【详述】问题详细描述
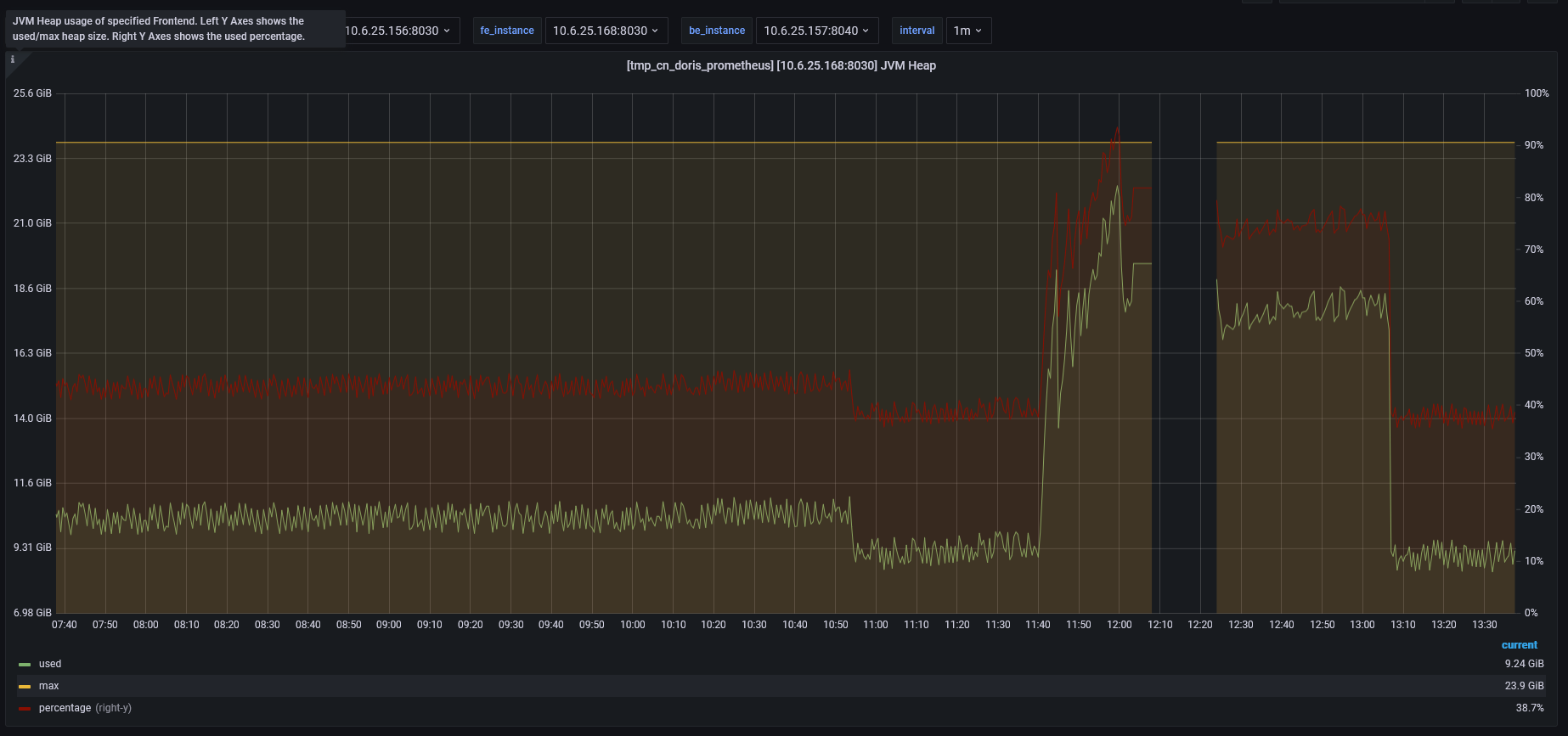
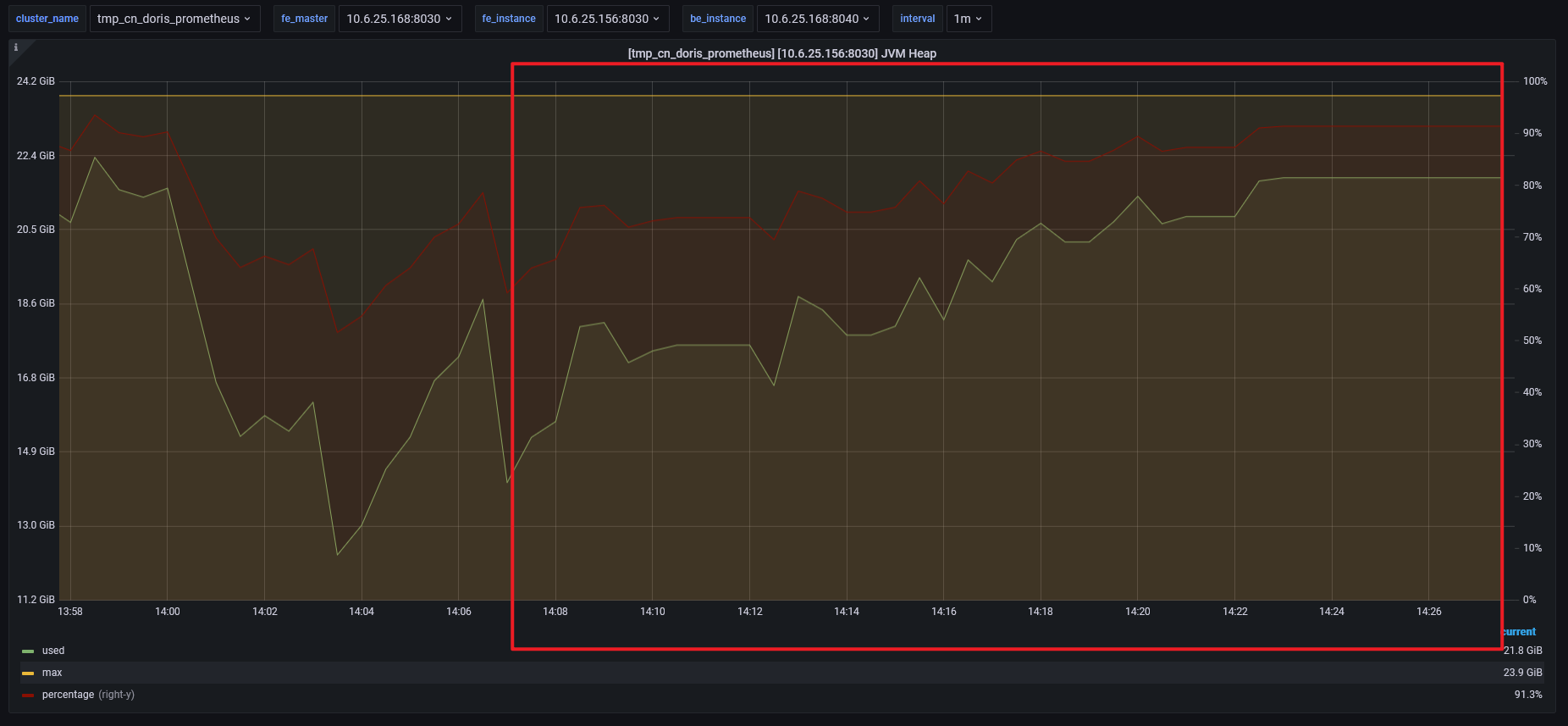
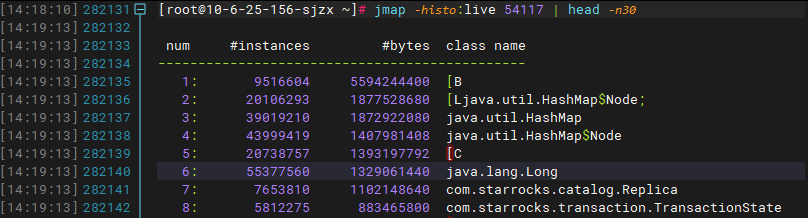
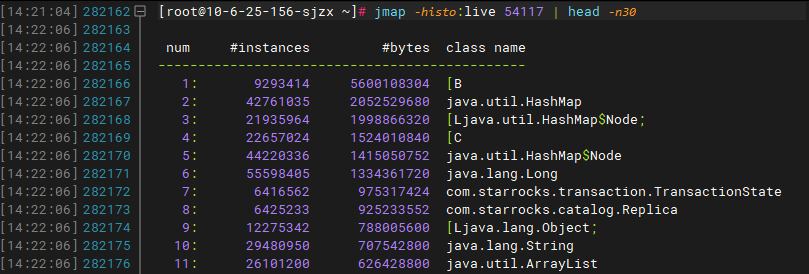
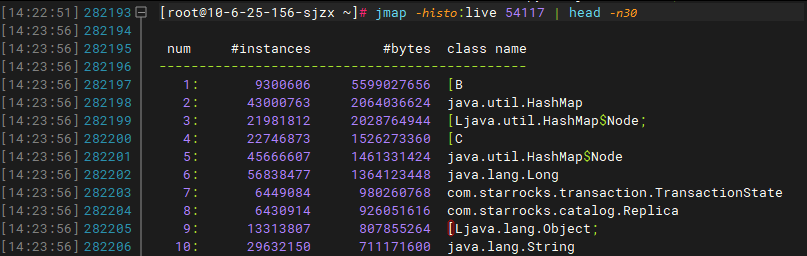
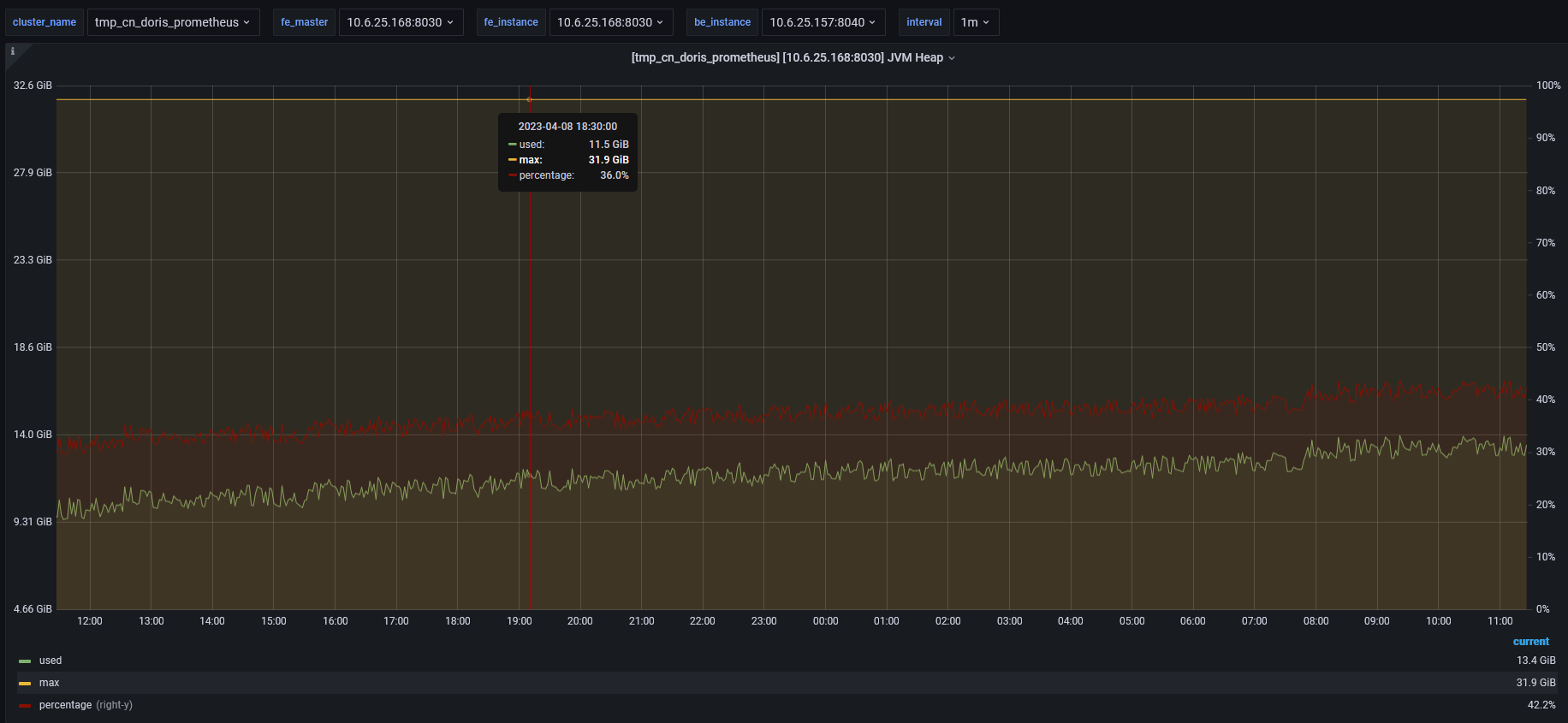
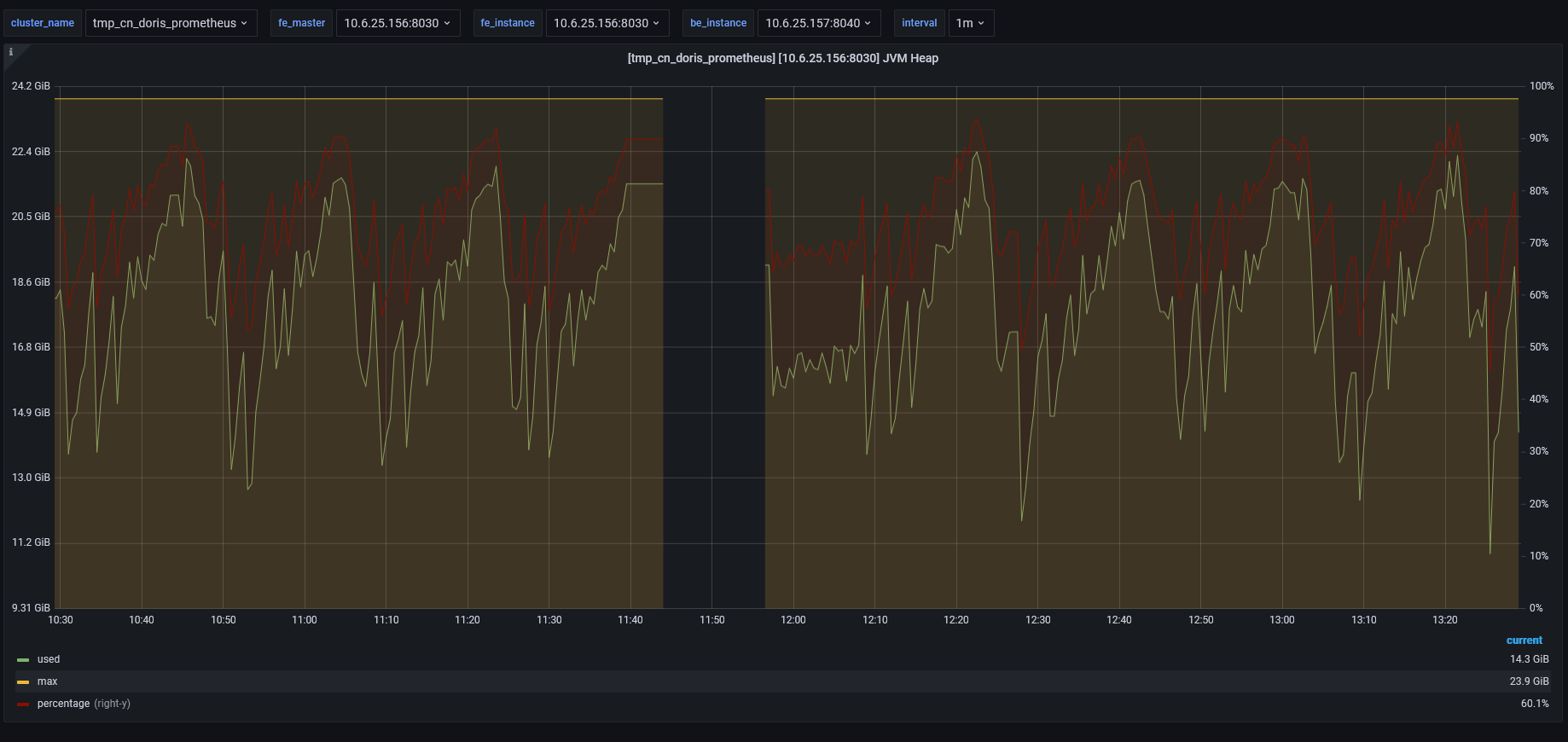
FE的leader服务,内存占用极高,总内存24G,峰值达到90%,频繁出现FE leader进程挂掉重启。
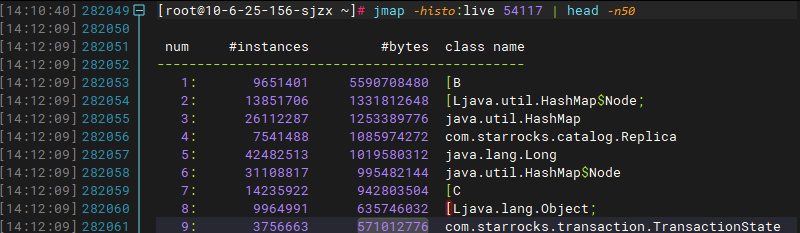
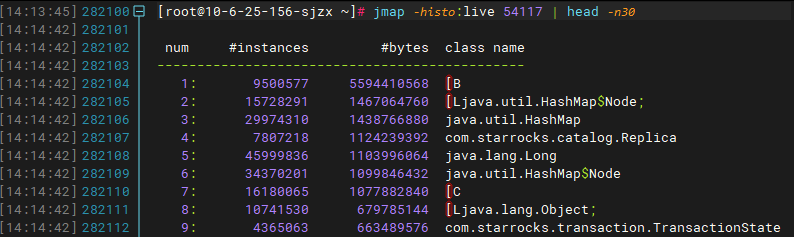
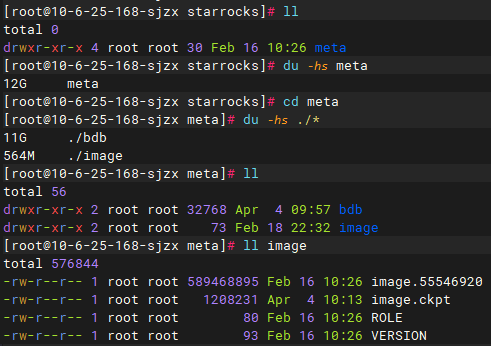
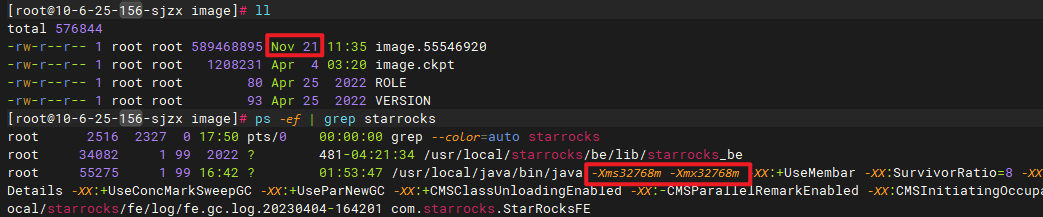
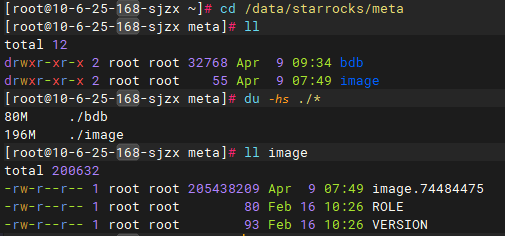
观察fe.log日志,每次重启后都会有大量的replay transaction的日志,而且有很多历史事务的日志,如2022年11月21日的日志提交完成记录。
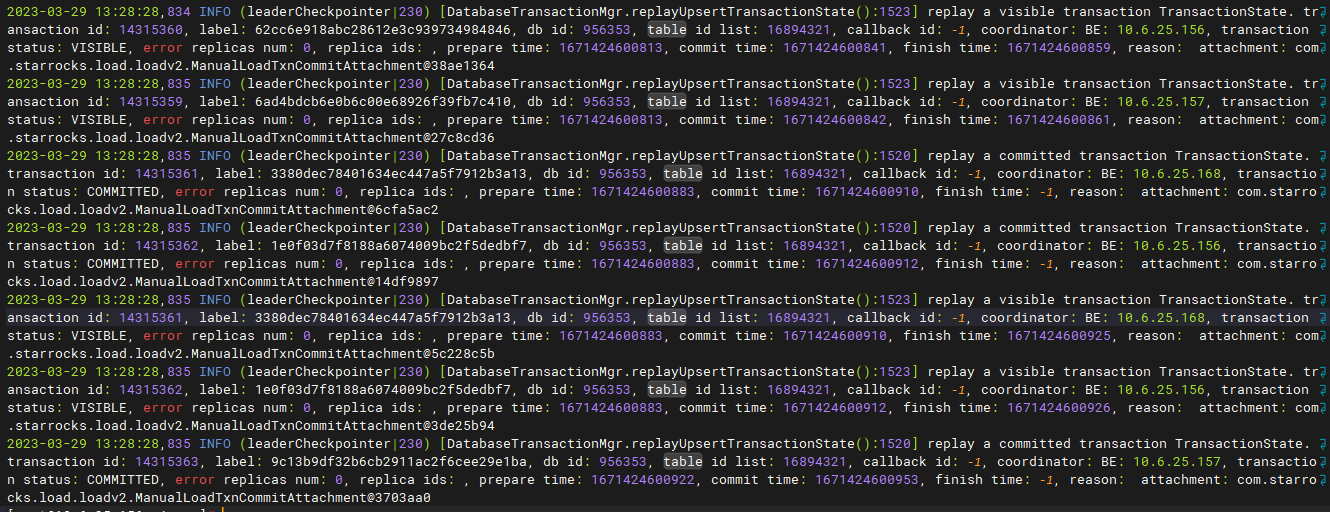

我这里统计日志文件打印出来的最早的事务提交日志时间是如下:
1669001433189——2022-11-21 11:30:34
【背景】做过哪些操作?
【业务影响】
会造成FE的leader服务频繁挂掉
【StarRocks版本】
2.0.9
【集群规模】
3fe+3be(fe与be混部)
【机器信息】
24C/62G/千兆
【联系方式】
社区群5-不惑
邮箱:zxdtony@126.com
【附件】
leader的fe jvm head
follower的fe jvm head
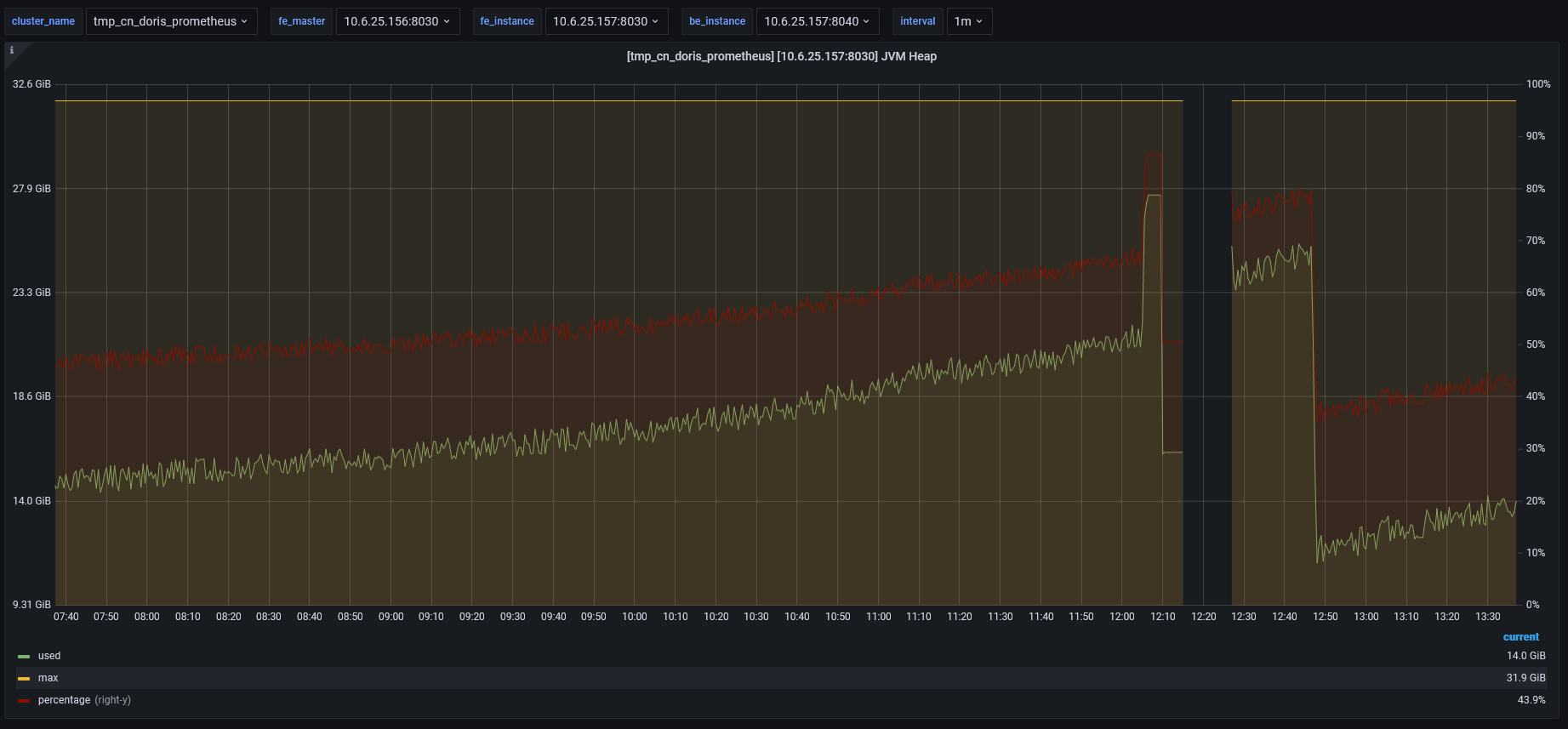
follower的fe jvm head