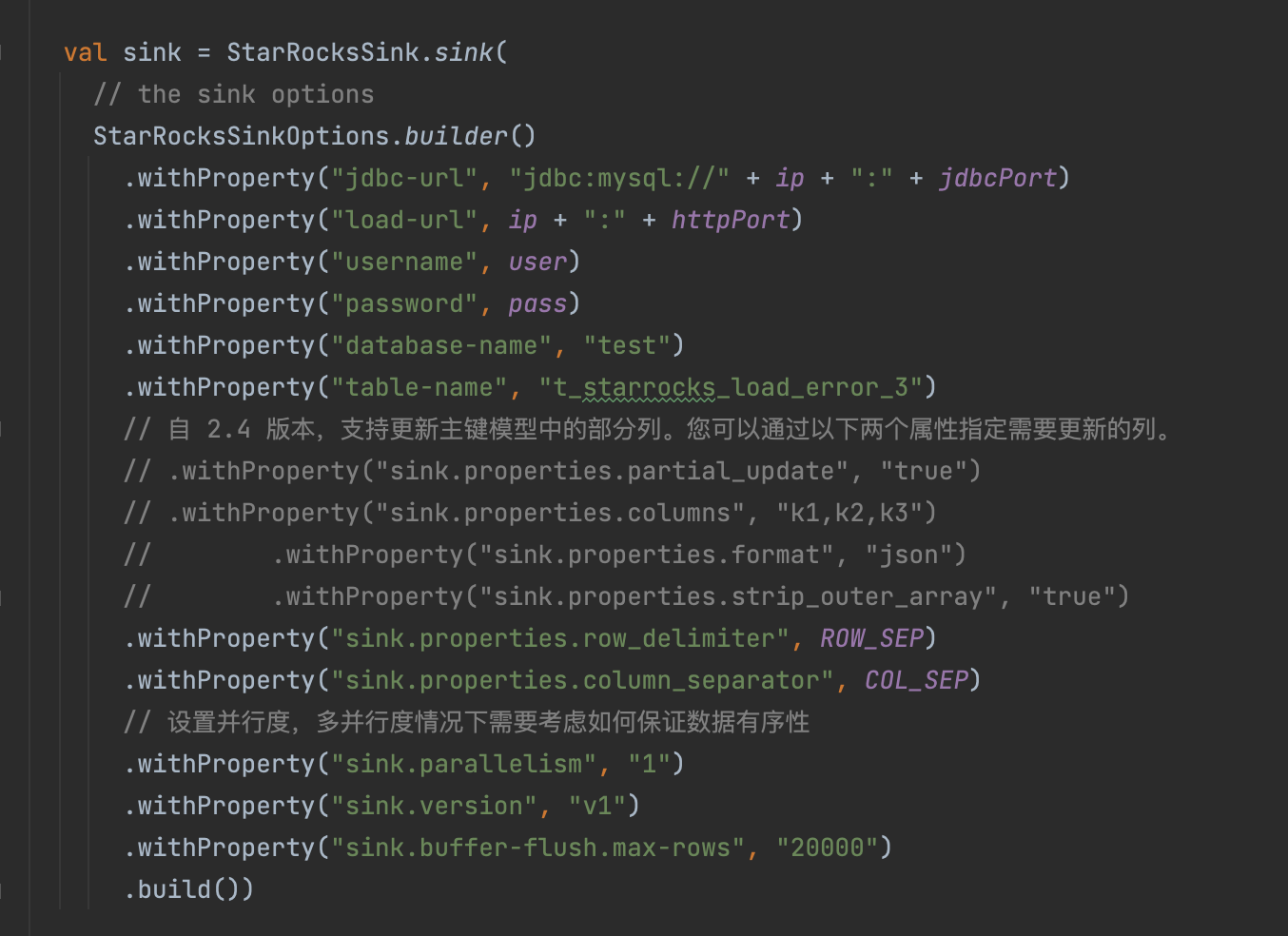
【详述】 Java 查询 MySQL,再使用 Streamload 的方式往 Starrocks 写数据,每批次写几万条数据,经常遇到 19998 条成功, 1 条失败(不管导入多少条数据,都是有一条数据失败) Error: Value count does not match column count. Expect 35, but got 69 的报错,实际上这是 2 条数据,并且行分隔符在 报错信息中可以看到
测试步骤:
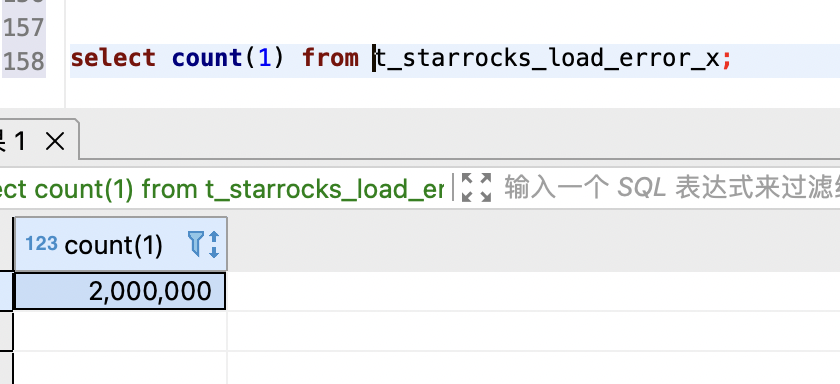
1、准备一张 200 万数据的表
2、创建三张和源表一个字段的表,分别是唯一、主键、明细模型(表结构见文后)
3、一个 Java 程序,读取这 200 万数据,以 streamload 的方式往 步骤2 创建的表写入数据,设定一个批次导入 2 万条数据,反复执行
测试结果:
三种模型下,都会随机的触发该问题
错误数据也是随机,但都是导入的一个批次中,有一条错误
一个批次导入数据量越大,越容易出现问题
【背景】Java 读取数据库数据,streamload 写入 Starrocks
【业务影响】
【StarRocks版本】2.4.3/2.5.3
【集群规模】5fe(3 follower+2observer)+6be(独立部署)
【机器信息】16c 64G
【表模型】唯一、主键、明细模型均有此问题
【导入或者导出方式】 streamload
【联系方式】社区6群-春江
【附件】
streamload 返回信息:
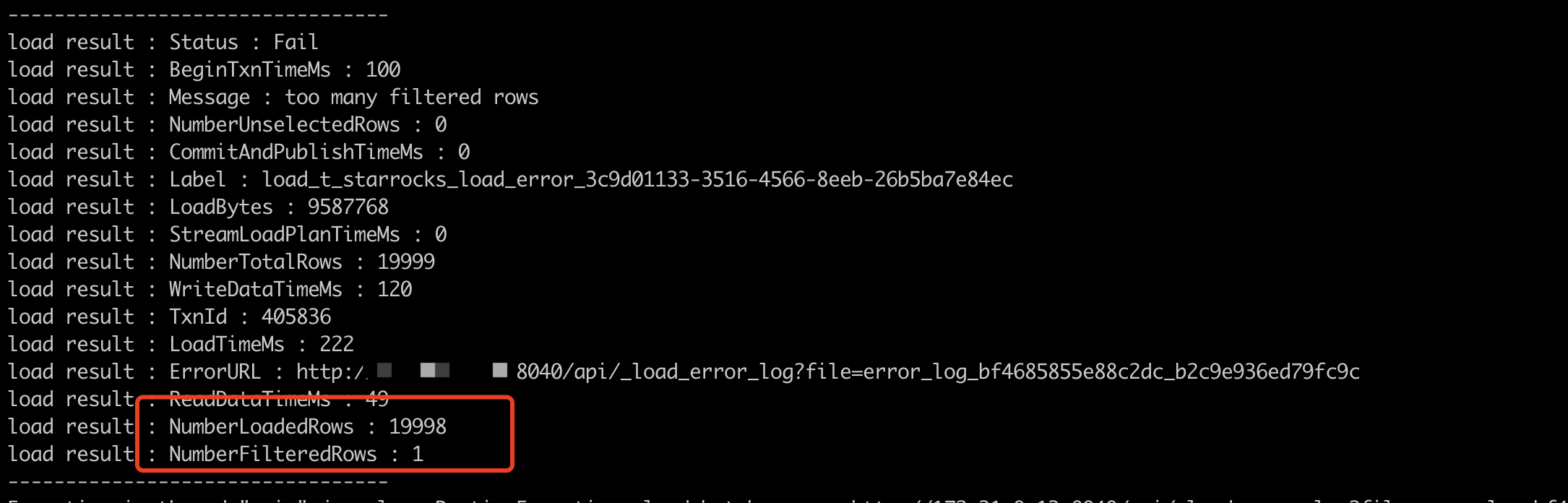
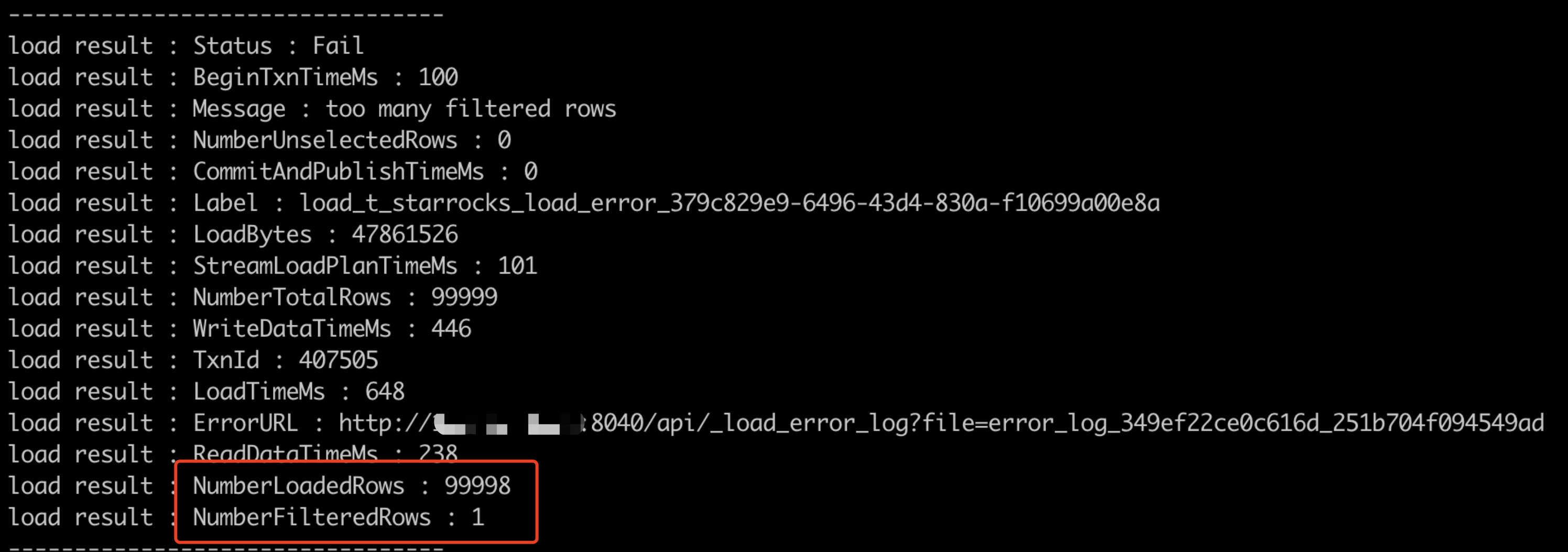
报错信息:


源表、目标表表结构(主键、唯一、明细三种模型都一样)
CREATE TABLE t_starrocks_load_error_3 (
`id` bigint(20) ,
`reversion` int(11) ,
`is_deleted` tinyint(4) ,
`created_by` varchar(65533) ,
`created_time` datetime ,
`updated_by` varchar(65533) ,
`updated_time` datetime ,
`member_id` bigint(20) ,
`member_name` varchar(65533) ,
`change_type` int(11) ,
`before_point` int(11) ,
`change_point` int(11) ,
`now_point` int(11) ,
`effective_time` datetime ,
`expire_time` datetime ,
`expire_notice_time` datetime ,
`remark` varchar(65533) ,
`from_type` smallint(6) ,
`from_point_id` bigint(20) ,
`from_point_name` varchar(65533) ,
`status` int(11) ,
`point_item_id` bigint(20) ,
`expire_notice_status` int(11) ,
`cac_id` varchar(65533) ,
`operator_log_id` bigint(20) ,
`change_notice_status` int(11) ,
`change_notice_time` datetime ,
`in_out` bigint(20) ,
`use_num` int(11) ,
`expire_num` int(11) ,
`bz_id` varchar(65533) ,
`rule_class_code` varchar(65533) ,
`rule_code` varchar(65533) ,
`member_code` varchar(65533) ,
`mobile` varchar(65533)
)
duplicate KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES (
"replication_num" = "3",
"in_memory" = "false",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "true",
"compression" = "LZ4"
);