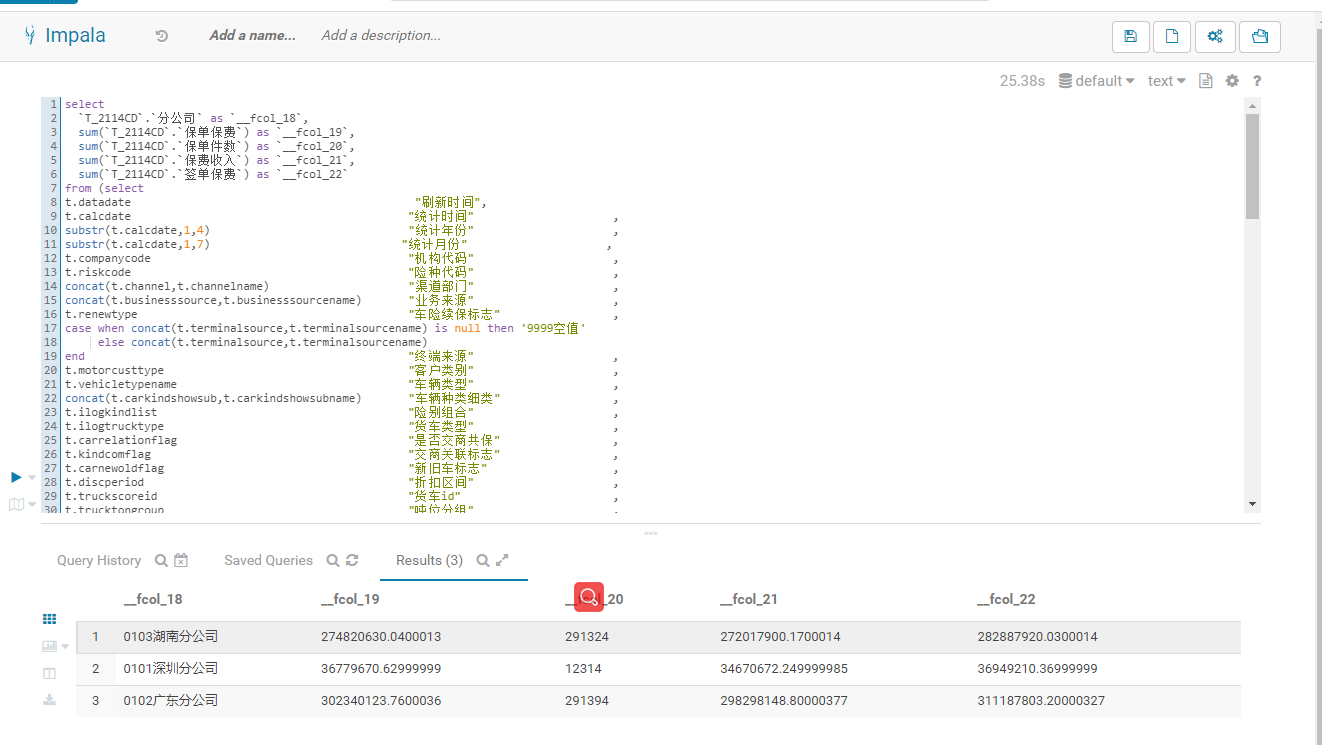
【详述】这段sql在impala上只要几秒钟,starrock却几分钟还没跑完
【业务影响】BI查询
【StarRocks版本】2.5.4
【集群规模】3fe(3 follower)+ 3be(fe与be混部)
【机器信息】80C/256G/万兆
【附件】
sql.sql (13.8 KB)

【详述】这段sql在impala上只要几秒钟,starrock却几分钟还没跑完
【业务影响】BI查询
【StarRocks版本】2.5.4
【集群规模】3fe(3 follower)+ 3be(fe与be混部)
【机器信息】80C/256G/万兆
【附件】
这个是impala的执行计划:
Max Per-Host Resource Reservation: Memory=11.69MB
Per-Host Resource Estimates: Memory=387.75MB
PLAN-ROOT SINK
|
22:EXCHANGE [UNPARTITIONED]
|
21:AGGREGATE [FINALIZE]
| output: sum:merge(T_2114CD.保单保费), sum:merge(T_2114CD.保单件数), sum:merge(T_2114CD.保费收入), sum:merge(T_2114CD.签单保费)
| group by: T_2114CD.分公司
|
20:EXCHANGE [HASH(T_2114CD.分公司)]
|
13:AGGREGATE [STREAMING]
| output: sum(t.incomeprem), sum(t.incomeply), sum(t.incomenetprem), sum(t.acceptnetprem)
| group by: t3.companycname
|
12:HASH JOIN [INNER JOIN, BROADCAST]
| hash predicates: t.companycode = t1.buiscomcode
| runtime filters: RF000 <- t1.buiscomcode
|
|–19:EXCHANGE [BROADCAST]
| |
| 09:NESTED LOOP JOIN [INNER JOIN, BROADCAST]
| | predicates: t1.companycode LIKE concat(substr(t2.core_company_code, 1, 6), ‘%’)
| |
| |–18:EXCHANGE [BROADCAST]
| | |
| | 08:SCAN HDFS [mv_report.ds_um_user_comp t2]
| | partitions=1/1 files=1 size=1.47MB
| | predicates: t2.user_code = ‘xuchuangyuan@sinosafe.com.cn’
| |
| 07:SCAN HDFS [mv_edw.dim_pub_company t1]
| partitions=1/1 files=1 size=171.57KB
| predicates: t1.companycname IN (‘0101深圳分公司’, ‘0102广东分公司’, ‘0103湖南分公司’)
|
11:HASH JOIN [INNER JOIN, BROADCAST]
| hash predicates: t.calcdate = a.day
| runtime filters: RF001 <- a.day
|
|–17:EXCHANGE [BROADCAST]
| |
| 10:SCAN HDFS [mv_edw.dim_pub_stat_totalday a]
| partitions=1/1 files=1 size=41.76KB
| predicates: concat(a.year, ‘年’) IN (‘2023年’)
|
06:NESTED LOOP JOIN [INNER JOIN, BROADCAST]
| predicates: t.companycode LIKE concat(t2.core_company_code, ‘%’)
|
|–16:EXCHANGE [BROADCAST]
| |
| 01:SCAN HDFS [mv_report.ds_um_user_comp t2]
| partitions=1/1 files=1 size=1.47MB
| predicates: t2.user_code = ‘xuchuangyuan@sinosafe.com.cn’
|
05:HASH JOIN [INNER JOIN, BROADCAST]
| hash predicates: t.riskcode = t4.riskcode
| runtime filters: RF002 <- t4.riskcode
|
|–15:EXCHANGE [BROADCAST]
| |
| 03:SCAN HDFS [mv_edw.dim_pub_risk t4]
| partitions=1/1 files=1 size=15.32KB
|
04:HASH JOIN [INNER JOIN, BROADCAST]
| hash predicates: t.companycode = t3.buiscomcode
| runtime filters: RF003 <- t3.buiscomcode
|
|–14:EXCHANGE [BROADCAST]
| |
| 02:SCAN HDFS [mv_edw.dim_pub_company t3]
| partitions=1/1 files=1 size=171.57KB
| runtime filters: RF000 -> t3.buiscomcode
|
00:SCAN HDFS [mv_report.dwa_stat_daily_policy_reform t]
partitions=1/1 files=200 size=2.18GB
runtime filters: RF000 -> t.companycode, RF001 -> t.calcdate, RF002 -> t.riskcode, RF003 -> t.companycode
impala这个有进行过滤字段的,导致扫描数据量比较小,执行效率快很多。
这个是StarRocks的执行计划:
PLAN FRAGMENT 0
OUTPUT EXPRS:67: companycname | 121: sum | 122: sum | 123: sum | 124: sum
PARTITION: UNPARTITIONED
RESULT SINK
29:EXCHANGE
limit: 400
PLAN FRAGMENT 1
OUTPUT EXPRS:
PARTITION: HASH_PARTITIONED: 67: companycname
STREAM DATA SINK
EXCHANGE ID: 29
UNPARTITIONED
28:AGGREGATE (merge finalize)
| output: sum(121: sum), sum(122: sum), sum(123: sum), sum(124: sum)
| group by: 67: companycname
| limit: 400
|
27:EXCHANGE
PLAN FRAGMENT 2
OUTPUT EXPRS:
PARTITION: HASH_PARTITIONED: 3: companycode, 4: riskcode, 3: companycode, 2: calcdate
STREAM DATA SINK
EXCHANGE ID: 27
HASH_PARTITIONED: 67: companycname
26:AGGREGATE (update serialize)
| STREAMING
| output: sum(41: incomeprem), sum(42: incomeply), sum(40: incomenetprem), sum(43: acceptnetprem)
| group by: 67: companycname
|
25:Project
| <slot 40> : 40: incomenetprem
| <slot 41> : 41: incomeprem
| <slot 42> : 42: incomeply
| <slot 43> : 43: acceptnetprem
| <slot 67> : 67: companycname
|
24:HASH JOIN
| join op: INNER JOIN (PARTITIONED)
| colocate: false, reason:
| equal join conjunct: 3: companycode = 72: buiscomcode
| equal join conjunct: 4: riskcode = 82: riskcode
| equal join conjunct: 3: companycode = 98: buiscomcode
| equal join conjunct: 2: calcdate = 117: day
| other predicates: 92: companycode LIKE concat(substr(108: core_company_code, 1, 6), ‘%’)
|
|----23:EXCHANGE
|
10:EXCHANGE
PLAN FRAGMENT 3
OUTPUT EXPRS:
PARTITION: RANDOM
STREAM DATA SINK
EXCHANGE ID: 23
HASH_PARTITIONED: 72: buiscomcode, 82: riskcode, 72: buiscomcode, 117: day
22:NESTLOOP JOIN
| join op: CROSS JOIN
| colocate: false, reason:
|
|----21:EXCHANGE
|
15:NESTLOOP JOIN
| join op: CROSS JOIN
| colocate: false, reason:
|
|----14:EXCHANGE
|
11:HdfsScanNode
TABLE: dim_pub_company
NON-PARTITION PREDICATES: 72: buiscomcode IS NOT NULL
partitions=1/1
cardinality=4089
avgRowSize=32.0
numNodes=0
PLAN FRAGMENT 4
OUTPUT EXPRS:
PARTITION: RANDOM
STREAM DATA SINK
EXCHANGE ID: 21
UNPARTITIONED
20:NESTLOOP JOIN
| join op: CROSS JOIN
| colocate: false, reason:
|
|----19:EXCHANGE
|
17:Project
| <slot 117> : 117: day
|
16:HdfsScanNode
TABLE: dim_pub_stat_totalday
NON-PARTITION PREDICATES: 117: day IS NOT NULL, concat(115: year, ‘年’) = ‘2023年’
partitions=1/1
cardinality=9976
avgRowSize=32.0
numNodes=0
PLAN FRAGMENT 5
OUTPUT EXPRS:
PARTITION: RANDOM
STREAM DATA SINK
EXCHANGE ID: 19
UNPARTITIONED
18:HdfsScanNode
TABLE: dim_pub_risk
NON-PARTITION PREDICATES: 82: riskcode IS NOT NULL
partitions=1/1
cardinality=532
avgRowSize=16.0
numNodes=0
PLAN FRAGMENT 6
OUTPUT EXPRS:
PARTITION: RANDOM
STREAM DATA SINK
EXCHANGE ID: 14
UNPARTITIONED
13:Project
| <slot 92> : 92: companycode
| <slot 98> : 98: buiscomcode
|
12:HdfsScanNode
TABLE: dim_pub_company
NON-PARTITION PREDICATES: 98: buiscomcode IS NOT NULL, 93: companycname IN (‘0101深圳分公司’, ‘0102广东分公司’, ‘0103湖南分公司’)
MIN/MAX PREDICATES: 127: companycname >= ‘0101深圳分公司’, 128: companycname <= ‘0103湖南分公司’
partitions=1/1
cardinality=4089
avgRowSize=48.0
numNodes=0
PLAN FRAGMENT 7
OUTPUT EXPRS:
PARTITION: RANDOM
STREAM DATA SINK
EXCHANGE ID: 10
HASH_PARTITIONED: 3: companycode, 4: riskcode, 3: companycode, 2: calcdate
9:Project
| <slot 2> : 2: calcdate
| <slot 3> : 3: companycode
| <slot 4> : 4: riskcode
| <slot 40> : 40: incomenetprem
| <slot 41> : 41: incomeprem
| <slot 42> : 42: incomeply
| <slot 43> : 43: acceptnetprem
| <slot 108> : 108: core_company_code
|
8:NESTLOOP JOIN
| join op: CROSS JOIN
| colocate: false, reason:
| other predicates: 3: companycode LIKE concat(60: core_company_code, ‘%’)
|
|----7:EXCHANGE
|
5:NESTLOOP JOIN
| join op: CROSS JOIN
| colocate: false, reason:
|
|----4:EXCHANGE
|
1:Project
| <slot 60> : 60: core_company_code
|
0:HdfsScanNode
TABLE: ds_um_user_comp
NON-PARTITION PREDICATES: 57: user_code = ‘xuchuangyuan@sinosafe.com.cn’
MIN/MAX PREDICATES: 129: user_code <= ‘xuchuangyuan@sinosafe.com.cn’, 130: user_code >= ‘xuchuangyuan@sinosafe.com.cn’
partitions=1/1
cardinality=22604
avgRowSize=32.0
numNodes=0
PLAN FRAGMENT 8
OUTPUT EXPRS:
PARTITION: RANDOM
STREAM DATA SINK
EXCHANGE ID: 07
UNPARTITIONED
6:HdfsScanNode
TABLE: dwa_stat_daily_policy_reform
NON-PARTITION PREDICATES: 2: calcdate IS NOT NULL, 4: riskcode IS NOT NULL
partitions=1/1
cardinality=56485781
avgRowSize=80.0
numNodes=0
PLAN FRAGMENT 9
OUTPUT EXPRS:
PARTITION: RANDOM
STREAM DATA SINK
EXCHANGE ID: 04
UNPARTITIONED
3:Project
| <slot 108> : 108: core_company_code
|
2:HdfsScanNode
TABLE: ds_um_user_comp
NON-PARTITION PREDICATES: 105: user_code = ‘xuchuangyuan@sinosafe.com.cn’
MIN/MAX PREDICATES: 125: user_code <= ‘xuchuangyuan@sinosafe.com.cn’, 126: user_code >= ‘xuchuangyuan@sinosafe.com.cn’
partitions=1/1
cardinality=22604
avgRowSize=32.0
numNodes=0
StarRocks这个执行计划比较长,开头没有进行过滤,导致扫描到的数据量比较大,所以执行起来慢很多。现在都是查询SR的hive外部表,麻烦大佬看一下怎么解决这个问题呢,在线等,急。。。
我也存在这个问题,3.0版本,和 trino 一起读取同一张表做count 操作,结果发现比trino 不知慢多少倍不止
外部表查询不行,网络带宽和机械磁盘性能严重拉低了下限。
这个原因当前定位到了,应该是NestLoopJoin的原因,后面的小版本会优化下。