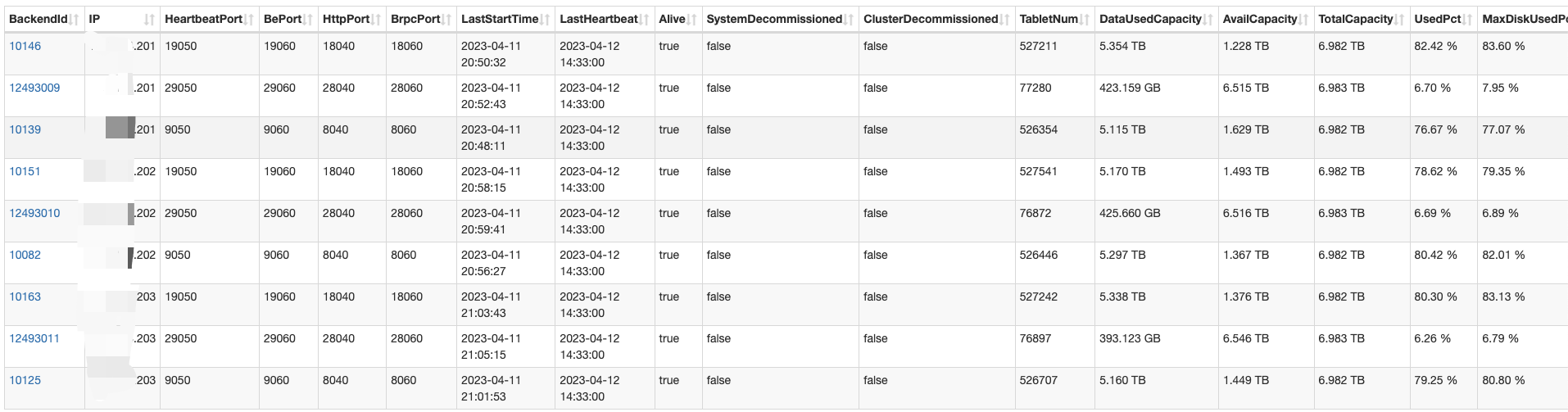
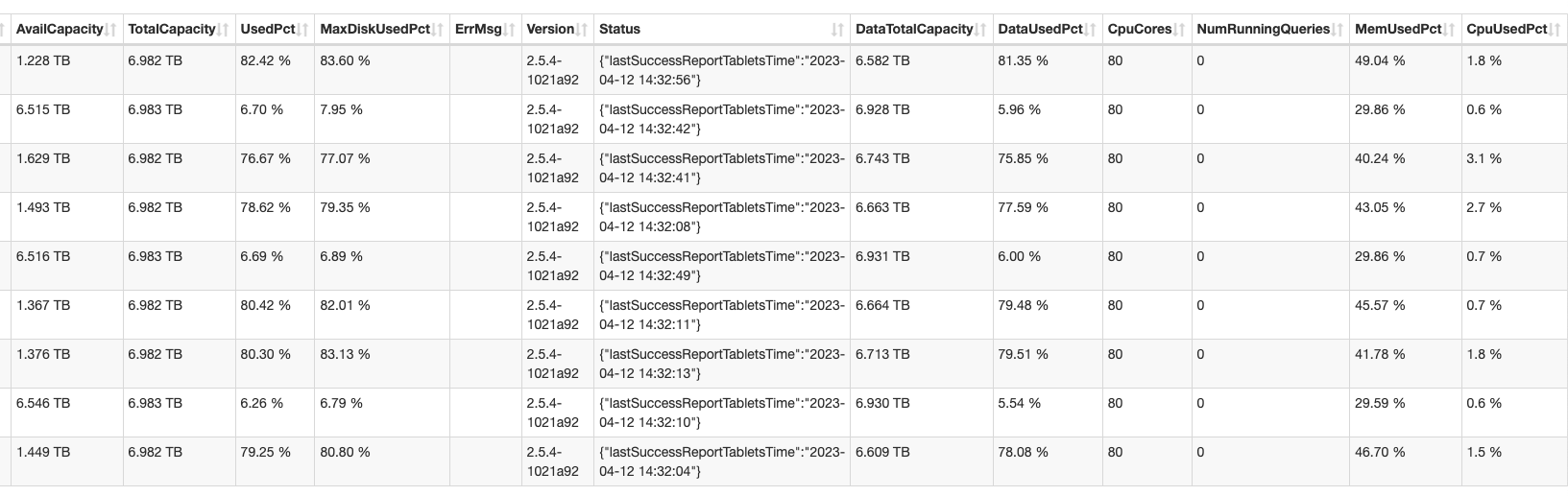
【详述】集群在2.2.11期间做了扩容,由三台4路物理机,利用numa,每台物理当做三个节点,1FE+2BE,一共3FE、6BE,扩容到1FE+3BE,一共3FE、9BE,也就说物理机没变,每台物理机上各扩容了一个be节点,然后负载均衡没有起作用,旧的6个BE磁盘占用一直在85%以上,新的磁盘占用一直在10%以下,最近升级了2.5.4,集群负载也没有任何变化。
【背景】扩容了BE节点
【业务影响】磁盘负载不均衡
【StarRocks版本】2.5.4
【集群规模】三台4路物理机,利用numa,每台物理当做四个节点,1FE+3BE,一共3FE、9BE
【机器信息】48C 512G 4T8
【联系方式】社区群1-数据小黑
集群的调度状态:

max_scheduling_tablets = 2000
max_balancing_tablets = 2000
缺什么资料我再补充