
背景分析与测试用例设计
在我们实际的业务中目前有两种场景遇到的越来越频繁:
- 云上的 ESC 或者私有云的虚拟主机越来越难申请,有来自客户的资源压力,也有来自本地运维的压力,但 k8s 集群有大量资源闲置。
- 云上的 OLAP 由于底层硬件规划的原因,性价比极低,而客户又需要基于基础的云资源,低成本的解决 OLAP 查询的问题。
基于以上资源诉求,我们一直在寻找一个低成本的、云原生 OLAP 方案。我初步的想法是基于 k8s、对象存储就能搭建一套 OLAP 引擎。而我们的诉求与 StarRocks 3.0(以下简称 SR)的存算分离设计不谋而合。
我们期望的架构如下:
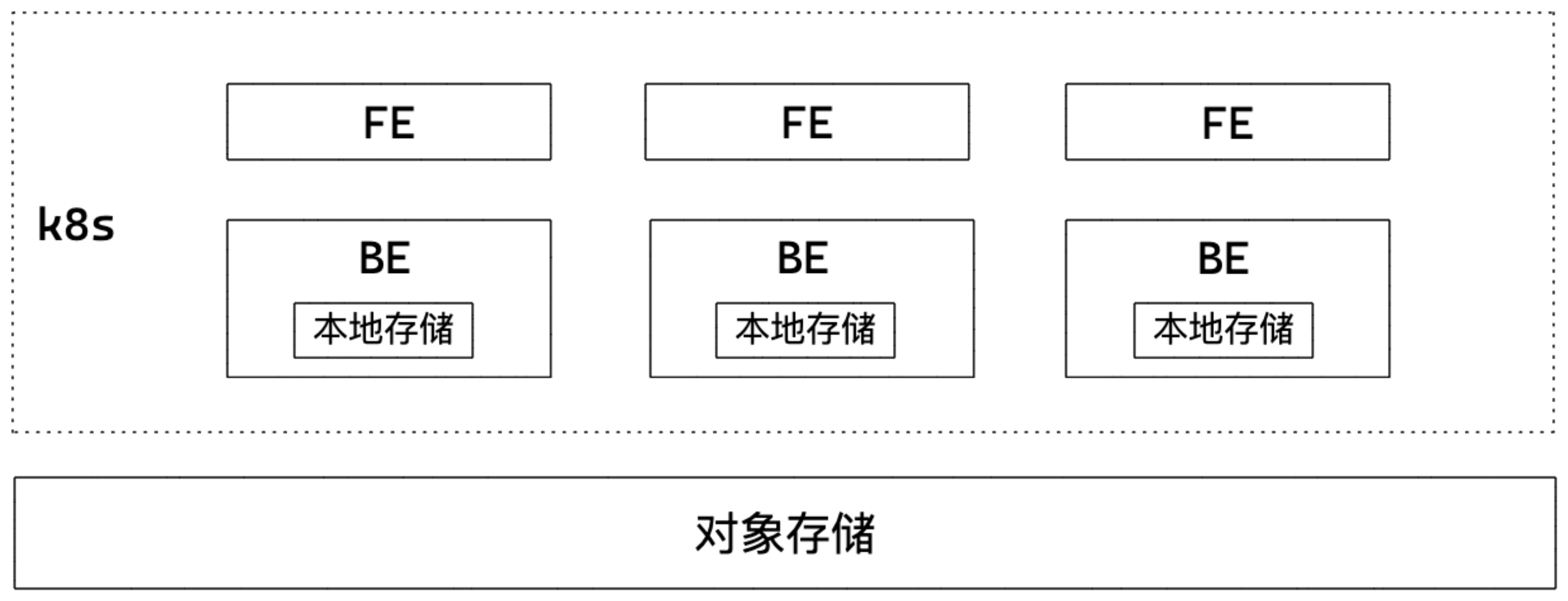
这个架构没有什么特殊的,就是 SR 3.0 基于 k8s 部署的写实,其中需要说明的是我们打算每个 BE 上本地存储的总和大于每日读写的数据量,以保证数据正常读取。举例说明:我们的数据总量有 100T,每日操作的数量仅仅有 500G,包括 ETL 同步导入的数据、计算时所需读取的数据、计算结果数据,以上三类所占空间。理论上每日导入、导出、计算、查询都利用本地盘,其他数据存储在对象存储。表在设计时都采用异步写对象存储的模式。
以上是基于与原厂人员讨论的几个架构决策点做出的设计:
- 可以设置表的本地缓存 TTL,本地存储中的缓存采用类似 LRU 的淘汰机制,在本地缓存不足时,主动清理过时的数据。
- 异步写模式下,当本地缓存已被写满,且本地缓存所有数据都没有异步写入对象存储的情况下,直接报错,这样可以保证数据写入的一致性。
以上的架构设计是有数据丢失的风险的,但在我们的整体架构设计中,OLAP 库处于数据链路的末端,发生数据问题,短期数据可以通过前端的数据补偿,影响并不大。
本次测试主要想验证,几个方面:
- 基于相同硬件,存算分离方式和存算一体的方式,导入和查询是否有较大差异
- 基于相同硬件,存算分离方式中同步写对象存储和异步写对象存储导入和查询是否有较大差异
- 基于相同硬件,存算分离方式中有本地缓存和没有本地缓存导入和查询是否有较大差异
同步写、异步写、没有本地缓存对比测试
测试样例
拿一个实际的业务表,40 列 +,表内单日数据 2200 万 +,对单日数据做导入和查询。
建三个表:ORDER、ORDER_ASYNC、ORDER_NOCACHE,分别导入数据
写入语句设计:
curl --location-trusted -u root:eccpos2019 -H "label: 表名" \
-H "max_filter_ratio:1" \
-H "columns: ......" \
-T ORDER_ASYNC -XPUT \
http://FE的IP:8030/api/ 数据库名 / 表名 /_stream_load
测试环境
8C32G 主机 5 台,全部 5 台部署 MinIO
存算分离集群:选其中一个机器部署 1 个 FE、1 个 BE
多个 BE 的分布式环境能提供更好的性能,这一点在理论上,他人的实践中,存算一体的版本中都有过证明和实践结果支持,多个 BE 的的测试作为第二阶段的测试目标,第一阶段以 1 个 FE,1 个 BE 为主,日志、资源监控都能更轻易的获取和分析。
存算一体集群:选其中一个机器部署 1 个 FE,选择三台部署 3 个 BE
存算一体的集群默认需要三个 BE 保证副本的安全性,从这一点上来说,存算分离集群更省 BE 的资源。
存算一体和存算分离数据导入测试结果
存算一体导入结果:
"TxnId": 2,
"Label": "SAL_SALESORDER",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 22298400,
"NumberLoadedRows": 22298400,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 7711779006,
"LoadTimeMs": 181082,
"BeginTxnTimeMs": 52,
"StreamLoadPlanTimeMs": 210,
"ReadDataTimeMs": 122258,
"WriteDataTimeMs": 180736,
"CommitAndPublishTimeMs": 82
存算分离异步导入结果:
"TxnId": 6,
"Label": "ORDER_ASYNC",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 22298400,
"NumberLoadedRows": 22298400,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 7711779006,
"LoadTimeMs": 135688,
"BeginTxnTimeMs": 1,
"StreamLoadPlanTimeMs": 32,
"ReadDataTimeMs": 100359,
"WriteDataTimeMs": 135557,
"CommitAndPublishTimeMs": 96
存算分离同步写入返回结果:
"TxnId": 8,
"Label": "ORDER_SYNC",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 22298400,
"NumberLoadedRows": 22298400,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 7711779006,
"LoadTimeMs": 148018,
"BeginTxnTimeMs": 2,
"StreamLoadPlanTimeMs": 40,
"ReadDataTimeMs": 112510,
"WriteDataTimeMs": 147925,
"CommitAndPublishTimeMs": 49
总结一下:
| 存算一体 | 存算分离异步写 | 存算分离同步写 | |
|---|---|---|---|
| 181082 | 135688 | 148018 |
以上结果经过反复测试,因多次测试结果相似,展示其中一次的结果。
总体来说,存算一体反而稍慢,我能理解的是比存算分离异步写慢是因为副本复制多了一次 IO,比存算分离同步写慢的原因未知。
存算分离模式下的数据导入测试结果
异步写入返回结果:
"TxnId": 6,
"Label": "ORDER_ASYNC",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 22298400,
"NumberLoadedRows": 22298400,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 7711779006,
"LoadTimeMs": 135688,
"BeginTxnTimeMs": 1,
"StreamLoadPlanTimeMs": 32,
"ReadDataTimeMs": 100359,
"WriteDataTimeMs": 135557,
"CommitAndPublishTimeMs": 96
同步写入返回结果:
"TxnId": 8,
"Label": "ORDER_SYNC",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 22298400,
"NumberLoadedRows": 22298400,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 7711779006,
"LoadTimeMs": 148018,
"BeginTxnTimeMs": 2,
"StreamLoadPlanTimeMs": 40,
"ReadDataTimeMs": 112510,
"WriteDataTimeMs": 147925,
"CommitAndPublishTimeMs": 49
无缓存写入返回结果:
"TxnId": 16,
"Label": "SAL_SALESORDER_NOCACHE",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 22298400,
"NumberLoadedRows": 22298400,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 7711779006,
"LoadTimeMs": 141737,
"BeginTxnTimeMs": 1,
"StreamLoadPlanTimeMs": 36,
"ReadDataTimeMs": 105214,
"WriteDataTimeMs": 141648,
"CommitAndPublishTimeMs": 50
当表中存在 2000 万数据的时候,再次导入新的数据,
异步写入返回结果:
"TxnId": 12,
"Label": "ORDER_ASYNC1",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 22298400,
"NumberLoadedRows": 22298400,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 7711779006,
"LoadTimeMs": 140034,
"BeginTxnTimeMs": 1,
"StreamLoadPlanTimeMs": 38,
"ReadDataTimeMs": 106072,
"WriteDataTimeMs": 139928,
"CommitAndPublishTimeMs": 65
同步写入返回结果:
"TxnId": 14,
"Label": "ORDER_SYNC1",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 22298400,
"NumberLoadedRows": 22298400,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 7711779006,
"LoadTimeMs": 156751,
"BeginTxnTimeMs": 9,
"StreamLoadPlanTimeMs": 40,
"ReadDataTimeMs": 121112,
"WriteDataTimeMs": 156618,
"CommitAndPublishTimeMs": 79
无缓存写入返回结果:
"TxnId": 18,
"Label": "SAL_SALESORDER_NOCACHE1",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 22298400,
"NumberLoadedRows": 22298400,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 7711779006,
"LoadTimeMs": 174595,
"BeginTxnTimeMs": 2,
"StreamLoadPlanTimeMs": 33,
"ReadDataTimeMs": 114930,
"WriteDataTimeMs": 174488,
"CommitAndPublishTimeMs": 71
总结一下:
| 异步写模式 | 同步写模式 | 无缓存模式 | |
|---|---|---|---|
| 第一次写 | 135688 | 148018 | 141737 |
| 第二次写 | 156751 | 156618 | 174595 |
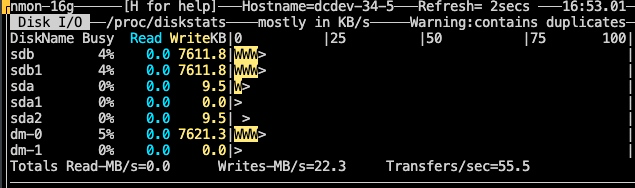
差别其实并不大,观察主机的 IO 情况如下:
第一次导入的 IO:
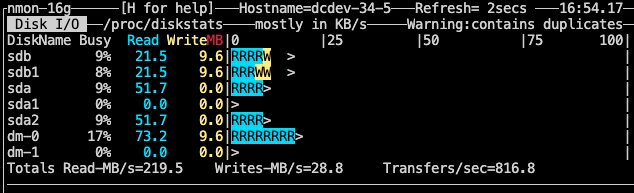
第二次导入的 IO:
导入后的 CPU 情况:

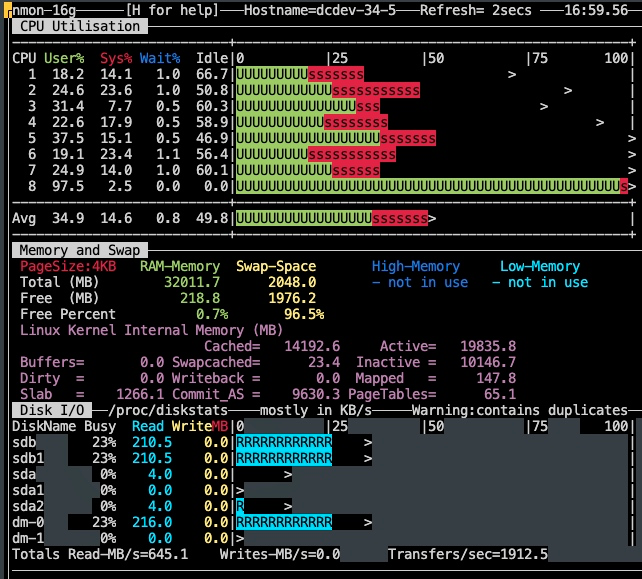
对上述资源使用和情况做分析,发现第二次导入以及第二次导入以后,都存在 compactions 过程,对持续的导入是有影响,我分析这个过程的资源消耗可能会因为存算分离的原因而被放大,但影响有限。
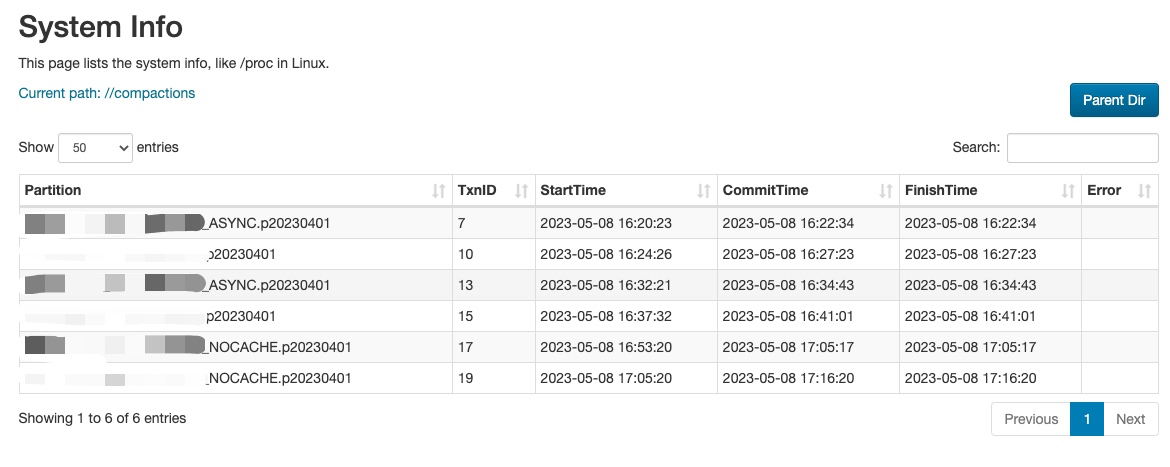
分析导入过程,在 BE 的磁盘 IO 未打满,MinIO 的 IO 未打满的情况下,同步导入和异步导入其实并没有太大差异。由于 IO 打满在目前的测试环境不好模拟,也会对其他业务产生影响,暂时不予测试。
存算分离模式下的数据查询测试结果
组织个 SQL 做个表扫查询:
select amt,count(*) as total_amt from order
group by amt
order by total_amt;
查看执行计划:
PLAN FRAGMENT 0
OUTPUT EXPRS:21: SALE_AMT | 44: count
PARTITION: UNPARTITIONED
RESULT SINK
5:MERGING-EXCHANGE
PLAN FRAGMENT 1
OUTPUT EXPRS:
PARTITION: HASH_PARTITIONED: 21: amt
STREAM DATA SINK
EXCHANGE ID: 05
UNPARTITIONED
4:SORT
| order by: <slot 44> 44: count ASC
| offset: 0
|
3:AGGREGATE (merge finalize)
| output: count(44: count)
| group by: 21: amt
|
2:EXCHANGE
PLAN FRAGMENT 2
OUTPUT EXPRS:
PARTITION: RANDOM
STREAM DATA SINK
EXCHANGE ID: 02
HASH_PARTITIONED: 21: amt
1:AGGREGATE (update serialize)
| STREAMING
| output: count(*)
| group by: 21: amt
|
0:OlapScanNode
TABLE: order
PREAGGREGATION: ON
partitions=1/568
rollup: SAL_SALESORDER
tabletRatio=2/2
tabletList=16593,16594
cardinality=44596800
avgRowSize=8.0
numNodes=0
对三种模式的表都查看了执行计划,是完全一样的,这一块有优化的空间。
对同步写对象存储的缓存表、异步写对象存储的缓存表、非缓存表进行查询耗时对比如下:
| 同步写缓存表 | 异步写缓存表 | 非缓存表 | |
|---|---|---|---|
| 第一次查询 | 593 毫秒 | 556 毫秒 | 3.911 秒 |
| 第二次查询 | 248 毫秒 | 251 毫秒 | 293 毫秒 |
经检查 starlet_cache 目录下,查询非缓存表后,并没有新的文件产生,说明非缓存表并不是把数据拉到本地得到了加速,而是利用了 SR 本身的查询缓存机制。
对非缓存表变换字段进行查询,观察结果集数量,查询时间分布如下:
| 结果集数量 | 96 | 67374 | 32442 | 19507 |
|---|---|---|---|---|
| 耗时 | 766 毫秒 | 3.911 秒 | 10 秒 | 9.7 秒 |
总体上讲,少于 200 行数据的,查询时间会极短,可能是 SR 内部优化的结果,我还需要再进一步分析,结果集大于 1 万的,部分时间并不规律,可能跟我底层 MinIO 还被其他业务使用有关。
建议
经过以上测试,有一点小小的建议:
- 是否可以有一个监控指标或者 show proc 里面加一项,可以说明异步写对象存储的模式下,写入进度如何,是否已经完成了写入
- 存算分离模式下,是否可以在执行计划中明确表示出是读的对象存储还是本地缓存
