | 2.243 |
| Query06 | 5.250 | 7.115 | 10.214 | 119 | Error:Query exceeded memory limit of 20GB |
| Query07 | 1.930 | 8.898 | 5.37 | 810 | Error:Query exceeded memory limit of 20GB |
| Query08 | 70 | 199 | 275 | 2596 | Error:Query exceeded memory limit of 20GB |
| Query09 | 54.86 | 268 | 346 | 132 | Error:Query exceeded memory limit of 20GB |
测试问题:
Datax同步,导入批次太多,会产生Too many versions报错,所以在导入的时候要控通过datax的channel(通道数,前提是mysql writer中包含主键切割,否则channel参数不生效)参数控制,以及starrockswriter的maxBatchRows,maxBatchSize,flushInterval
附录:
建表语句:

执行语句:
Query01~06为测试sql,Query07~09为生产上在使用的sql
Query01:
单表3亿数据量,limit查询
![]()
Query02:
单表3亿数据量,count查询
![]()
Query03:
单表3亿数据量,单条数据查询(无索引)

Query04:
左表4000w数据量,右表1000w数据量join(无索引)

Query05:
单表3亿数据量,聚合查询

Query06:
单表3亿数据量,开窗排序查询

Query07:
两张表join 再多表union all查询
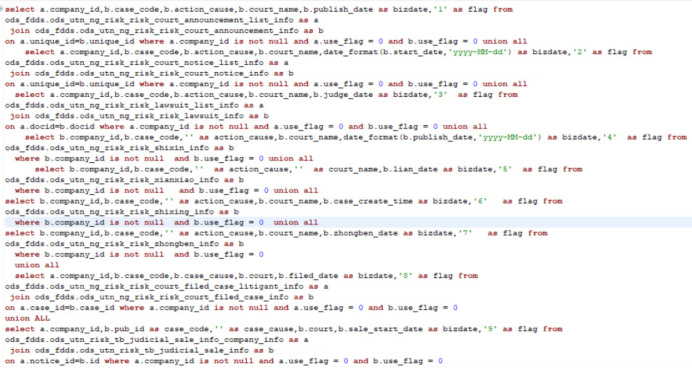
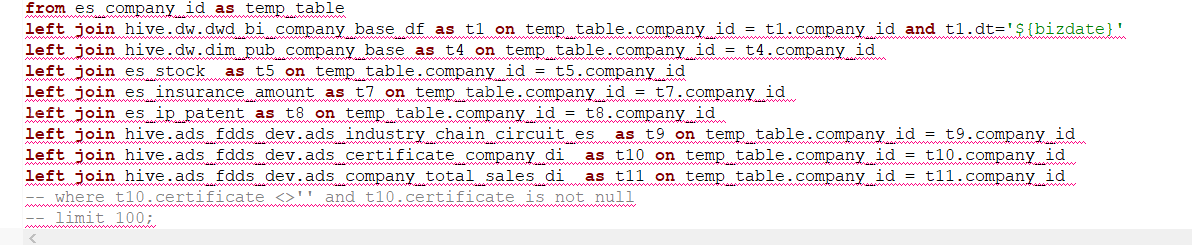
Query08:
复杂sql join查询 主表3亿数据量,left join 2张3亿数据量的清洗表,其余表千万数据量
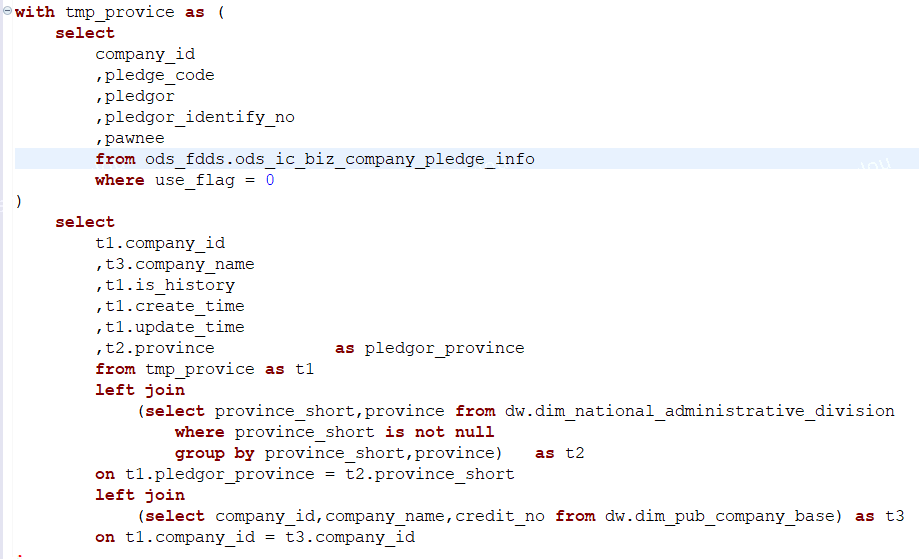
Query09:
主表1600w数据量, join小表(字典表)和3亿数据量的企业表
StarRcoks 集群监控
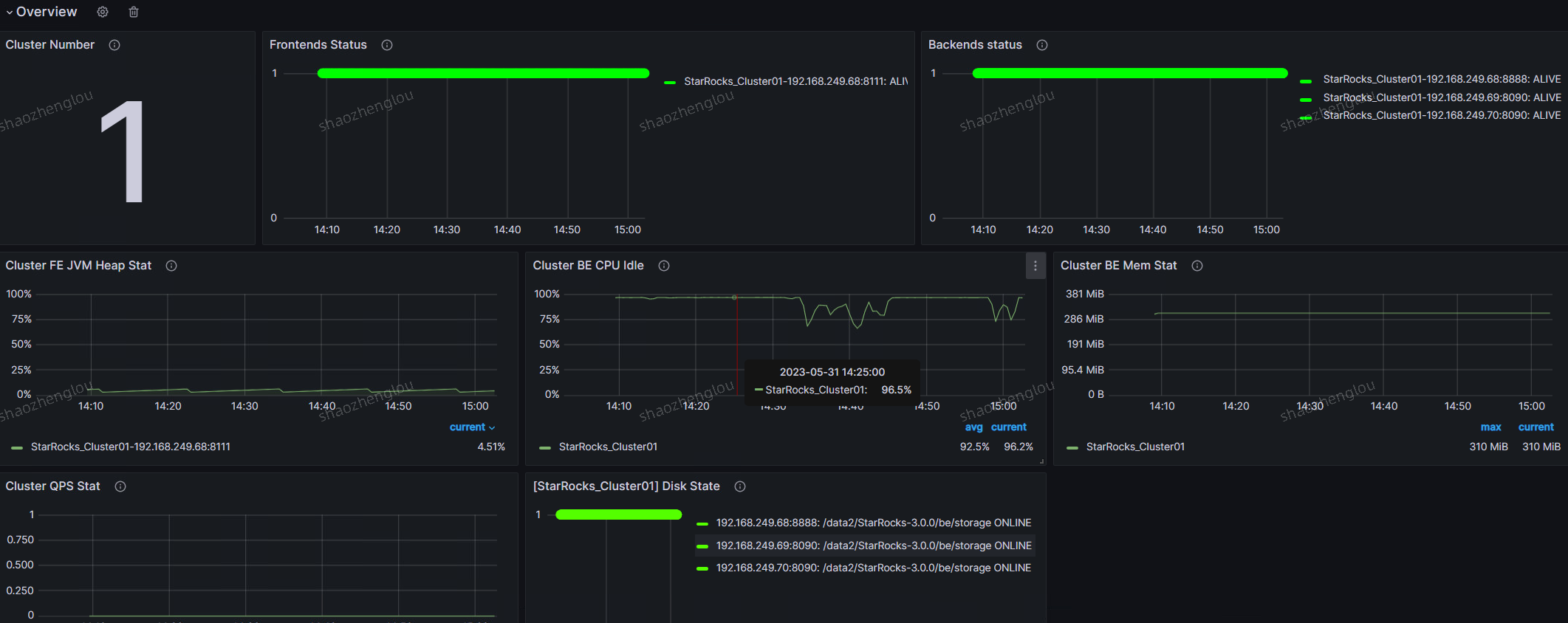
Overview
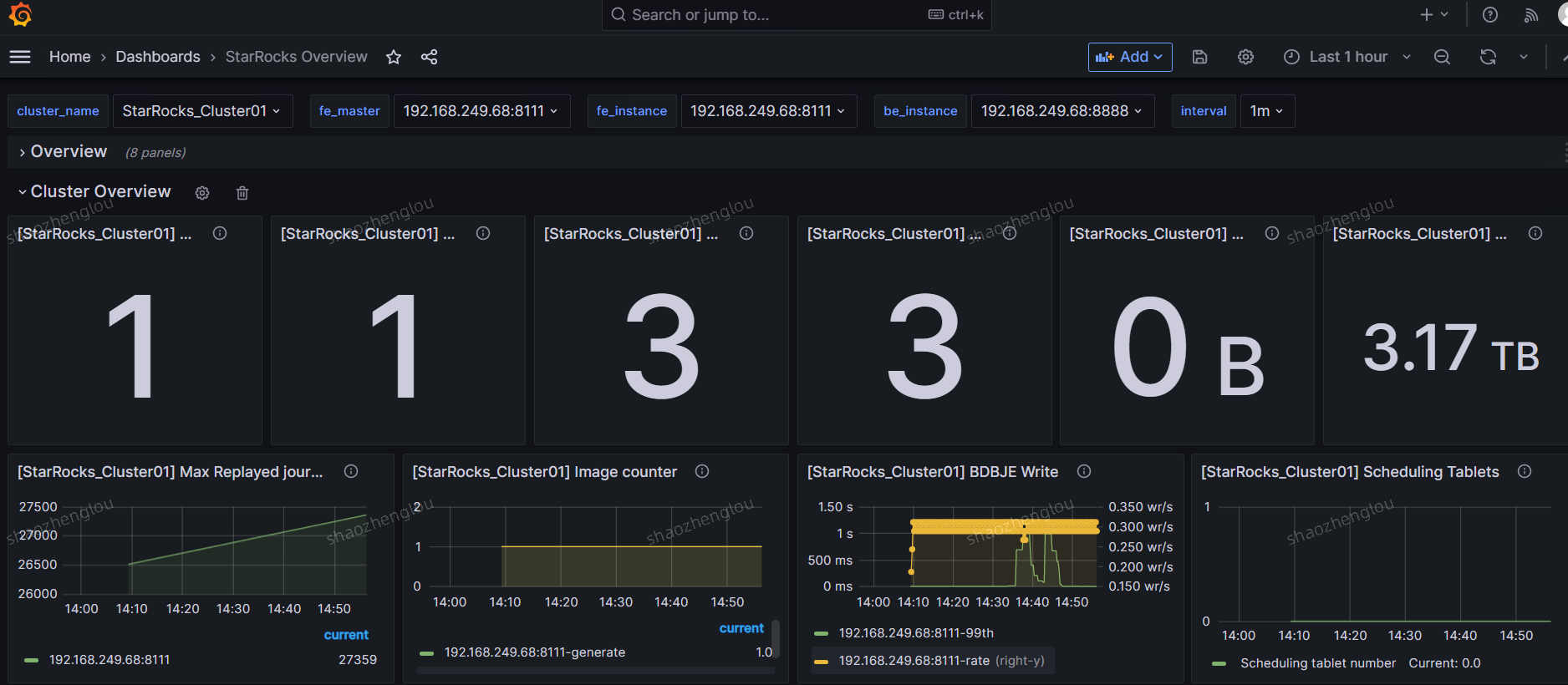
Cluster Overview
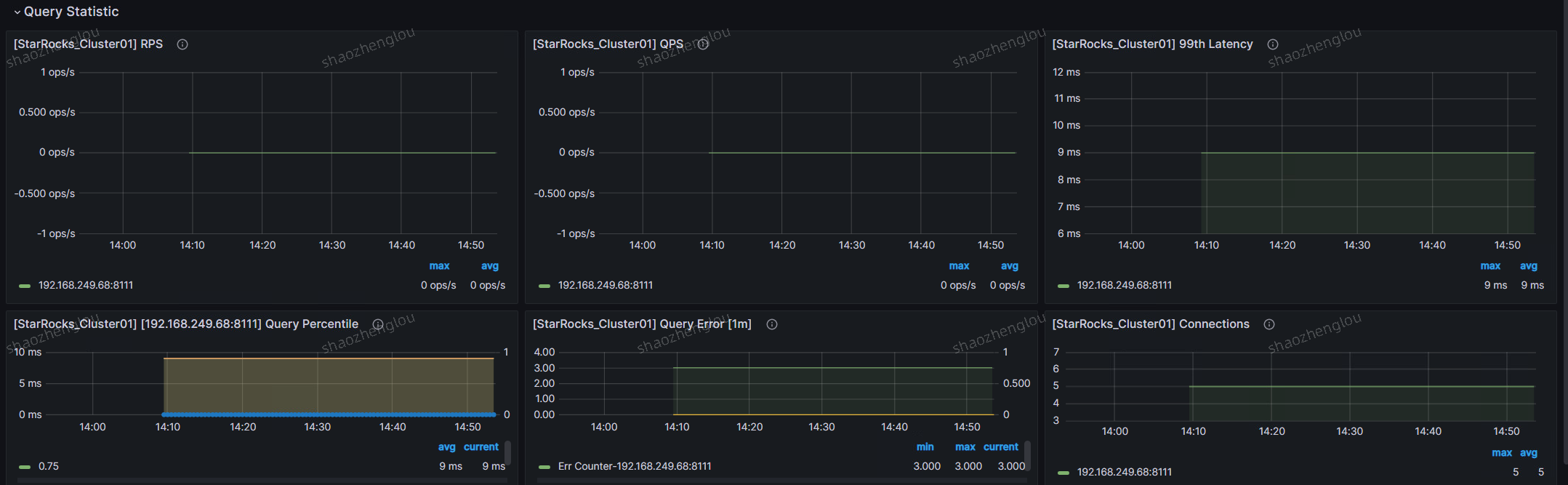
Query Statistic
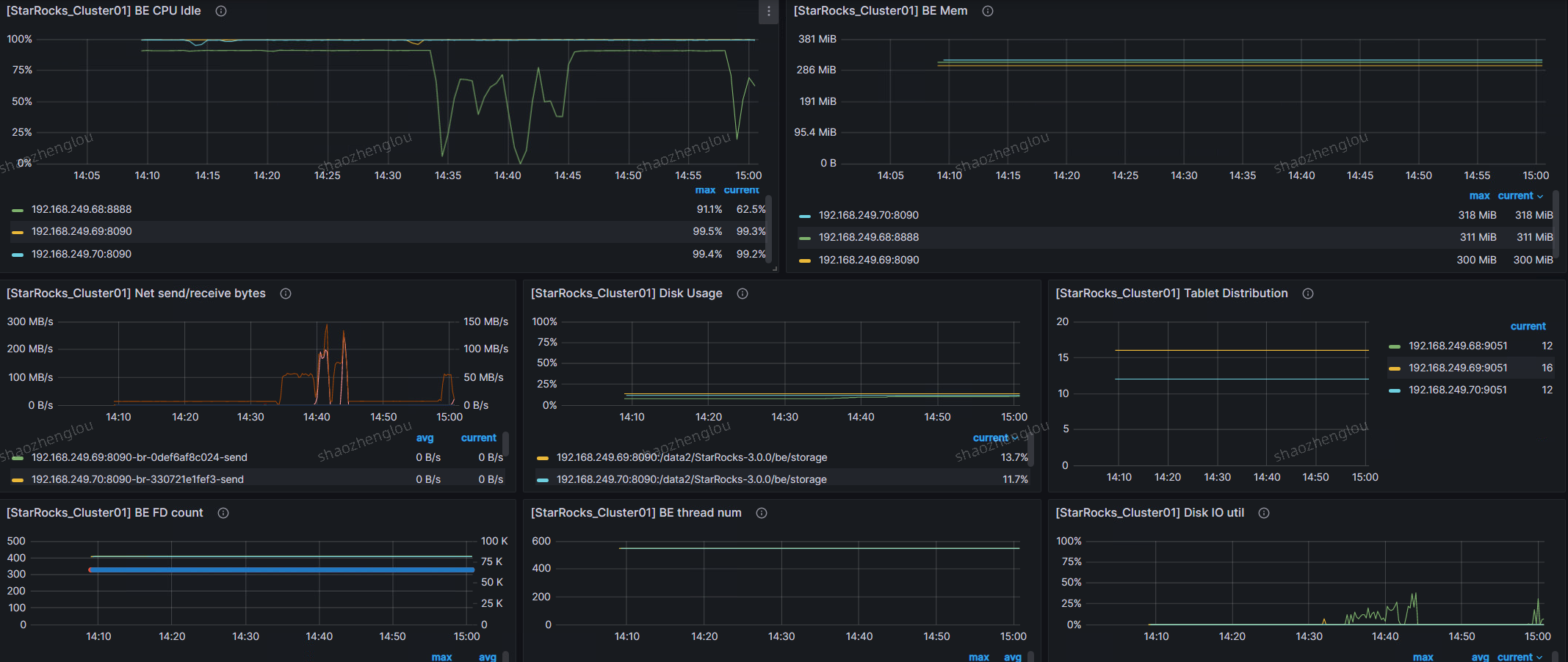
BE监控
测试总结
对比spark任务,StarRocks 存算分离表no cahe,查询性能有3-6倍的提升,有local cahe的情况下,查询有10倍以上的速度提升。性能方面,在local cache命中的情况下,查询延时与存算一体架构持平。
对比trino即席查询,StarRocks 存算分离表在有local cahe的情况下,单表查询执行耗时有4-10倍提升,no cache的StarRocks 存算分离表,单表查询执行耗时约为trino执行耗时的5-8倍。多表查询trino直接报错单个查询执行内存超过20G,多表查询不做对比。
