
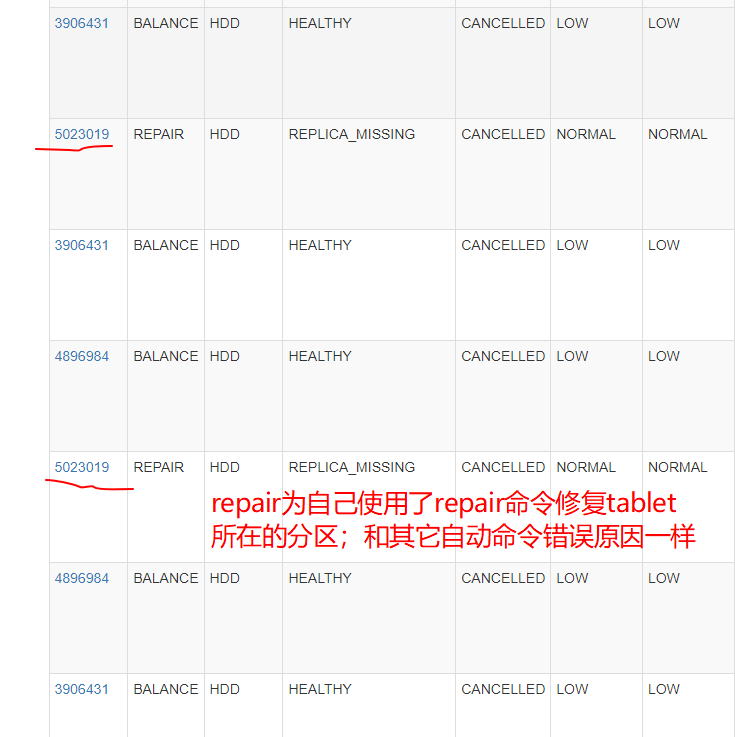
【详述】发现一个tablet状态为unhealthy;show到副本一层时发现只有两个副本,repair命令修复此tablet所在分区,状态为REPLICA_MISSING,原因为make snapshot failed;这是我们待解决的一个问题,希望获得帮助;
在查看日志发现另一个问题,大量的tablet 在(自动) balance 状态为cancel,原因也是make snapshot failed;
【背景】2.5.4升级到3.0.0
【业务影响】
【StarRocks版本】3.0.0
【集群规模】3fe+10be
【联系方式】15555980831@163.com
【附件】
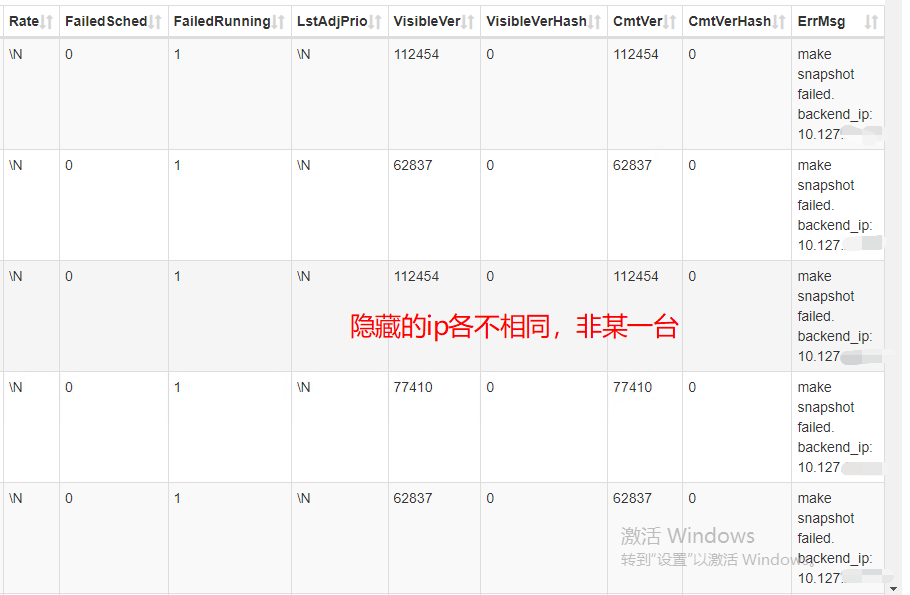
fe.warn.tail_1000.log (285.9 KB) 这些在Current path: //cluster_balance/history_tablets 里都是cancel状态,type为balance,状态为healthy,errMsg为 make snapshot failed.
升级时是不是已经大量tablet unhealthy?有没有进行 通用兼容性配置?一些注意事项有没有参考?
这是升级完成后,运行一段时间后出现的问题;集群已经经历四次升级,过程也较为熟悉,已经参考注意事项。
目前诉求是:如何将这个tablet的3副本恢复,现在只有两个副本;虽然可以使用,但是三副本应该是一般副本数的共识吧;
另一个就是所说的告警,/cluster_balance/history_tablets 大量历史任务类型type是balance的都是失败的,原因都是make snapshot failed;
麻烦发一下be.warn的日志吧
有问题的tablet,show tablet,找到对应的BE,看一下be.warn和be.info有什么报错信息。
异常的tablet少量,可以通过命令修复
ADMIN SET REPLICA STATUS PROPERTIES(“tablet_id” = “10003”, “backend_id” = “10001”, “status” = “bad”);;
这个backend 如果异常的 tablet 太多,也可以考虑先 decommission 掉,之后再把这个 backend重新加回集群来批量处理异常 tablet。
请问异常的节点是不是升级过程中停了太久,正常不会缺失这么多版本。
balance 失败的 tablet单独去看都是正常的,但是balance一直 cancelled,失败;be节点都存在这个问题
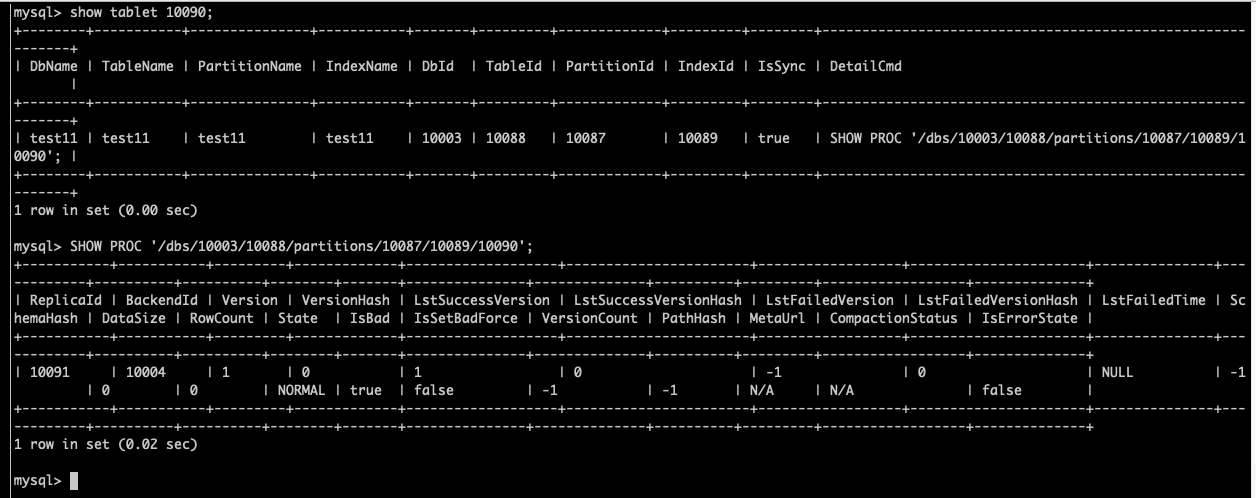
另外,你把 fe leader 中的这个 tablet 5023019 的日志grep 出来,cat fe.log | grep “5023019”
然后 be.INFO 这个 tablet 相关的日志也发一下,cat be.INFO | grep “5023019” 日志如果比较多,可以压缩一下,可以看下 fe.log 看下 这个 clone 的 src 和 dest 是哪两个几点,把这两个 backend 的日志 grep 出来就行,如果 backend 比较多的话,不用都 grep

好的,这个表的 show create table xxx的结果也给下
![]()
我看每次都从这个 backend src backend: 10.127.27.13 clone 数据,这个 ip 对应的 backend id 是多少,发一下
不用了,应该是11119,你把这个 be 上的 be.INFO 压缩一下发出来,这个是源节点 ,make snapshot 实际就是在这个节点上做,不要 grep 了,因为可能还有上下文是关键信息需要看,直接把 be.INFO 压缩一下发上来看下
还有 dest backend: 11122, 的 be.INFO 也压缩一下发上来吧
方便提供微信,企业微信,飞书等联系方式吗?处理问题的效率会提高很多,谢谢!
或者你先执行一下 ADMIN SET REPLICA STATUS PROPERTIES(“tablet_id” = “5023019”, “backend_id” = “11119”, “status” = “bad”); 看下,手动把原来的 src 设置为 bad,让 be 从另外一个副本拉取 full snapshot,原来的 src 看起来是缺了个版本
好的,稍后我提供下,不过是不是这个问题呢? 11119 和11122 是已在的两个副本,生成新副本失败是make snapshot failed;各个SR节点 定时的 balance 都在失败,也都是make snapshot failed(这些tablet是正常的)