
StarRocks 存算分离性能测试报告
—— 2023/4/27 任伟
一、业务场景
公司从2021年开始引入StarRocks 存算一体架构作为主要的OLAP引擎,随着业务的发展,我们发现了如下几类问题:
1、集群数据量和计算量的增长并不完全匹配,单个集群数据存储年增量可能达到了200%,而内存、CPU的增长可能只有40%。通常面对CPU、内存、磁盘存储不足的情况,都是通过横向增加集群机器的方式来进行扩容,没有对资源进行精细化的成本控制;
2、集群资源使用率朝夕现象明显,StarRocks作为线上报表的OLAP引擎,其资源使用与客户的使用规律息息相关, 白天查询资源使用率高,晚上基本没使用。在月底、季度底、年底的特殊时期,客户会进行月度、季度、年度核算,这个时候的查询负载都特别高。如果不进行查询优化处理,集群整体的查询响应会变慢。
基于上述问题,我们想要针对性解决的主要是2个点:
1、降本。降低计算存储成本,当集群需要扩容的时候,不再是简单通过增加物理机器的方式来进行扩容,而是计算存储独立按需扩展。
2、弹性。当查询负载增加的时候,能迅速、动态增加计算资源,提高集群的处理能力。 当查询负载降低的时候,能迅速、动态减少计算资源,按需分配。
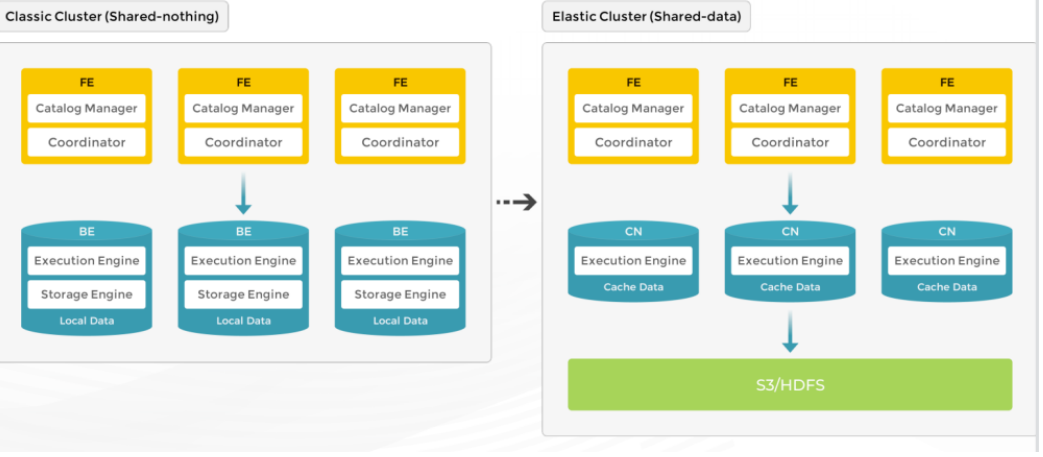
StarRocks 3.x的存算分离架构为解决上述问题带来了可能性。在存算分离的模式下,StarRocks 将数据存储在兼容 S3 协议的对象存储(例如 AWS S3、OSS 以及 MinIO)或 HDFS 中,而本地盘作为热数据缓存,用以加速查询。
通过存储计算分离架构,可以降低存储成本,针对计算节点可以按需弹性扩容。在查询命中缓存的情况下,存算分离集群的查询性能与普通集群性能一致。因此我们对StarRocks 3.0进行了测试。
二、测试预期
StarRocks 3.0存算分离的查询性能和存算一体基本持平
StarRocks 3.0能快速(至少比存算一体数据rebalance快)的增加计算节点提高集群整体的并发、查询响应能力
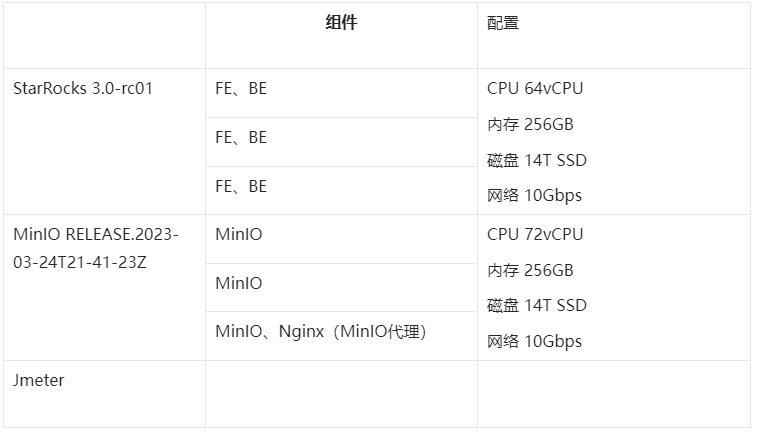
三、硬件配置
机器配置 (存储,网络带宽等)
四、其他条件
测试数据集
SSB
Star Schema Benchmark(以下简称 SSB)是学术界和工业界广泛使用的一个星型模型测试集(来源论文),通过这个测试集合可以方便的对比各种 OLAP 产品的基础性能指标。
| 表名 | 解释 | 100G 数据行数 |
|---|---|---|
| lineorder | SSB 商品订单表 | 6亿 |
| customer | SSB 客户表 | 300万 |
| part | SSB 零部件表 | 140万 |
| supplier | SSB 供应商表 | 20万 |
| dates | 日期表 | 2556 |
| lineorder_flat | SSB 打平后的宽表 | 6亿 |
DDL 、Query参考 https://docs.starrocks.io/zh-cn/3.0/benchmarking/SSB_Benchmarking
TPC-H
TPC-H 是美国交易处理效能委员会 TPC(Transaction Processing Performance Council)组织制定的用来模拟决策支持类应用的测试集。它包括一整套面向业务的 ad-hoc 查询和并发数据修改。
| 表名 | 解释 | 100G 数据行数 |
|---|---|---|
| customer | 用户表 | 1500万 |
| lineitem | 订单明细表 | 6亿 |
| nation | 国家信息 | 25 |
| orders | 零售订单表 | 1.5亿 |
| part | 配件表 | 2000万 |
| partsupp | 配件供应表 | 8000万 |
| region | 地区信息 | 5 |
| supplier | 供应商信息 | 100万 |
DDL 、Query参考:https://docs.starrocks.io/zh-cn/3.0/benchmarking/TPC-H_Benchmark
参数配置
#建表属性
#是否启用本地磁盘缓存
enable_storage_cache = true
#本地磁盘中缓存热数据的存活时间,单位s
storage_cache_ttl = 2592000
#是否允许数据异步写入对象存储
enable_async_write_back = false
# BE配置
# 预读缓冲区的调整 默认是128KB
starlet_fs_stream_buffer_size_bytes = 1048576
# 避免可能的倾斜问题
connector_scan_node_always_shared_scan = false
五、测试结果
Shared_nothing VS Shared_data
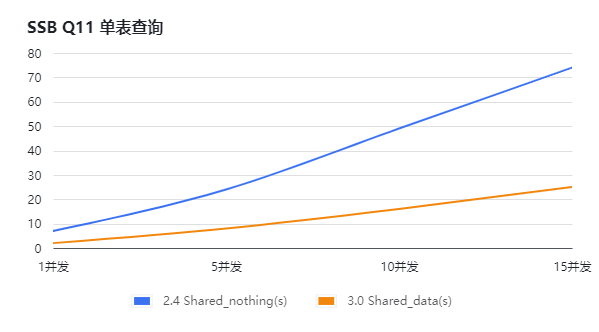
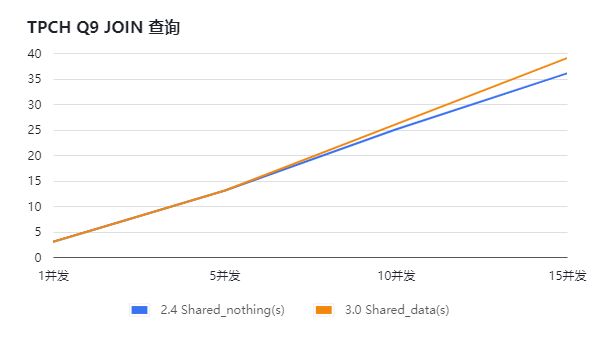
分别搭建StarRocks 2.4存算一体版本、StarRocks 3.0 存算分离版本,通过依次增加查询并发的方式,对SSB和TPCH进行压测,得到如下测试结果。通过下面的图表(横坐标为并发数,纵坐标为响应时长,单位s)可知:
针对单表查询场景, Shard_data的查询性能强于 Shard_nothing,此处可能跟2.4与3.0实现优化有关系;
针对关联查询场景,Shard_data的查询性能 与 Shard_nothing基本持平;
Shared_data 查询性能扩展能力
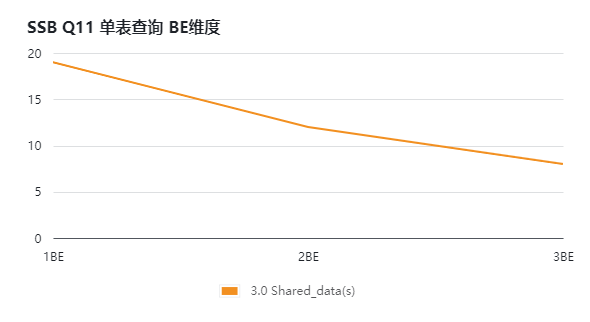
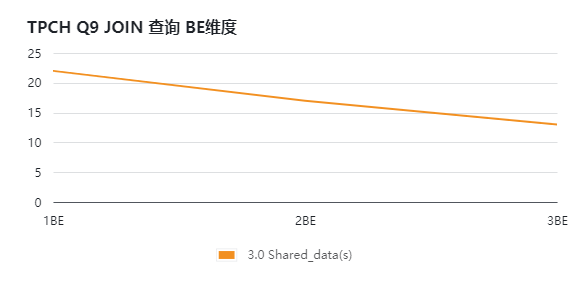
搭建StarRocks 3.0 存算分离版本,通过增加BE计算节点的方式,对SSB和TPCH进行压测,得到如下测试结果。通过下面的图表(横坐标为BE数量,纵坐标为响应时长,单位s)可知:
集群整体的查询能力随计算节点数增加而非线性的增加;
Shared_data 无cache VS 有cache
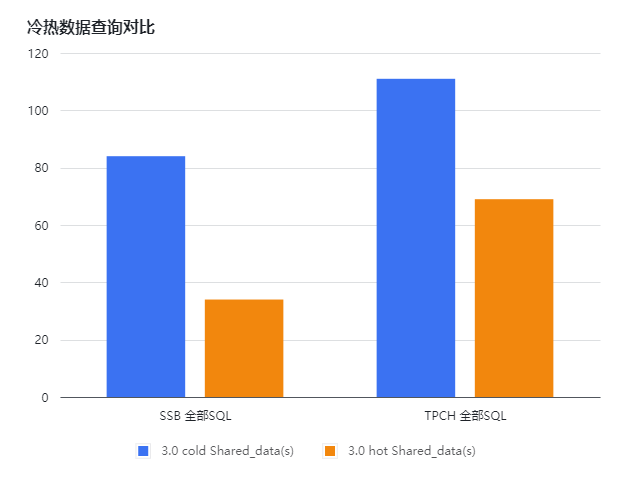
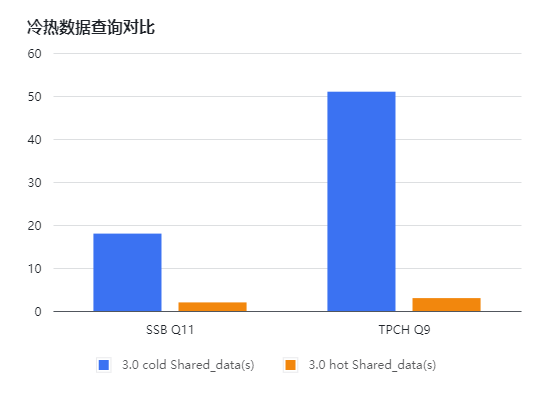
搭建StarRocks 3.0 存算分离版本,通过删除本地缓存的方式,对SSB和TPCH进行压测,得到如下测试结果。通过下面的图表(横坐标为有cache或无cache,纵坐标为响应时长,单位s)可知:
冷热数据(本地是否有磁盘 cache)SSB全部SQL有2.5倍左右的性能差距,TPCH全部SQL有1.5倍左右的性能差距;部分SQL (如SSB Q11、TPCH Q9) 有10倍的性能差距;
对冷数据的查询,可以根据具体业务场景通过analyze full table table_name 对缓存进行预热,StarRocks支持表级别的缓存预热;
六、总结
StarRocks 3.X 由于引入存算分离的架构,计算存储独立按需扩展,可以更加精细化的进行计算、存储资源成本控制。性能方面,在Local Cache命中的情况下,查询延时与存算一体架构持平。在后续StarRocks 3.x迭代更高版本,更加稳定之后,可以尝试替换现有存算一体的架构,提供成本更低,性能可弹的OLAP分析服务。